これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクを使用してください:
サードパーティシステムからの トレース のインポート
GenAI アプリケーションのリアルタイムな トレース を取得するために、Weave のシンプルなインテグレーションを使用して Python や Javascript コードをインストルメント化することが不可能な場合があります。多くの場合、これらの トレース は後でcsv や json 形式で利用可能になります。
このクックブックでは、低レベルの Weave Python API を探索し、CSV ファイルからデータを抽出して Weave にインポートし、インサイトの獲得や厳密な 評価 を推進する方法を説明します。
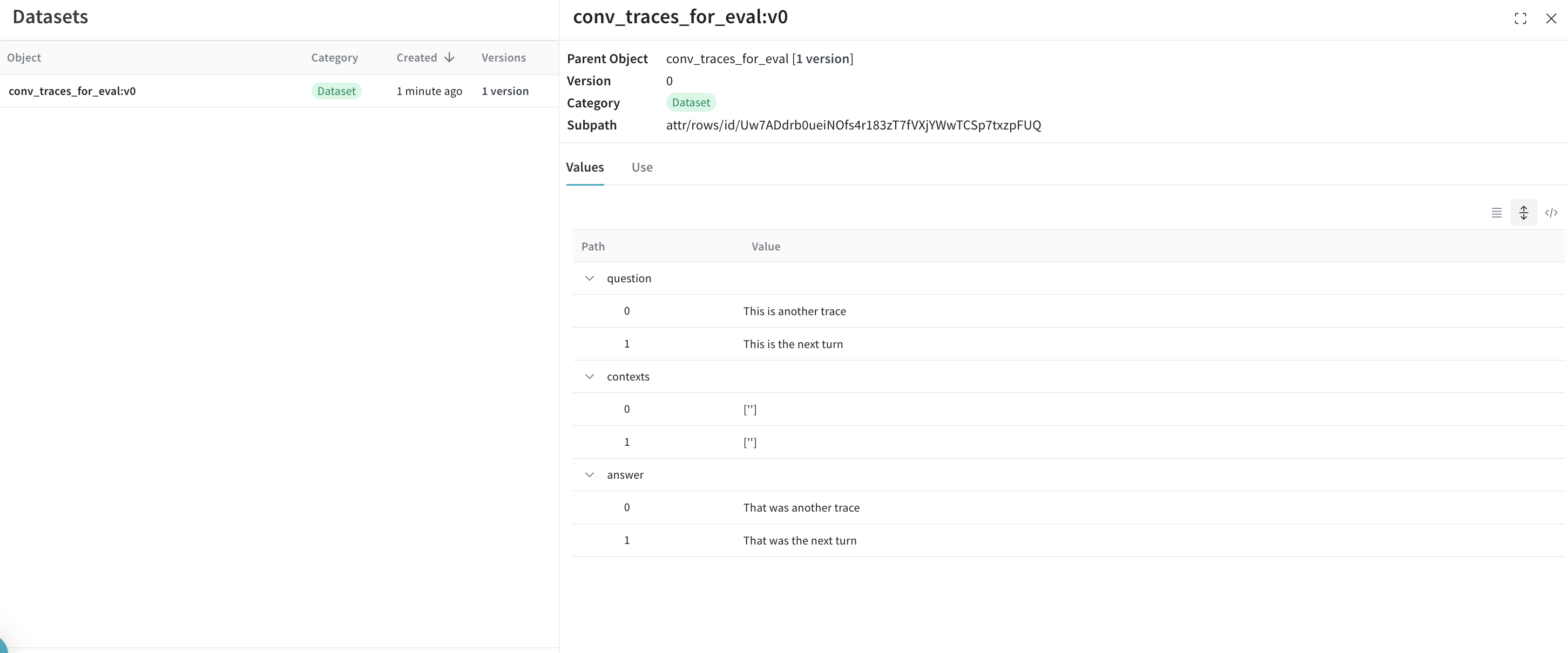
このクックブックで想定しているサンプル データセット の構造は以下の通りです:
conversation_id を親の識別子として、turn_index を子の識別子として使用します。
必要に応じて変数を変更してください。
環境のセットアップ
必要なパッケージをすべてインストールし、インポートします。 環境変数にWANDB_API_KEY を設定することで、wandb.login() で簡単にログインできるようにします(これは Colab の secret として提供する必要があります)。
Colab にアップロードするファイル名を name_of_file に設定し、ログを記録する W&B の プロジェクト 名を name_of_wandb_project に設定します。
注意: name_of_wandb_project は、トレース をログに記録するチームを指定するために {team_name}/{project_name} の形式にすることもできます。
その後、weave.init() を呼び出して Weave クライアントを取得します。
データの読み込み
データを Pandas の DataFrame に読み込み、conversation_id と turn_index でソートして、親子関係が正しく並ぶようにします。
これにより、conversation_data の下に会話のターンが配列として格納された 2 カラムの Pandas DF が作成されます。
トレース を Weave に ログ
Pandas DF をイテレートします:conversation_idごとに親の call を作成します。- ターンの配列をイテレートし、
turn_indexでソートされた子の call を作成します。
- Weave の call は Weave の トレース と同等です。この call には親または子が関連付けられている場合があります。
- Weave の call には、フィードバックや メタデータ など、他のものを関連付けることができます。ここでは入力と出力のみを関連付けますが、データが提供されている場合は、インポート時にこれらを追加することもできます。
- Weave の call はリアルタイムで追跡されることを想定しているため、
createdとfinishedがあります。今回は事後インポートであるため、オブジェクトが定義され、互いに関連付けられた時点で作成し、終了させます。 - call の
op値は、Weave が同じ構成の call をどのように分類するかを決定します。この例では、すべての親の call はConversationタイプ、すべての子の call はTurnタイプになります。これは必要に応じて変更可能です。 - call は
inputsとoutputを持つことができます。inputsは作成時に定義され、outputは call が終了したときに定義されます。
結果: トレース が Weave にログされました
トレース: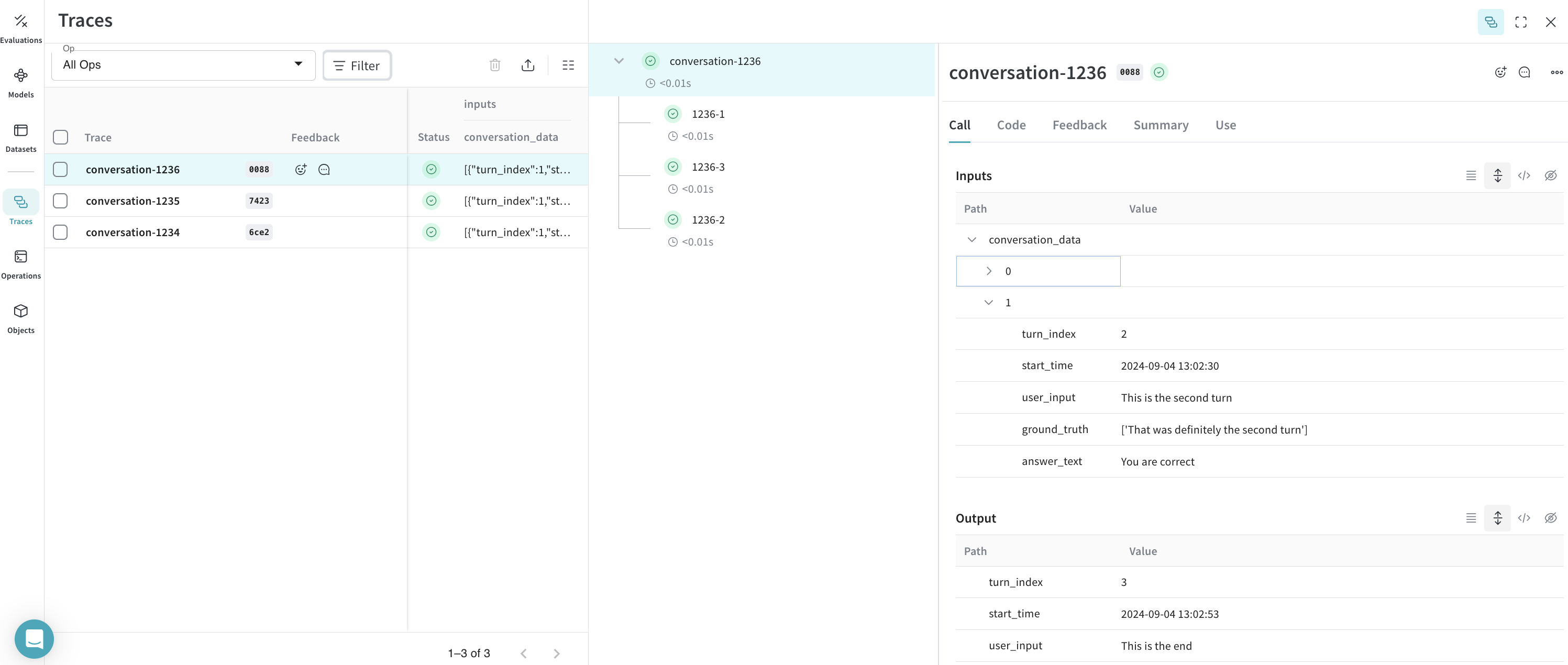
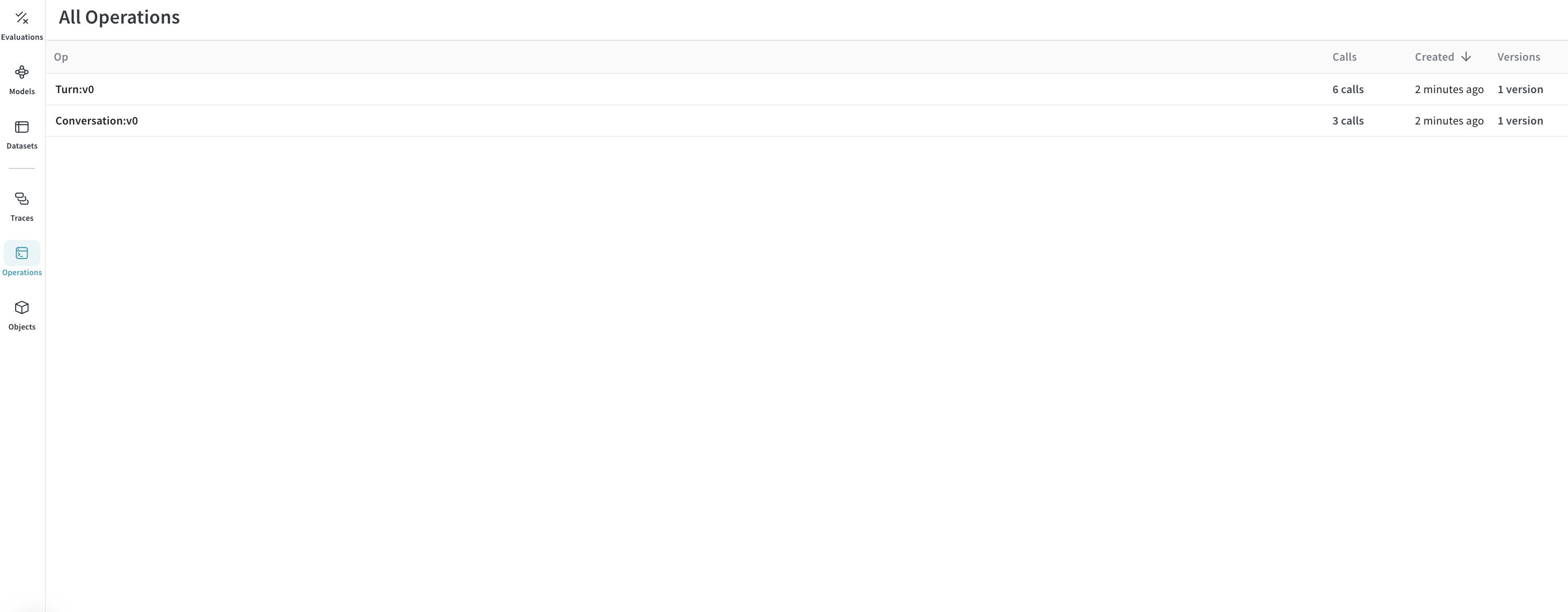
ボーナス: トレース をエクスポートして厳密な 評価 を実行しましょう!
トレース が Weave に入り、会話の様子が把握できたら、後でそれらを別の プロセス にエクスポートして Weave 評価 を実行したくなるかもしれません。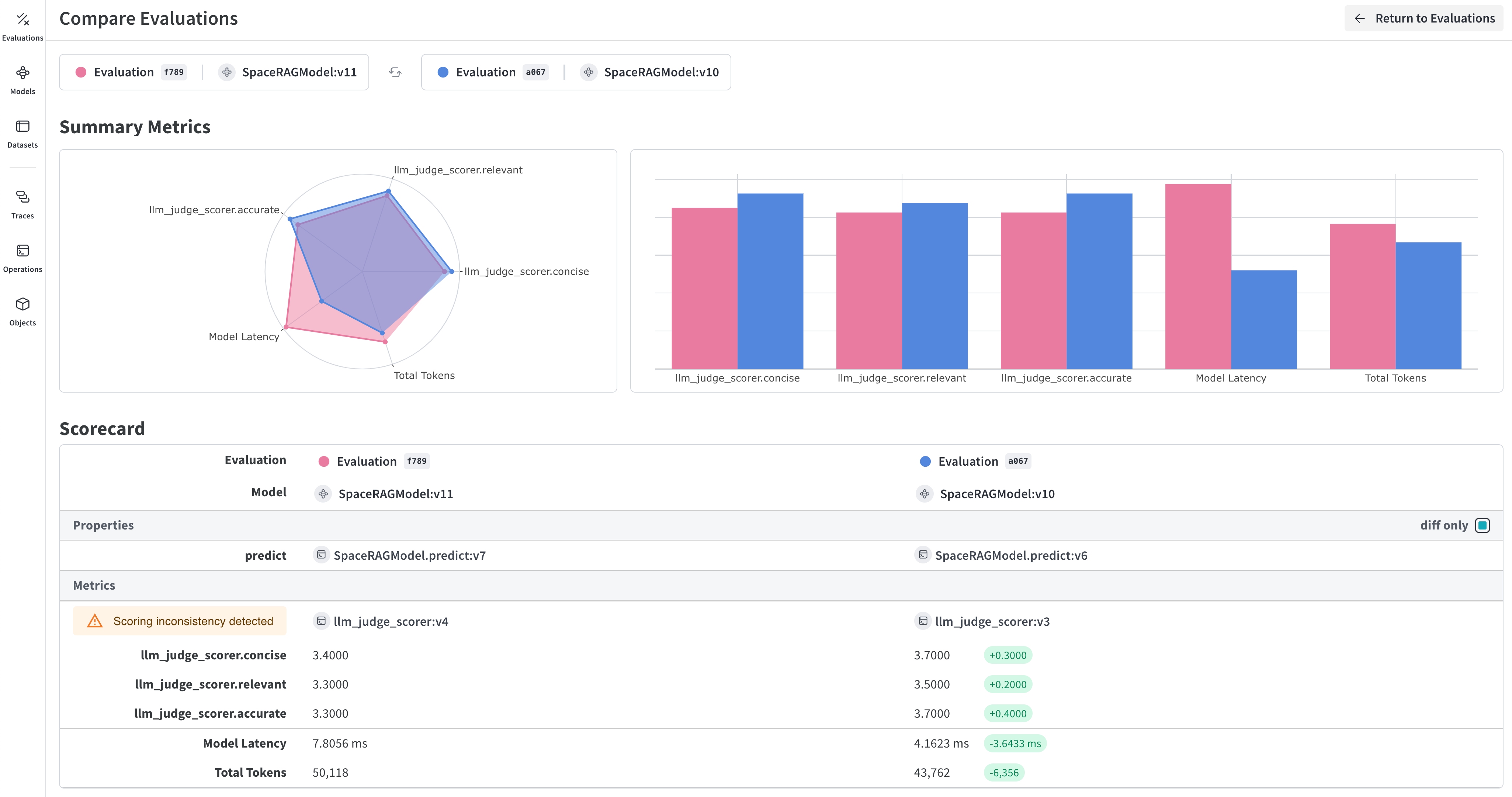
結果