機械学習ワークフローにおけるモデルのアーティファクトを追跡、共有、管理するために、いつ、どのように W&B を使用するかを学びます。このページでは、各タスクに適した W&B API を使用して、実験のログ記録、レポートの作成、およびログ記録されたデータへのアクセス方法について説明します。
このチュートリアルでは以下を使用します:
サインアップと API キーの作成
マシンを W&B で認証するには、まず wandb.ai/settings で APIキー を生成する必要があります。APIキー をコピーし、安全に保管してください。
パッケージのインストールとインポート
W&B ライブラリと、このウォークスルーで必要となる他のいくつかのパッケージをインストールします。
W&B Python SDK をインポートします:
以下のコードブロックで、あなたのチームの entity を指定してください:
TEAM_ENTITY = "<Team_Entity>" # あなたのチームの entity に置き換えてください
PROJECT = "my-awesome-project"
モデルのトレーニング
以下のコードは、モデルのトレーニング、メトリクスのログ記録、およびモデルを Artifacts として保存するという、基本的な機械学習ワークフローをシミュレートします。
トレーニング中に W&B とやり取りするには、W&B Python SDK (wandb.sdk) を使用します。wandb.Run.log() を使用して損失(loss)をログに記録し、wandb.Artifact を使用してトレーニング済みモデルを Artifacts として保存し、最後に Artifact.add_file を使用してモデルファイルを追加します。
import random # データのシミュレーション用
def model(training_data: int) -> int:
"""デモンストレーション用のモデルシミュレーション。"""
return training_data * 2 + random.randint(-1, 1)
# 重みとノイズのシミュレーション
weights = random.random() # ランダムな重みを初期化
noise = random.random() / 5 # ノイズをシミュレートするための小さなランダムノイズ
# ハイパーパラメーターと設定
config = {
"epochs": 10, # トレーニングするエポック数
"learning_rate": 0.01, # オプティマイザーの学習率
}
# コンテキストマネージャーを使用して W&B Runs を初期化および終了
with wandb.init(project=PROJECT, entity=TEAM_ENTITY, config=config) as run:
# トレーニングループのシミュレーション
for epoch in range(config["epochs"]):
xb = weights + noise # シミュレートされた入力トレーニングデータ
yb = weights + noise * 2 # シミュレートされたターゲット出力(入力ノイズの2倍)
y_pred = model(xb) # モデルの予測
loss = (yb - y_pred) ** 2 # 平均二乗誤差(MSE)損失
print(f"epoch={epoch}, loss={loss}")
# エポックと損失を W&B にログ記録
run.log({
"epoch": epoch,
"loss": loss,
})
# モデルアーティファクトの一意の名前
model_artifact_name = f"model-demo"
# シミュレートされたモデルファイルを保存するローカルパス
PATH = "model.txt"
# モデルをローカルに保存
with open(PATH, "w") as f:
f.write(str(weights)) # モデルの重みをファイルに保存
# アーティファクトオブジェクトを作成
# ローカルに保存されたモデルをアーティファクトオブジェクトに追加
artifact = wandb.Artifact(name=model_artifact_name, type="model", description="My trained model")
artifact.add_file(local_path=PATH)
artifact.save()
- トレーニング中のメトリクスをログに記録するには
wandb.Run.log() を使用します。
- モデル(データセットなど)を Artifacts として W&B プロジェクトに保存するには
wandb.Artifact を使用します。
モデルをトレーニングして Artifacts として保存したので、それを W&B のレジストリに公開できます。wandb.Run.use_artifact() を使用してプロジェクトからアーティファクトを取得し、Model Registry への公開準備をします。wandb.Run.use_artifact() には2つの重要な目的があります:
- プロジェクトからアーティファクトオブジェクトを取得する。
- アーティファクトを run の入力としてマークし、再現性とトレーサビリティを確保する。詳細は リネージマップの作成と表示 を参照してください。
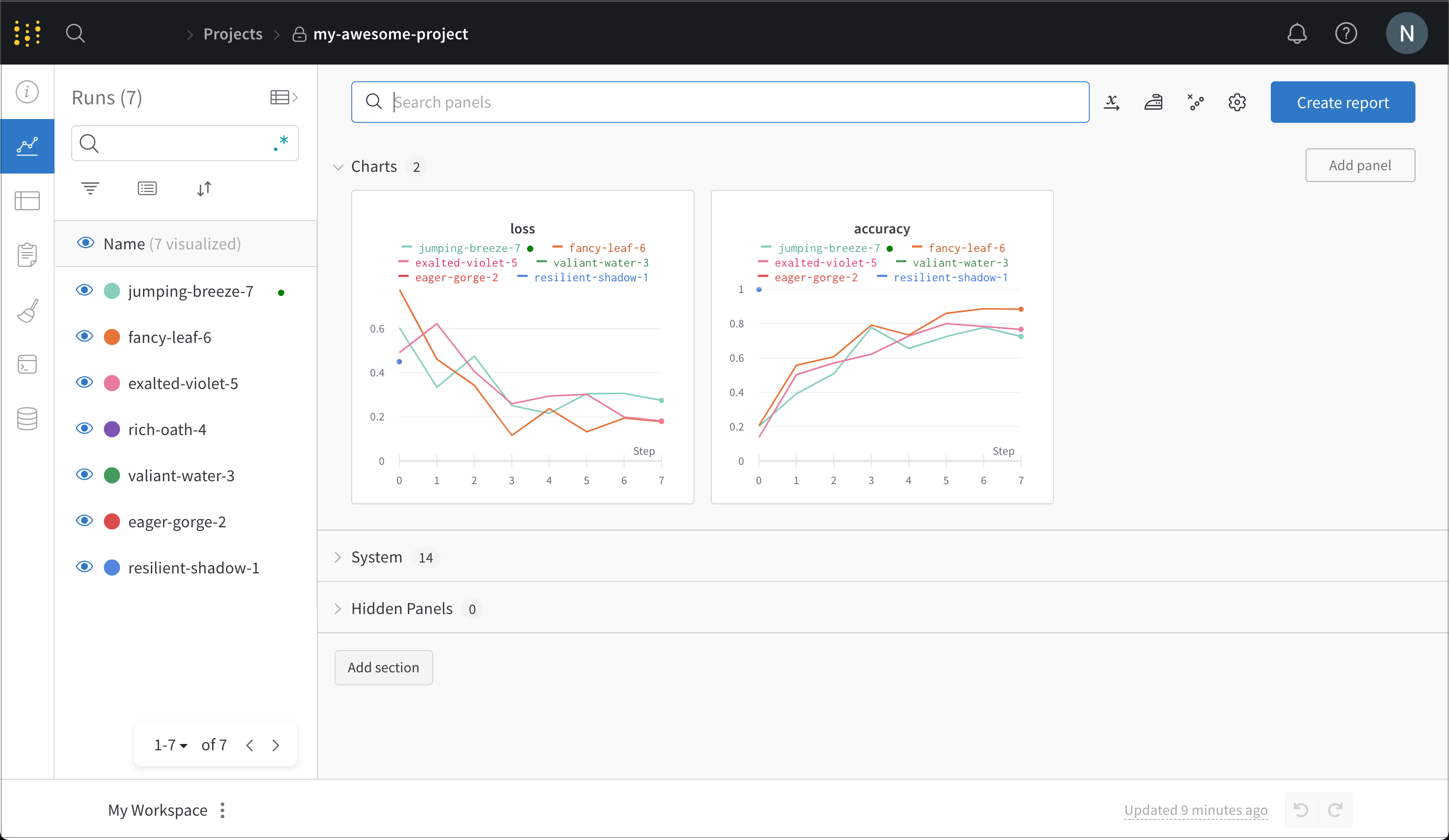
ダッシュボードでトレーニングデータを表示する
https://wandb.ai/login からアカウントにログインします。
Projects の下に my-awesome-project(または上記でプロジェクト名として使用したもの)が表示されているはずです。これをクリックして、プロジェクトの Workspace に入ります。
ここから、実行したすべての Run に関する詳細を確認できます。このスクリーンショットでは、コードが数回再実行され、いくつかの Runs が生成されており、それぞれにランダムに生成された名前が付いています。
モデルを W&B Registry に公開する
組織内の他のユーザーとモデルを共有するには、wandb.Run.link_artifact() を使用して コレクション に公開します。以下のコードはアーティファクトを レジストリ にリンクし、チームがアクセスできるようにします。
# アーティファクト名は、チームのプロジェクト内の特定のアーティファクトバージョンを指定します
artifact_name = f'{TEAM_ENTITY}/{PROJECT}/{model_artifact_name}:v0'
print("Artifact name: ", artifact_name)
REGISTRY_NAME = "Model" # W&B でのレジストリ名
COLLECTION_NAME = "DemoModels" # レジストリ内のコレクション名
# レジストリ内のアーティファクトのターゲットパスを作成
target_path = f"wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}"
print("Target path: ", target_path)
with wandb.init(entity=TEAM_ENTITY, project=PROJECT) as run:
model_artifact = run.use_artifact(artifact_or_name=artifact_name, type="model")
run.link_artifact(artifact=model_artifact, target_path=target_path)
wandb.Run.link_artifact() を実行すると、モデルアーティファクトはレジストリ内の DemoModels コレクションに入ります。そこから、バージョン履歴、リネージマップ、その他の メタデータ などの詳細を確認できます。
アーティファクトをレジストリにリンクする方法の追加情報については、アーティファクトをレジストリにリンクする を参照してください。
推論のためにレジストリからモデルアーティファクトを取得する
推論にモデルを使用するには、wandb.Run.use_artifact() を使用してレジストリから公開されたアーティファクトを取得します。これによりアーティファクトオブジェクトが返され、wandb.Artifact.download() を使用してアーティファクトをローカルファイルにダウンロードできます。
REGISTRY_NAME = "Model" # W&B でのレジストリ名
COLLECTION_NAME = "DemoModels" # レジストリ内のコレクション名
VERSION = 0 # 取得するアーティファクトのバージョン
model_artifact_name = f"wandb-registry-{REGISTRY_NAME}/{COLLECTION_NAME}:v{VERSION}"
print(f"Model artifact name: {model_artifact_name}")
with wandb.init(entity=TEAM_ENTITY, project=PROJECT) as run:
registry_model = run.use_artifact(artifact_or_name=model_artifact_name)
local_model_path = registry_model.download()
レポートで発見を共有する
W&B Report および Workspace API はパブリックプレビュー中です。
pip install wandb wandb-workspaces -qqq
import wandb_workspaces.reports.v2 as wr
experiment_summary = """これは、W&B を使用してシンプルなモデルをトレーニングするために実施された実験の要約です。"""
dataset_info = """トレーニングに使用されたデータセットは、シンプルなモデルによって生成された合成データで構成されています。"""
model_info = """モデルは、ノイズを含む入力データに基づいて出力を予測するシンプルな線形回帰モデルです。"""
report = wr.Report(
project=PROJECT,
entity=TEAM_ENTITY,
title="My Awesome Model Training Report",
description=experiment_summary,
blocks= [
wr.TableOfContents(),
wr.H2("Experiment Summary"),
wr.MarkdownBlock(text=experiment_summary),
wr.H2("Dataset Information"),
wr.MarkdownBlock(text=dataset_info),
wr.H2("Model Information"),
wr.MarkdownBlock(text = model_info),
wr.PanelGrid(
panels=[
wr.LinePlot(title="Train Loss", x="Step", y=["loss"], title_x="Step", title_y="Loss")
],
),
]
)
# レポートを W&B に保存
report.save()
レジストリへのクエリ
W&B Public APIs を使用して、W&B の履歴データのクエリ、分析、管理を行います。これは、アーティファクトのリネージの追跡、異なるバージョンの比較、モデルの経時的なパフォーマンス分析に役立ちます。
以下のコードブロックは、特定のコレクション内のすべてのアーティファクトを Model Registry から照会する方法を示しています。コレクションを取得し、そのバージョンを反復処理して、各アーティファクトの名前とバージョンを出力します。
import wandb
# wandb API を初期化
api = wandb.Api()
# 文字列 `model` を含み、
# かつ `text-classification` タグまたは `latest` エイリアスのいずれかを持つすべてのアーティファクトバージョンを検索します
registry_filters = {
"name": {"$regex": "model"}
}
# 論理 $or 演算子を使用してアーティファクトバージョンをフィルタリングします
version_filters = {
"$or": [
{"tag": "text-classification"},
{"alias": "latest"}
]
}
# フィルターに一致するすべてのアーティファクトバージョンのイテラブルを返します
artifacts = api.registries(filter=registry_filters).collections().versions(filter=version_filters)
# 見つかった各アーティファクトの名前、コレクション、エイリアス、タグ、作成日時を出力します
for art in artifacts:
print(f"artifact name: {art.name}")
print(f"collection artifact belongs to: { art.collection.name}")
print(f"artifact aliases: {art.aliases}")
print(f"tags attached to artifact: {art.tags}")
print(f"artifact created at: {art.created_at}\n")