任意のライブラリに wandb を追加する
このガイドでは、W&BをPythonライブラリに統合するためのベストプラクティスを紹介します。これにより、独自のライブラリで強力な 実験管理、GPUおよびシステムモニタリング、モデルのチェックポイント保存などを利用できるようになります。W&Bの使用方法をまだ学習中の場合は、読み進める前に 実験管理 など、このドキュメント内の他の W&B ガイドを先に確認することをお勧めします。
- セットアップ要件
- ユーザーログイン
- wandb Run の開始
- Run Config の定義
- W&Bへのログ記録
- 分散トレーニング
- モデルのチェックポイント保存とその他
- ハイパーパラメータチューニング
- 高度なインテグレーション
セットアップ要件
開始する前に、W&Bをライブラリの依存関係に必須とするかどうかを決定してください。インストール時に W&B を必須にする
requirements.txt ファイルなどの依存関係ファイルに、W&B Pythonライブラリ (wandb) を追加します。
インストール時に W&B を任意にする
W&B SDK (wandb) をオプションにするには、2つの方法があります。
A. ユーザーが手動でインストールせずに wandb 機能を使用しようとしたときにエラーを発生させ、適切なエラーメッセージを表示する:
pyproject.toml ファイルにオプションの依存関係として wandb を追加する:
ユーザーログイン
APIキーの作成
APIキーは、クライアントまたはマシンをW&Bに対して認証します。ユーザープロファイルから APIキー を生成できます。For a more streamlined approach, create an API key by going directly to User Settings. Copy the newly created API key immediately and save it in a secure location such as a password manager.
- 右上隅にあるユーザープロファイルアイコンをクリックします。
- User Settings を選択し、API Keys セクションまでスクロールします。
wandb ライブラリのインストールとログイン
ローカルに wandb ライブラリをインストールしてログインするには:
- Command Line
- Python
- Python notebook
-
WANDB_API_KEY環境変数 を APIキー に設定します。 -
wandbライブラリをインストールしてログインします。
wandb.init を呼び出すと、自動的にログインを促すプロンプトが表示されます。
Run の開始
W&B Run は、W&Bによって記録される計算の単位です。通常、1つのトレーニング実験につき1つの W&B Run を関連付けます。 コード内で W&B を初期化し、Run を開始するには次のようにします。wandb_project などのパラメータを使用してユーザー自身に設定させたりすることができます。また、entity パラメータとして wandb_entity のようにユーザー名やチーム名を指定することも可能です。
run.finish() を呼び出す必要があります。インテグレーションの設計に合う場合は、Run をコンテキストマネージャーとして使用してください。
wandb.init をいつ呼び出すべきか?
コンソールへの出力(エラーメッセージを含む)はすべて W&B Run の一部として記録されるため、ライブラリではできるだけ早い段階で W&B Run を作成する必要があります。これによりデバッグが容易になります。
wandb をオプションの依存関係として使用する
ユーザーがライブラリを使用する際に wandb をオプションにしたい場合は、以下のいずれかを行います。
- 次のような
wandbフラグを定義する:
- Python
- Bash
- または、
wandb.initでwandbをdisabledに設定する:
- Python
- Bash
- または、
wandbをオフラインに設定する。これによってwandbは引き続き動作しますが、インターネット経由で W&B と通信しようとはしません。
- Environment Variable
- Bash
Run Config の定義
wandb の Run Config を使用すると、W&B Run を作成する際にモデルやデータセットなどのメタデータを提供できます。この情報を使用して、異なる 実験 を比較し、主な違いを素早く把握できます。
- モデル名、バージョン、アーキテクチャー パラメータなど
- データセット名、バージョン、トレーニング/検証サンプルの数など
- 学習率、バッチサイズ、オプティマイザー などのトレーニングパラメータ
Run Config の更新
config を更新するにはwandb.Run.config.update を使用します。辞書が定義された後にパラメータが取得される場合、設定辞書の更新が役立ちます。例えば、モデルがインスタンス化された後にモデルのパラメータを追加したい場合などです。
W&Bへのログ記録
メトリクスのログ記録
キーの値がメトリクスの名前である辞書を作成します。この辞書オブジェクトをrun.log に渡します。
train/... や val/... などのプレフィックスを使用することで、UI上で自動的にグループ化できます。これにより、W&B Workspace 内にトレーニングメトリクスと検証メトリクス、またはその他の分離したいメトリクスタイプごとのセクションが作成されます。
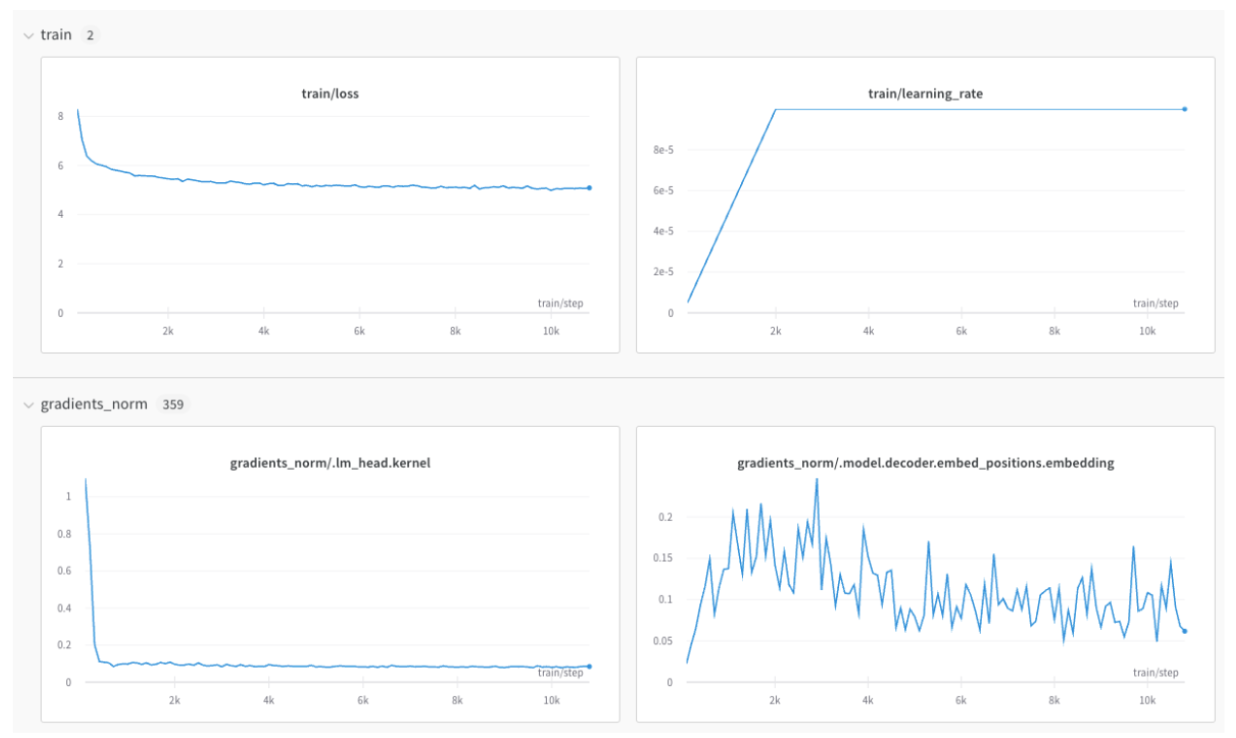
wandb.Run.log() リファレンス を参照してください。
X軸のずれを防ぐ
同じトレーニングステップに対してrun.log を複数回呼び出すと、wandb SDK は run.log の呼び出しごとに内部ステップカウンターをインクリメントします。このカウンターは、トレーニングループ内のトレーニングステップと一致しない場合があります。
この状況を避けるには、wandb.init を呼び出した直後に一度だけ、run.define_metric を使用して X軸のステップを明示的に定義します。
* は、すべてのメトリクスがチャートの X軸 として global_step を使用することを意味します。特定のメトリクスのみを global_step に対して記録したい場合は、それらを指定できます。
run.log を呼び出すたびに、メトリクス、step メトリクス、および global_step を記録します。
画像、テーブル、オーディオなどのログ記録
メトリクスに加えて、プロット、ヒストグラム、テーブル、テキスト、および画像、ビデオ、オーディオ、3D などのメディアを記録できます。 データを記録する際の考慮事項は以下の通りです。- メトリクスを記録する頻度はどのくらいか? オプションにするべきか?
- 可視化に役立つデータの種類は何か?
- 画像の場合、予測サンプルやセグメンテーションマスクなどを記録して、時間経過による変化を確認できます。
- テキストの場合、後で探索するために予測サンプルのテーブルを記録できます。
分散トレーニング
分散環境をサポートするフレームワークでは、以下のワークフローのいずれかを適用できます。- どのプロセスが「メイン」プロセスであるかを検出し、そこでのみ
wandbを使用する。他のプロセスからの必要なデータは、まずメインプロセスにルーティングされる必要があります。(このワークフローを推奨します)。 - すべてのプロセスで
wandbを呼び出し、すべてに同じ一意のgroup名を付けて自動グループ化する。
モデルのチェックポイント保存とその他
フレームワークがモデルやデータセットを使用または生成する場合、それらを記録して完全な追跡可能性を確保し、W&B Artifacts を通じてパイプライン全体を自動的にモニタリングできます。
- モデルのチェックポイントやデータセットを記録する機能(オプションにしたい場合)。
- 入力として使用されるアーティファクトのパス/参照(存在する場合)。例:
user/project/artifact。 - Artifacts を記録する頻度。
モデルのチェックポイントを記録する
モデルのチェックポイントを W&B に記録できます。一意のwandb Run ID を利用して出力モデルのチェックポイントに名前を付けると、Run 間でそれらを区別するのに役立ちます。また、有用なメタデータを追加することもできます。さらに、以下に示すように各モデルにエイリアスを追加することも可能です。
学習済みモデルやデータセットのログ記録と追跡
トレーニングの入力として使用される、学習済みモデルやデータセットなどのアーティファクトを記録できます。次のスニペットは、アーティファクトを記録し、上のグラフに示されているように、進行中の Run の入力として追加する方法を示しています。アーティファクトのダウンロード
アーティファクト(データセット、モデルなど)を再利用すると、wandb はローカルにコピーをダウンロードし、キャッシュします。
latest, v2, v3) や、ログ記録時に手動で付けたエイリアス (best_accuracy など) で参照できます。
分散環境や単純な推論などで、wandb run を作成せずに(wandb.init を通さずに)アーティファクトをダウンロードするには、wandb API を使用してアーティファクトを参照できます。