これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクを使用してください:
PII データで Weave を使用する方法
このガイドでは、個人識別情報(PII)データのプライバシーを確保しながら W&B Weave を使用する方法を学びます。このガイドでは、PII データを特定、墨消し(redact)、および匿名化するための以下の手法をデモします:- 正規表現 を使用して PII データを特定し、墨消しする。
- Microsoft の Presidio:Python ベースのデータ保護 SDK。このツールは墨消しおよび置換機能を提供します。
- Faker:偽のデータを生成するための Python ライブラリ。Presidio と組み合わせて PII データを匿名化します。
weave.op の入力/出力ログのカスタマイズ と autopatch_settings を使用して、PII の墨消しと匿名化をワークフローに統合する方法についても学びます。詳細については、ログに記録される入力と出力のカスタマイズ を参照してください。
開始するには、以下を行ってください:
- 概要 セクションを確認する。
- 事前準備 を完了する。
- PII データの特定、墨消し、匿名化のための 利用可能な手法 を確認する。
- Weave の呼び出しにメソッドを適用する。
概要
以下のセクションでは、weave.op を使用した入力と出力のログ記録の概要、および Weave で PII データを扱う際のベストプラクティスについて説明します。
weave.op を使用した入力と出力のログ記録のカスタマイズ
Weave Ops では、入力および出力の後処理関数を定義できます。これらの関数を使用することで、LLM 呼び出しに渡されるデータや Weave にログ記録されるデータを変更できます。
以下の例では、2 つの後処理関数が定義され、weave.op() の引数として渡されています。
PII データで Weave を使用するためのベストプラクティス
PII データで Weave を使用する前に、以下のベストプラクティスを確認してください。テスト中
- 匿名化されたデータをログに記録し、PII 検出を確認する
- PII の取り扱いプロセスを Weave Traces で追跡する
- 実際の PII を公開せずに匿名化のパフォーマンスを測定する
プロダクション環境
- 生の PII を決してログに記録しない
- ログを記録する前に機密フィールドを暗号化する
暗号化のヒント
- 後で復号する必要があるデータには可逆暗号を使用する
- 元に戻す必要のない一意の ID には一方向ハッシュを適用する
- 暗号化したまま分析が必要なデータには、専用の暗号化を検討する
事前準備
- まず、必要なパッケージをインストールします。
- 以下のサイトで APIキー を作成します:
- Weave プロジェクトを初期化します。
- 10 個のテキストブロックを含むデモ PII データセットをロードします。
墨消しメソッドの概要
セットアップ が完了したら、次のことができます。 PII データを検出して保護するために、以下の方法を用いて PII データを特定して墨消しし、オプションで匿名化します。- 正規表現 を使用して PII データを特定し、墨消しする。
- Microsoft Presidio:墨消しおよび置換機能を提供する Python ベースのデータ保護 SDK。
- Faker:偽データを生成するための Python ライブラリ。
メソッド 1: 正規表現を使用したフィルタリング
正規表現 (regex) は、PII データを特定して墨消しするための最もシンプルな方法です。正規表現を使用すると、電話番号、メールアドレス、社会保障番号などのさまざまな形式の機密情報に一致するパターンを定義できます。正規表現を使用することで、複雑な NLP 技術を必要とせずに、大量のテキストをスキャンして情報を置換または墨消しできます。メソッド 2: Microsoft Presidio を使用した墨消し
次のメソッドは、Microsoft Presidio を使用して PII データを完全に削除する方法です。Presidio は PII を墨消しし、PII タイプを表すプレースホルダーに置き換えます。例えば、Presidio は"My name is Alex" の Alex を <PERSON> に置き換えます。
Presidio には、一般的なエンティティ のサポートが組み込まれています。以下の例では、PHONE_NUMBER、PERSON、LOCATION、EMAIL_ADDRESS、または US_SSN であるすべてのエンティティを墨消しします。Presidio のプロセスは関数にカプセル化されています。
メソッド 3: Faker と Presidio を使用した置換による匿名化
テキストを墨消しする代わりに、MS Presidio を使用して名前や電話番号などの PII を Faker Python ライブラリで生成された偽データに交換することで匿名化できます。例えば、次のようなデータがあるとします:"My name is Raphael and I like to fish. My phone number is 212-555-5555"
Presidio と Faker を使用して処理されると、次のようになります:
"My name is Katherine Dixon and I like to fish. My phone number is 667.431.7379"
Presidio と Faker を効果的に組み合わせて使用するには、カスタムオペレーターへの参照を提供する必要があります。これらのオペレーターは、PII を偽データに交換する役割を担う Faker 関数を Presidio に指示します。
メソッド 4: autopatch_settings の使用
autopatch_settings を使用すると、サポートされている 1 つ以上の LLM インテグレーションに対して、初期化中に PII の処理を直接設定できます。この方法の利点は次のとおりです:
- PII 処理ロジックが初期化時に一元化およびスコープ定義されるため、カスタムロジックを散在させる必要がなくなります。
- 特定のインテグレーションに対して、PII 処理ワークフローをカスタマイズしたり、完全に無効にしたりできます。
autopatch_settings を使用して PII 処理を設定するには、サポートされている LLM インテグレーションのいずれかの op_settings 内で postprocess_inputs や postprocess_output を定義します。
Weave の呼び出しにメソッドを適用する
以下の例では、PII の墨消しおよび匿名化メソッドを Weave Models に統合し、Weave Traces で結果を確認します。 まず、Weave Model を作成します。Weave Model は、設定、モデルの重み、およびモデルの動作を定義するコードなどの情報の組み合わせです。 モデルには、Anthropic API が呼び出される predict 関数を含めます。Anthropic の Claude Sonnet を使用して Traces を行いながらセンチメント分析を実行します。Claude Sonnet はテキストブロックを受け取り、positive、negative、または neutral のいずれかのセンチメント分類を出力します。さらに、LLM に送信される前に PII データを墨消しまたは匿名化するための後処理関数を含めます。 このコードを実行すると、Weave プロジェクトページへのリンクと、実行した特定のトレース(LLM 呼び出し)へのリンクが表示されます。正規表現メソッド
最もシンプルなケースとして、正規表現を使用して元のテキストから PII データを特定して墨消しできます。Presidio 墨消しメソッド
次に、Presidio を使用して元のテキストから PII データを特定して墨消しします。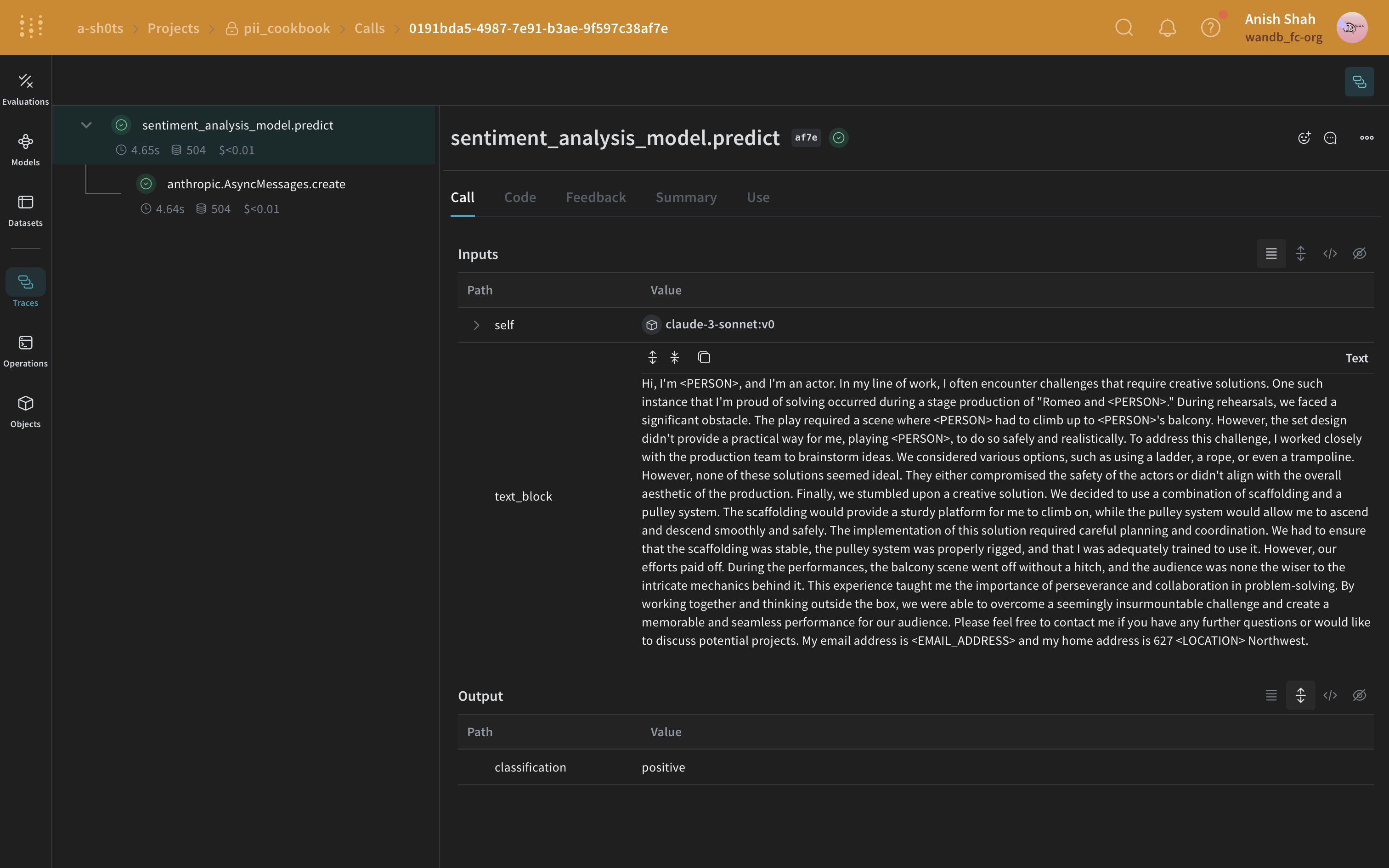
Faker と Presidio による置換メソッド
この例では、Faker を使用して匿名化された置換用 PII データを生成し、Presidio を使用して元のテキスト内の PII データを特定して置換します。
autopatch_settings メソッド
以下の例では、初期化時に anthropic の postprocess_inputs を postprocess_inputs_regex() 関数に設定しています。postprocess_inputs_regex 関数は、メソッド 1: 正規表現を使用したフィルタリング で定義された redact_with_regex メソッドを適用します。これにより、すべての anthropic モデルへの入力すべてに対して redact_with_regex が適用されるようになります。
(オプション) データの暗号化