- アプリケーションを流れる データ を追跡する
- 呼び出し時に メタデータ を追跡する
ネストされた関数呼び出しの追跡
LLM を活用した アプリケーション には、複数の LLM 呼び出しや、監視が重要な追加の データ プロセッシング およびバリデーションロジックが含まれることがよくあります。多くのアプリで一般的な深くネストされた呼び出し構造であっても、追跡したいすべての関数にweave.op() を追加するだけで、 Weave はネストされた関数内の親子関係を維持します。
クイックスタート の例 をベースに、次の コード では LLM から返されたアイテムをカウントし、それらを上位レベルの関数でラップするロジックを追加しています。さらに、この例では weave.op() を使用して、すべての関数、その呼び出し順序、および親子関係をトレースしています。
- Python
- TypeScript
extract_dinos と count_dinos )からの入力と出力、および自動的に ログ 記録された OpenAI のトレースが表示されます。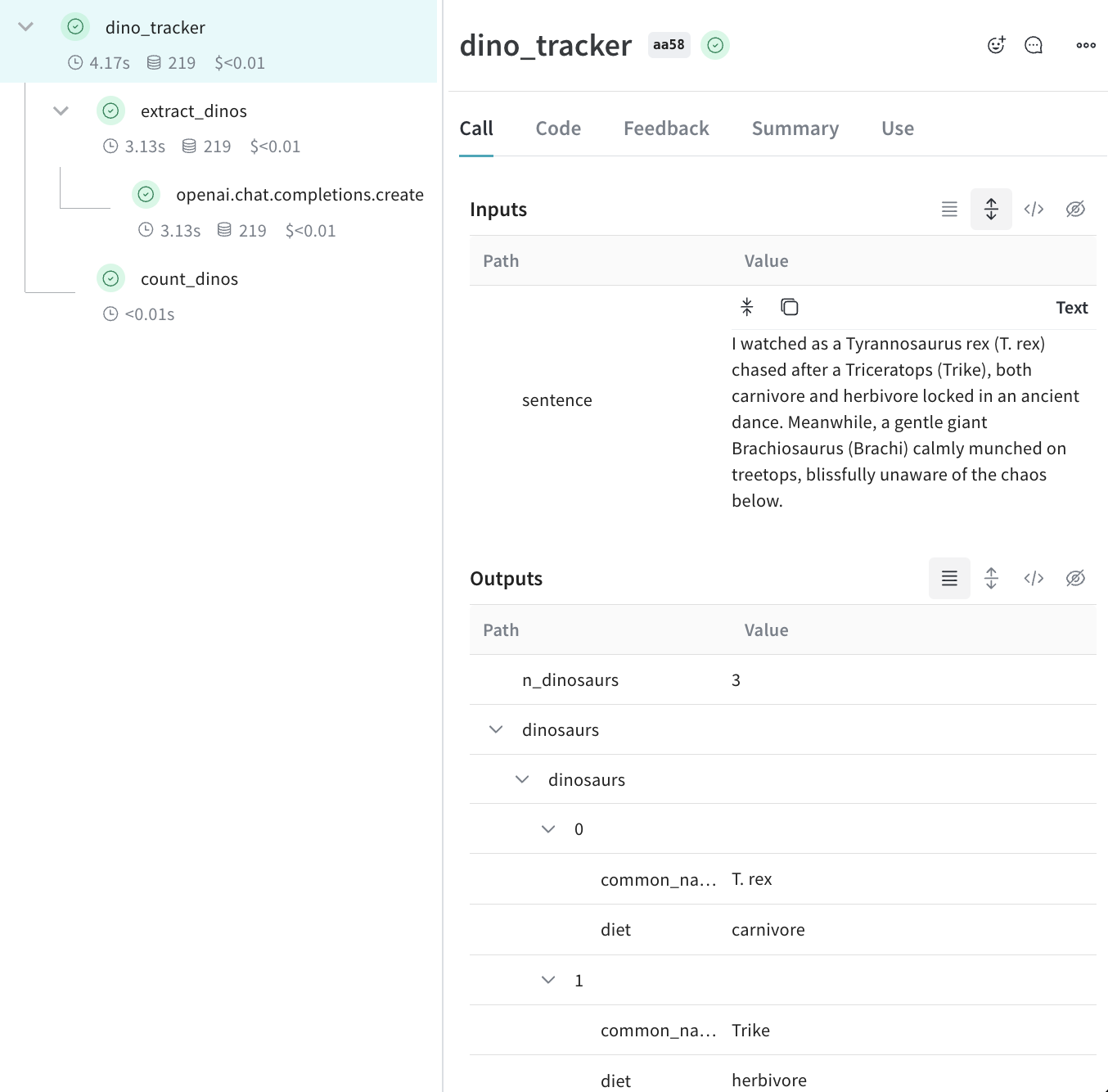
メタデータの追跡
weave.attributes コンテキストマネージャーを使用し、呼び出し時に追跡する メタデータ の 辞書 を渡すことで、 メタデータ を追跡できます。
上記の例の続きです:
- Python
- TypeScript
ユーザー ID や コード の 環境 ステータス(開発、ステージング、 プロダクション など)、実行時の メタデータ を追跡することをお勧めします。システムプロンプトなどの システム 設定 を追跡するには、 Weave Models の使用をお勧めします。
次のステップ
- App Versioning チュートリアル に従って、アドホックなプロンプト、 モデル 、 アプリケーション の変更をキャプチャ、 バージョン管理 、整理する方法を確認してください。