이 가이드는 여러 개의 GPU가 있는 머신에 직접 엑세스할 수 있는 사용자를 대상으로 합니다. 클라우드 머신을 대여하는 사용자를 위한 가이드가 아닙니다.클라우드 머신에서 minikube 클러스터를 설정하려는 경우, W&B는 해당 클라우드 제공업체를 사용하여 GPU 지원 기능이 있는 Kubernetes 클러스터를 생성할 것을 권장합니다. 예를 들어, AWS, Google Cloud, Azure, Coreweave 및 기타 클라우드 제공업체는 GPU 지원 Kubernetes 클러스터를 생성하는 툴을 제공합니다.단일 GPU가 있는 머신에서 GPU 스케줄링을 위한 minikube 클러스터를 설정하려는 경우, W&B는 Launch Docker queue를 사용할 것을 권장합니다. 재미 삼아 이 가이드를 따라 하실 수는 있지만, GPU 스케줄링이 큰 효용이 없을 것입니다.
배경
NVIDIA container toolkit 덕분에 Docker에서 GPU 기반 워크플로우를 쉽게 실행할 수 있게 되었습니다. 한 가지 제한 사항은 볼륨별 GPU 스케줄링에 대한 네이티브 지원이 부족하다는 점입니다.docker run 코맨드로 GPU를 사용하려면 ID별로 특정 GPU를 요청하거나 존재하는 모든 GPU를 요청해야 하므로, 많은 분산 GPU 기반 워크로드를 처리하기에는 비실용적입니다. Kubernetes는 볼륨 요청에 따른 스케줄링을 지원하지만, 최근까지 GPU 스케줄링 기능이 있는 로컬 Kubernetes 클러스터를 설정하는 데는 상당한 시간과 노력이 필요했습니다. 단일 노드 Kubernetes 클러스터를 실행하는 데 가장 인기 있는 툴 중 하나인 Minikube는 최근 GPU 스케줄링 지원 기능을 출시했습니다. 이 가이드에서는 멀티 GPU 머신에 Minikube 클러스터를 생성하고 W&B Launch를 사용하여 클러스터에 동시 Stable Diffusion 추론 작업을 런칭해 보겠습니다.
사전 요구 사항
시작하기 전에 다음 사항이 필요합니다:- W&B 계정.
- 다음이 설치되고 실행 중인 Linux 머신:
- Docker 런타임
- 사용하려는 모든 GPU의 드라이버
- Nvidia container toolkit
이 가이드를 테스트하고 작성하기 위해 4개의 NVIDIA Tesla T4 GPU가 연결된 Google Cloud Compute Engine
n1-standard-16 인스턴스를 사용했습니다.Launch 작업을 위한 큐 생성
먼저, Launch 작업을 위한 launch 큐를 생성합니다.- wandb.ai/launch로 이동합니다 (프라이빗 W&B 서버를 사용하는 경우
<your-wandb-url>/launch). - 화면 오른쪽 상단에서 파란색 Create a queue 버튼을 클릭합니다. 화면 오른쪽에서 큐 생성 드로어가 나타납니다.
- Entity를 선택하고, 이름을 입력한 다음, 큐 유형으로 Kubernetes를 선택합니다.
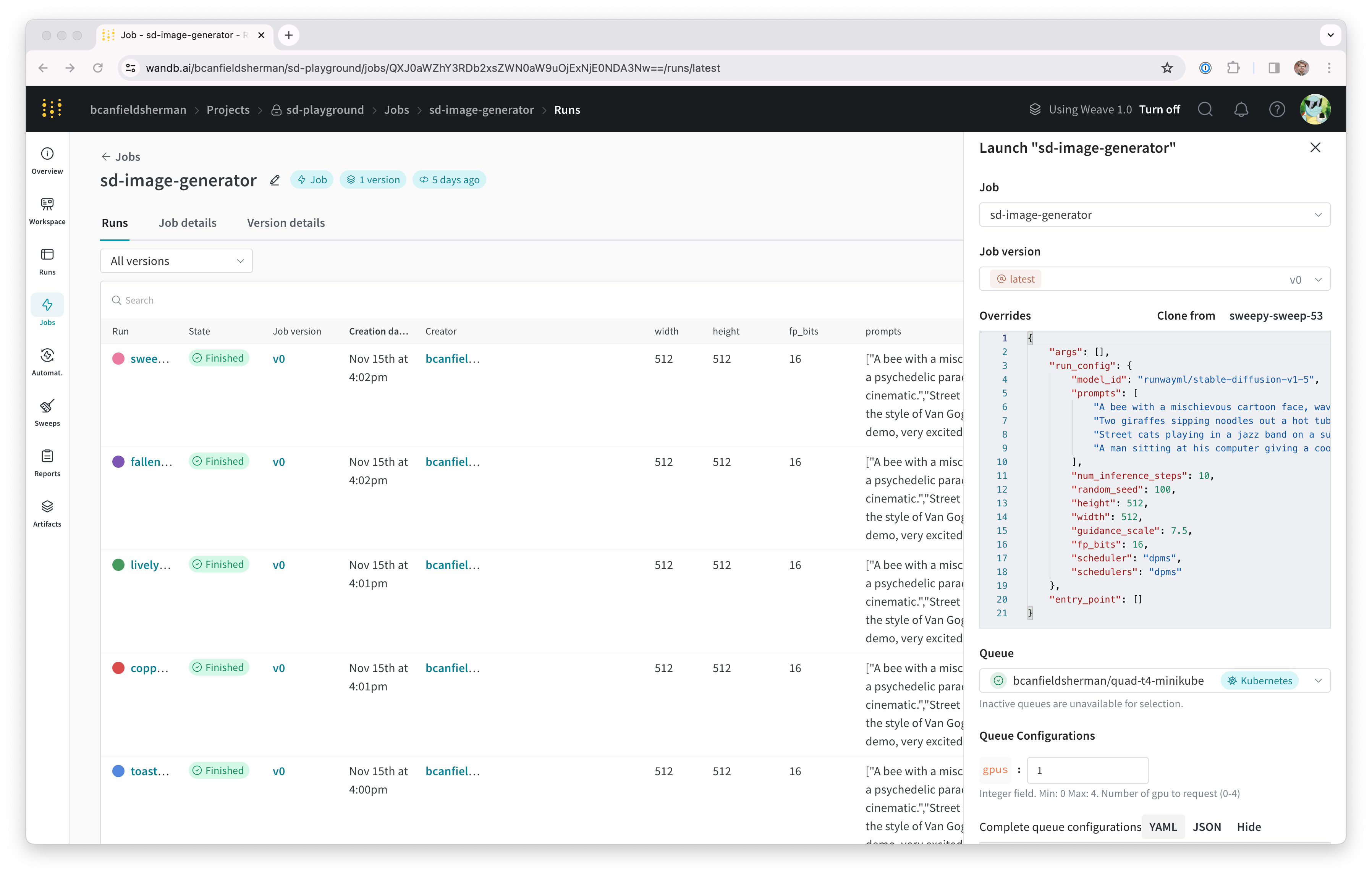
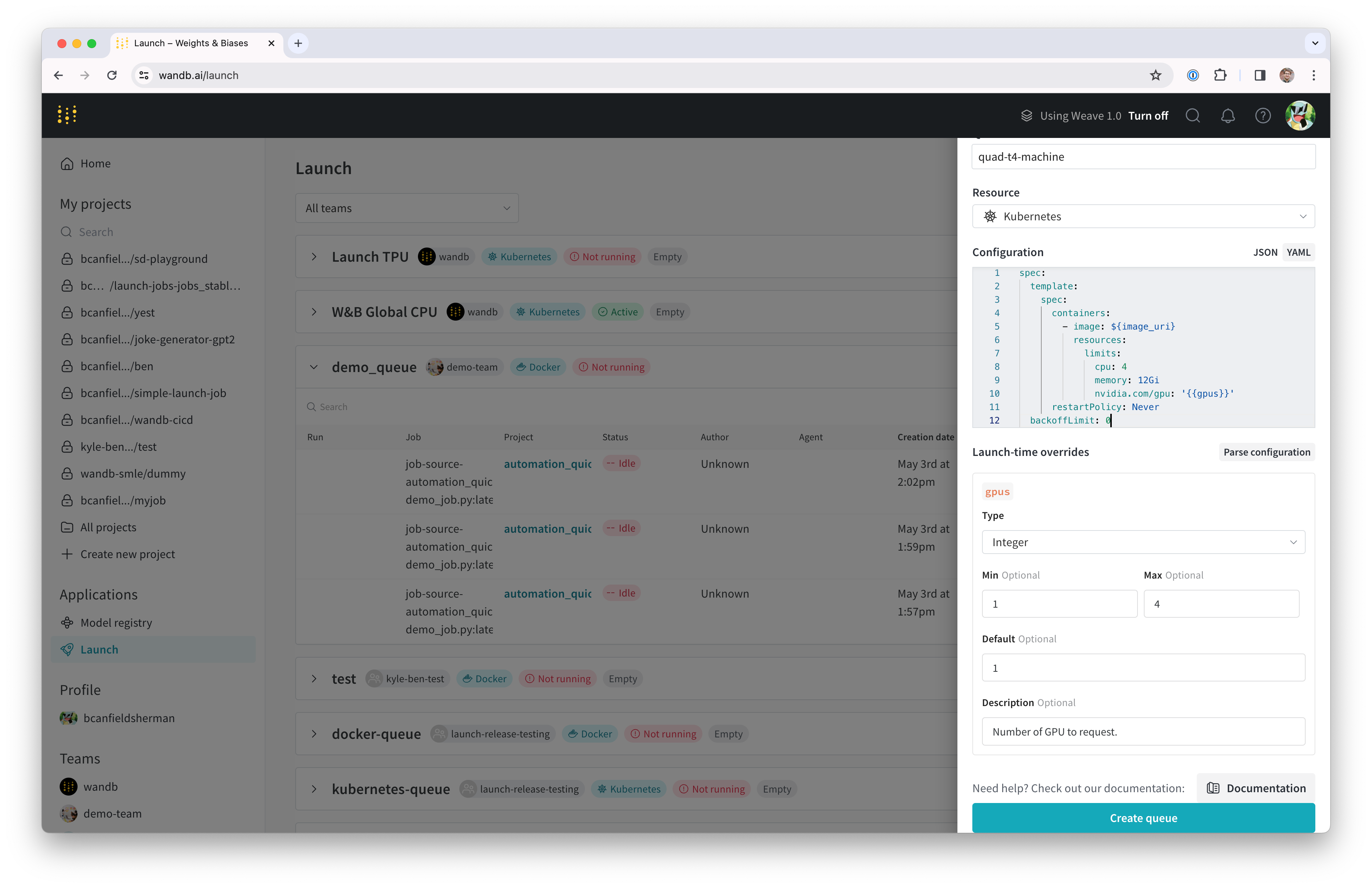
- 드로어의 Config 섹션은 launch 큐를 위한 Kubernetes job specification을 입력하는 곳입니다. 이 큐에서 실행되는 모든 Runs는 이 작업 사양을 사용하여 생성되므로, 필요에 따라 이 설정을 수정하여 작업을 커스터마이징할 수 있습니다. 이 가이드에서는 아래의 샘플 설정을 YAML 또는 JSON 형식으로 큐 설정에 복사하여 붙여넣으세요:
- YAML
- JSON
${image_uri} 및 {{gpus}} 문자열은 큐 설정에서 사용할 수 있는 두 가지 종류의 변수 템플릿 예시입니다. ${image_uri} 템플릿은 에이전트에 의해 실행되는 작업의 이미지 URI로 대체됩니다. {{gpus}} 템플릿은 작업을 제출할 때 Launch UI, CLI 또는 SDK에서 오버라이드할 수 있는 템플릿 변수를 생성하는 데 사용됩니다. 이 값들은 작업 사양에 배치되어 작업에 사용되는 이미지와 GPU 리소스를 제어하는 올바른 필드를 수정하게 됩니다.
- Parse configuration 버튼을 클릭하여
gpus템플릿 변수 커스터마이징을 시작합니다. - Type을
Integer로 설정하고 Default, Min, Max를 원하는 값으로 설정합니다. 템플릿 변수의 제약 조건을 위반하여 이 큐에 run을 제출하려는 시도는 거부됩니다.
- Create queue를 클릭하여 큐를 생성합니다. 새로 생성된 큐의 큐 페이지로 리다이렉트됩니다.
Docker + NVIDIA CTK 설정
머신에 이미 Docker와 Nvidia container toolkit이 설정되어 있다면 이 섹션은 건너뛰어도 됩니다. 시스템에 Docker 컨테이너 엔진을 설정하는 방법은 Docker 문서를 참조하세요. Docker가 설치되면 Nvidia 문서의 안내에 따라 Nvidia container toolkit을 설치합니다. 컨테이너 런타임이 GPU에 엑세스할 수 있는지 확인하려면 다음을 실행하세요:nvidia-smi 출력이 표시되어야 합니다. 예를 들어, 저희의 설정에서는 다음과 같은 출력이 나타납니다:
Minikube 설정
Minikube의 GPU 지원에는v1.32.0 이상의 버전이 필요합니다. 최신 설치 도움말은 Minikube 설치 문서를 참조하세요. 이 가이드에서는 다음 코맨드를 사용하여 최신 Minikube 릴리스를 설치했습니다:
Launch 에이전트 시작
새 클러스터를 위한 launch 에이전트는wandb launch-agent를 직접 호출하거나 W&B에서 관리하는 helm chart를 사용하여 배포함으로써 시작할 수 있습니다.
이 가이드에서는 호스트 머신에서 직접 에이전트를 실행합니다.
컨테이너 외부에서 에이전트를 실행한다는 것은 로컬 Docker 호스트를 사용하여 클러스터에서 실행할 이미지를 빌드할 수 있음을 의미하기도 합니다.
wandb login을 실행하거나 WANDB_API_KEY 환경 변수를 설정하세요.
에이전트를 시작하려면 다음 코맨드를 실행하세요:
작업 Launch 하기
에이전트에게 작업을 보내보겠습니다. W&B 계정에 로그인된 터미널에서 다음으로 간단한 “hello world”를 실행할 수 있습니다:(선택 사항) NFS를 이용한 모델 및 데이터 캐싱
ML 워크로드에서는 여러 작업이 동일한 데이터에 엑세스해야 하는 경우가 많습니다. 예를 들어, 데이터셋이나 모델 가중치와 같은 대용량 에셋을 반복적으로 다운로드하는 것을 피하기 위해 공유 캐시를 원할 수 있습니다. Kubernetes는 persistent volumes 및 persistent volume claims를 통해 이를 지원합니다. Persistent volumes를 사용하여 Kubernetes 워크로드에volumeMounts를 생성하고 공유 캐시에 대한 직접적인 파일 시스템 엑세스를 제공할 수 있습니다.
이 단계에서는 모델 가중치를 위한 공유 캐시로 사용할 수 있는 NFS(Network File System) 서버를 설정합니다. 첫 번째 단계는 NFS를 설치하고 설정하는 것입니다. 이 프로세스는 운영 체제에 따라 다릅니다. VM이 Ubuntu를 실행 중이므로 nfs-kernel-server를 설치하고 /srv/nfs/kubedata에 export를 설정했습니다:
nfs-persistent-volume.yaml이라는 파일에 복사하고, 원하는 볼륨 용량과 클레임 요청을 입력하세요. PersistentVolume.spec.capcity.storage 필드는 기본 볼륨의 최대 크기를 제어합니다. PersistentVolumeClaim.spec.resources.requests.stroage는 특정 클레임에 할당된 볼륨 용량을 제한하는 데 사용할 수 있습니다. 여기서는 두 필드에 동일한 값을 사용하는 것이 합리적입니다.
volumes와 volumeMounts를 추가해야 합니다. launch 설정을 편집하려면 wandb.ai/launch로 돌아가(또는 wandb 서버 사용자의 경우 <your-wandb-url>/launch), 큐를 찾아 큐 페이지로 이동한 다음 Edit config 탭을 클릭합니다. 원본 설정을 다음과 같이 수정할 수 있습니다:
- YAML
- JSON
/root/.cache에 NFS가 마운트됩니다. 컨테이너가 root 이외의 사용자로 실행되는 경우 마운트 경로를 조정해야 합니다. Huggingface 라이브러리와 W&B Artifacts 모두 기본적으로 $HOME/.cache/를 사용하므로 다운로드는 한 번만 발생하게 됩니다.
Stable Diffusion 실습
새로운 시스템을 테스트하기 위해 Stable Diffusion의 추론 파라미터를 실험해 보겠습니다. 기본 프롬프트와 합리적인 파라미터로 간단한 Stable Diffusion 추론 작업을 실행하려면 다음을 수행하세요:wandb/job_stable_diffusion_inference:main 컨테이너 이미지를 큐에 제출합니다.
에이전트가 작업을 선택하고 클러스터에서 실행되도록 스케줄링하면, 연결 상태에 따라 이미지를 가져오는 데 시간이 걸릴 수 있습니다.
wandb.ai/launch의 큐 페이지에서 작업 상태를 확인할 수 있습니다.
Run이 완료되면 지정한 프로젝트에 작업 아티팩트가 생성됩니다.
프로젝트의 작업 페이지(<project-url>/jobs)에서 작업 아티팩트를 확인할 수 있습니다. 기본 이름은 job-wandb_job_stable_diffusion_inference이지만, 작업 페이지에서 작업 이름 옆의 연필 아이콘을 클릭하여 원하는 이름으로 변경할 수 있습니다.
이제 이 작업을 사용하여 클러스터에서 더 많은 Stable Diffusion 추론을 실행할 수 있습니다.
작업 페이지의 오른쪽 상단에 있는 Launch 버튼을 클릭하여 새로운 추론 작업을 설정하고 큐에 제출할 수 있습니다. 작업 설정 페이지에는 원래 실행의 파라미터가 미리 채워져 있지만, launch 드로어의 Overrides 섹션에서 값을 수정하여 원하는 대로 변경할 수 있습니다.