これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクを使用してください:
事前準備
開始する前に、必要なライブラリをインストールしてインポートし、W&B APIキーを取得して、 Weave プロジェクトを初期化します。1. Weave を使用したプロンプトの作成と反復
モデルにエンティティを適切に抽出させるためには、優れたプロンプトエンジニアリングが不可欠です。まず、画像データから何を抽出し、どのようにフォーマットするかをモデルに指示する基本的なプロンプトを作成します。次に、追跡と反復のためにそのプロンプトを Weave に保存します。2. データセットの取得
次に、OCR パイプラインの入力として使用する手書きメモの Datasets を取得します。 データセット内の画像はすでにbase64 エンコードされているため、データは前処理なしで LLM で使用できます。
3. NER パイプラインの構築
次に、NER パイプラインを構築します。パイプラインは 2 つの関数で構成されます。encode_image関数:データセットから PIL 画像を受け取り、VLM に渡すことができる画像のbase64エンコードされた文字列表現を返します。extract_named_entities_from_image関数:画像とシステムプロンプトを受け取り、システムプロンプトの指示に従ってその画像から抽出されたエンティティを返します。
named_entity_recognation という関数を作成します。
- 画像データを NER パイプラインに渡す
- 正しくフォーマットされた JSON 形式の結果を返す
@weave.op() デコレータ を使用して、W&B UI で関数の実行を自動的に追跡し、トレースします。
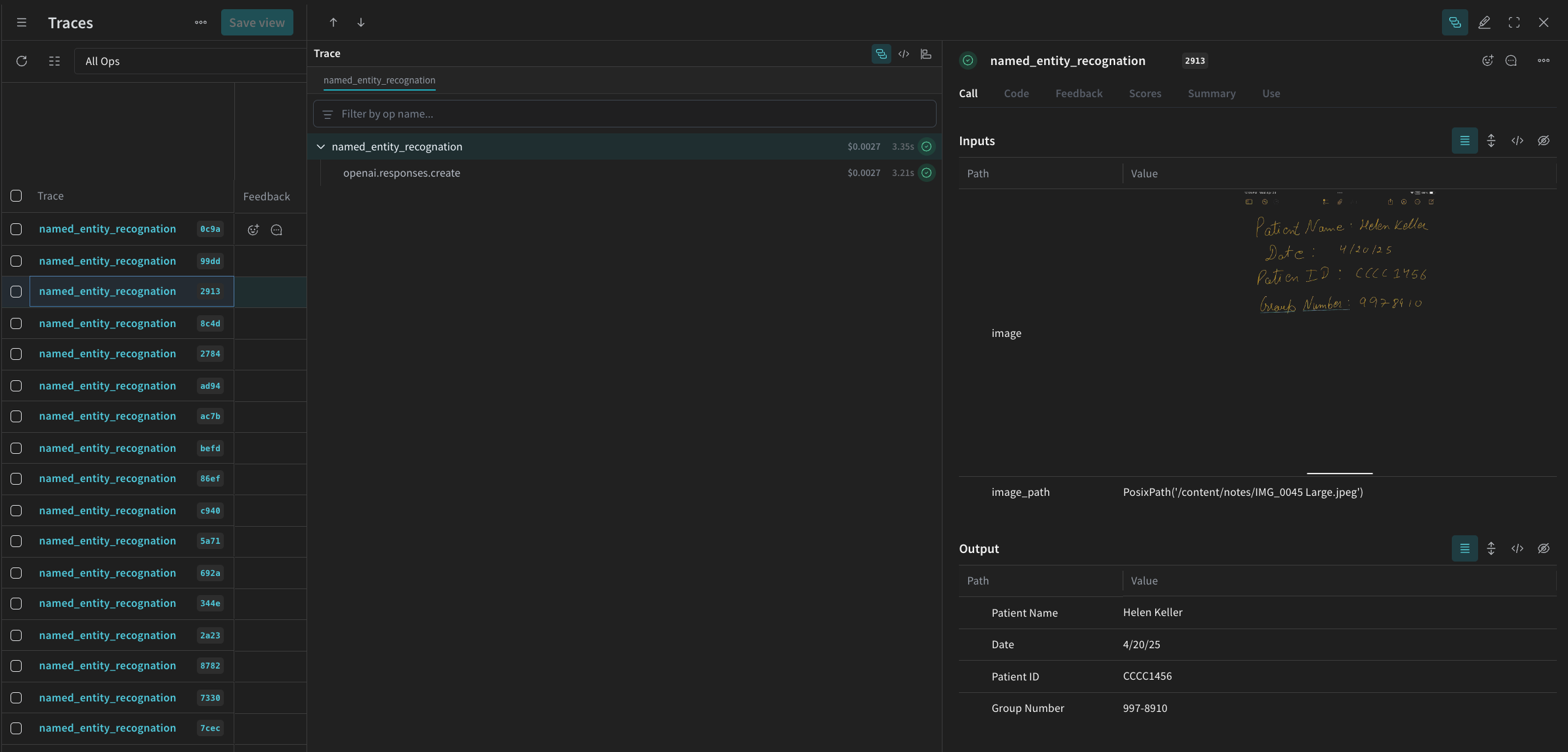
named_entity_recognation が実行されるたびに、詳細なトレース結果が Weave UI で確認できます。トレースを表示するには、 Weave プロジェクトの Traces タブに移動してください。
processing_results.json に保存します。結果は Weave UI でも確認できます。
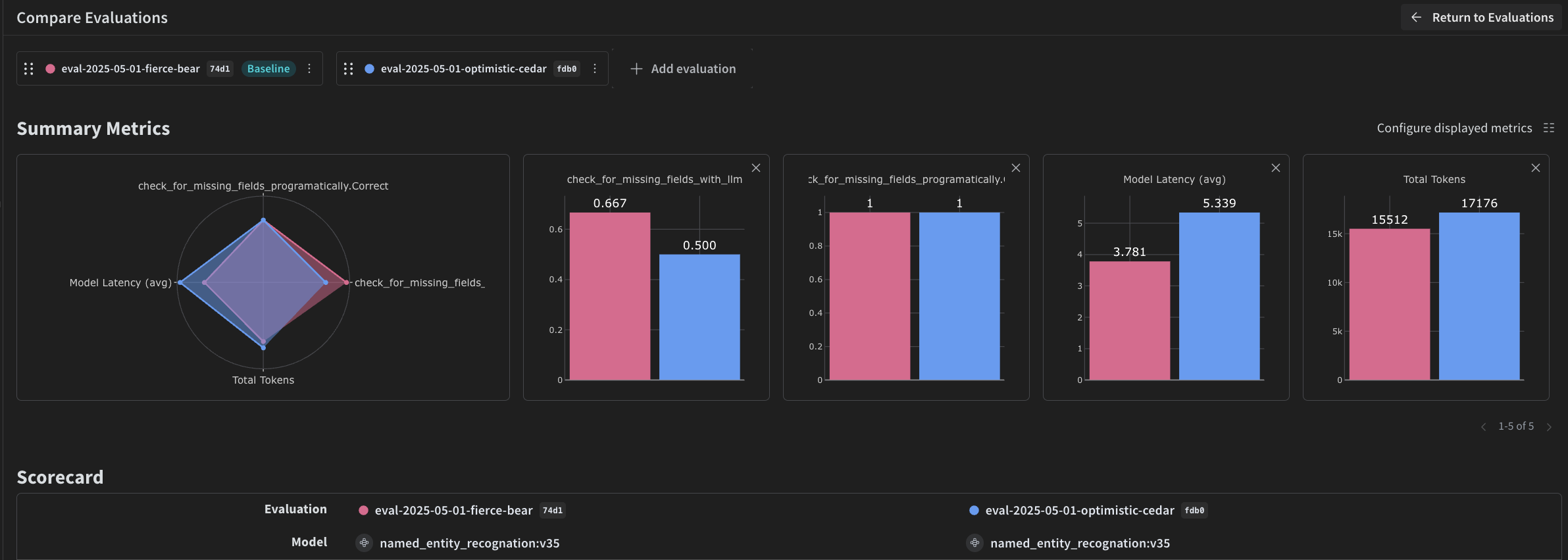
4. Weave を使用したパイプラインの評価
VLM を使用して NER を実行するパイプラインを作成できたので、 Weave を使用して体系的に評価し、そのパフォーマンスを確認できます。 Weave での Evaluations については、Evaluations の概要 で詳しく学べます。 Weave Evaluation の基本要素は Scorers です。Scorers は AI の出力を評価し、評価メトリクスを返すために使用されます。AI の出力を受け取り、分析して、結果の辞書を返します。Scorers は必要に応じて入力データを参照として使用でき、説明や評価の推論などの追加情報を出力することもできます。 このセクションでは、パイプラインを評価するために 2 つの Scorers を作成します。- プログラムによる Scorer
- LLM-as-a-judge Scorer
プログラムによる Scorer
プログラムによる Scorer であるcheck_for_missing_fields_programatically は、モデルの出力(named_entity_recognition 関数の出力)を受け取り、結果の中でどの keys が欠落しているか、または空であるかを特定します。
このチェックは、モデルがいずれかのフィールドをキャプチャし損ねたサンプルを特定するのに適しています。
LLM-as-a-judge Scorer
評価の次のステップでは、画像データとモデルの出力の両方を提供し、評価が実際の NER パフォーマンスを反映するようにします。モデルの出力だけでなく、画像の内容も明示的に参照されます。 このステップで使用される Scorercheck_for_missing_fields_with_llm は、LLM(具体的には OpenAI の gpt-4o)を使用してスコアリングを実行します。eval_prompt の内容で指定されているように、check_for_missing_fields_with_llm は Boolean 値を出力します。すべてのフィールドが画像の情報と一致し、フォーマットが正しい場合、Scorer は true を返します。フィールドが欠落、空、不正確、または不一致である場合、結果は false になり、Scorer は問題を説明するメッセージも返します。
5. Evaluation の実行
最後に、渡されたdataset を自動的にループし、結果をまとめて Weave UI にログ記録する評価コールを定義します。
以下のコードは評価を開始し、NER パイプラインからのすべての出力に対して 2 つの Scorers を適用します。結果は Weave UI の Evals タブで確認できます。