Dagster と Weights & Biases (W&B) を使用して、MLOps パイプラインをオーケストレートし、ML 資産を維持します。W&B とのインテグレーションにより、Dagster 内で以下のことが容易になります。
W&B Dagster インテグレーションは、W&B 固有の Dagster リソースと IO マネージャーを提供します。
wandb_resource: W&B API との認証および通信に使用される Dagster リソース。wandb_artifacts_io_manager: W&B Artifacts を消費するために使用される Dagster IO マネージャー。
以下のガイドでは、Dagster で W&B を使用するための前提条件を満たす方法、ops や assets で W&B Artifacts を作成・使用する方法、W&B Launch の使用方法、および推奨されるベストプラクティスについて説明します。
開始する前に
W&B 内で Dagster を使用するには、以下のリソースが必要です。
- W&B API キー。
- W&B entity (ユーザーまたはチーム): entity は、W&B Runs や Artifacts を送信するユーザー名またはチーム名です。Run をログに記録する前に、W&B App UI でアカウントまたはチームの entity を作成してください。entity を指定しない場合、Run は通常ユーザー名であるデフォルトの entity に送信されます。デフォルトの entity は、設定の Project Defaults で変更できます。
- W&B プロジェクト: W&B Runs が保存されるプロジェクト名。
W&B App のユーザーまたはチームのプロフィールページを確認して、W&B entity を見つけてください。既存の W&B プロジェクトを使用することも、新しく作成することもできます。新しいプロジェクトは、W&B App のホームページまたはユーザー/チームのプロフィールページで作成できます。プロジェクトが存在しない場合は、最初に使用したときに自動的に作成されます。
API キーの設定
- W&B にログイン します。注意: W&B Server を使用している場合は、管理者にインスタンスのホスト名を問い合わせてください。
- User Settings で API キーを作成します。プロダクション環境では、そのキーを所有するために サービスアカウント を使用することをお勧めします。
- その API キーの環境変数を設定します:
export WANDB_API_KEY=YOUR_KEY。
以下の例では、Dagster コードのどこで API キーを指定するかを示しています。wandb_config ネストされた辞書内に entity とプロジェクト名を必ず指定してください。別の W&B プロジェクトを使用したい場合は、異なる wandb_config 値を異なる ops/assets に渡すことができます。渡すことができるキーの詳細については、以下の Configuration セクションを参照してください。
例: @job 用の設定# これを config.yaml に追加します
# あるいは、Dagit の Launchpad または JobDefinition.execute_in_process で設定することもできます
# 参照: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # これをあなたの W&B entity に置き換えてください
project: my_project # これをあなたの W&B プロジェクトに置き換えてください
@job(
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
"io_manager": wandb_artifacts_io_manager,
}
)
def simple_job_example():
my_op()
例: assets を使用した @repository 用の設定from dagster_wandb import wandb_artifacts_io_manager, wandb_resource
from dagster import (
load_assets_from_package_module,
make_values_resource,
repository,
with_resources,
)
from . import assets
@repository
def my_repository():
return [
*with_resources(
load_assets_from_package_module(assets),
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
"wandb_artifacts_manager": wandb_artifacts_io_manager.configured(
{"cache_duration_in_minutes": 60} # ファイルを1時間だけキャッシュする
),
},
resource_config_by_key={
"wandb_config": {
"config": {
"entity": "my_entity", # これをあなたの W&B entity に置き換えてください
"project": "my_project", # これをあなたの W&B プロジェクトに置き換えてください
}
}
},
),
]
@job の例とは異なり、IO マネージャーのキャッシュ保持期間を設定している点に注意してください。 Configuration (設定)
以下の設定オプションは、インテグレーションによって提供される W&B 固有の Dagster リソースおよび IO マネージャーの設定として使用されます。
wandb_resource: W&B API と通信するために使用される Dagster リソース。提供された API キーを使用して自動的に認証されます。プロパティ:
api_key: (str, 必須): W&B API と通信するために必要な W&B API キー。host: (str, オプション): 使用する API ホストサーバー。W&B Server を使用している場合にのみ必要です。デフォルトはパブリッククラウドホストの https://api.wandb.ai です。
wandb_artifacts_io_manager: W&B Artifacts を消費するための Dagster IO マネージャー。プロパティ:
base_dir: (int, オプション) ローカルストレージとキャッシュに使用されるベースディレクトリ。W&B Artifacts と W&B Run のログはこのディレクトリに対して読み書きされます。デフォルトでは DAGSTER_HOME ディレクトリを使用します。cache_duration_in_minutes: (int, オプション) W&B Artifacts と W&B Run ログをローカルストレージに保持する時間を定義します。その時間内に開かれなかったファイルとディレクトリのみがキャッシュから削除されます。キャッシュのパージは IO マネージャーの実行終了時に行われます。キャッシュを完全に無効にする場合は 0 に設定できます。キャッシュは、同じマシンで実行されるジョブ間で Artifact が再利用される際の速度を向上させます。デフォルトは 30 日です。run_id: (str, オプション): 再開に使用される、この Run の一意の ID。プロジェクト内で一意である必要があり、Run を削除した場合、その ID は再利用できません。短い説明的な名前には name フィールドを、Run 間で比較するためにハイパーパラメーターを保存するには config を使用してください。ID には次の特殊文字を含めることはできません: /\#?%:.. Dagster 内で実験管理を行っている場合、IO マネージャーが Run を再開できるように Run ID を設定する必要があります。デフォルトでは Dagster Run ID (例: 7e4df022-1bf2-44b5-a383-bb852df4077e) に設定されます。run_name: (str, オプション) UI でこの Run を識別しやすくするための短い表示名。デフォルトでは、次の形式の文字列になります: dagster-run-[Dagster Run ID の最初の 8 文字]。例: dagster-run-7e4df022。run_tags: (list[str], オプション) 文字列のリスト。UI 上のこの Run のタグリストに入力されます。タグは、Run をまとめて整理したり、baseline や production のような一時的なラベルを適用したりするのに便利です。UI でタグを追加または削除したり、特定のタグを持つ Run だけに絞り込んだりすることが簡単にできます。インテグレーションによって使用されるすべての W&B Run には dagster_wandb タグが付与されます。
W&B Artifacts の使用
W&B Artifact とのインテグレーションは、Dagster IO マネージャーに基づいています。
IO マネージャー は、asset または op の出力を保存し、それを下流の asset または op への入力としてロードする責任を持つ、ユーザー提供のオブジェクトです。例えば、IO マネージャーはファイルシステム上のファイルからオブジェクトを保存およびロードする場合があります。
このインテグレーションは、W&B Artifacts 用の IO マネージャーを提供します。これにより、Dagster の @op や @asset が W&B Artifacts をネイティブに作成および消費できるようになります。これは、Python リストを含む dataset タイプの W&B Artifact を生成する @asset の簡単な例です。
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3] # これは Artifact に保存されます
@op、@asset、@multi_asset にメタデータ設定をアノテートできます。同様に、Dagster 外で作成された W&B Artifacts も消費できます。
W&B Artifacts の書き込み
続行する前に、W&B Artifacts の使用方法をよく理解しておくことをお勧めします。Artifacts ガイド をお読みください。
W&B Artifact を書き込むには、Python 関数からオブジェクトを返します。W&B では以下のオブジェクトがサポートされています。
- Python オブジェクト (int, dict, list…)
- W&B オブジェクト (Table, Image, Graph…)
- W&B Artifact オブジェクト
以下の例は、Dagster assets (@asset) で W&B Artifacts を書き込む方法を示しています。
Python オブジェクト
W&B オブジェクト
W&B Artifact
pickle モジュールでシリアライズできるものはすべて pickle 化され、インテグレーションによって作成された Artifact に追加されます。Dagster 内でその Artifact を読み込む際に内容はアンピクルされます(詳細は Artifacts の読み込み を参照)。@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3]
Table や Image などの W&B オブジェクトは、インテグレーションによって作成された Artifact に追加されます。この例では、Table を Artifact に追加します。import wandb
@asset(
name="my_artifact",
metadata={
"wandb_artifact_arguments": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset_in_table():
return wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
複雑なユースケースでは、独自の Artifact オブジェクトを構築する必要があるかもしれません。その場合でも、インテグレーションは、インテグレーションの両側でメタデータを補強するなどの有用な追加機能を提供します。import wandb
MY_ASSET = "my_asset"
@asset(
name=MY_ASSET,
io_manager_key="wandb_artifacts_manager",
)
def create_artifact():
artifact = wandb.Artifact(MY_ASSET, "dataset")
table = wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
artifact.add(table, "my_table")
return artifact
Configuration (設定)
wandb_artifact_configuration と呼ばれる設定辞書を、@op、@asset、@multi_asset に設定できます。この辞書は、デコレータの引数にメタデータとして渡す必要があります。この設定は、IO マネージャーによる W&B Artifacts の読み書きを制御するために必要です。
@op の場合、Out メタデータ引数を通じて出力メタデータ内に配置されます。
@asset の場合、asset の metadata 引数内に配置されます。
@multi_asset の場合、AssetOut メタデータ引数を通じて各出力メタデータ内に配置されます。
以下のコード例は、@op、@asset、@multi_asset の計算で辞書を設定する方法を示しています。
@op の例
@asset の例
@multi_asset の例
@op の例:@op(
out=Out(
metadata={
"wandb_artifact_configuration": {
"name": "my_artifact",
"type": "dataset",
}
}
)
)
def create_dataset():
return [1, 2, 3]
@asset の例:@asset(
name="my_artifact",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_dataset():
return [1, 2, 3]
@asset にはすでに名前があるため、設定を通じて名前を渡す必要はありません。インテグレーションは Artifact 名を asset 名として設定します。@multi_asset の例:@multi_asset(
name="create_datasets",
outs={
"first_table": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "training_dataset",
}
},
io_manager_key="wandb_artifacts_manager",
),
"second_table": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "validation_dataset",
}
},
io_manager_key="wandb_artifacts_manager",
),
},
group_name="my_multi_asset_group",
)
def create_datasets():
first_table = wandb.Table(columns=["a", "b", "c"], data=[[1, 2, 3]])
second_table = wandb.Table(columns=["d", "e"], data=[[4, 5]])
return first_table, second_table
name: (str) この Artifact の人間が読める名前。UI でこの Artifact を識別したり、use_artifact 呼び出しで参照したりする際に使用します。名前には、英数字、アンダースコア、ハイフン、ドットを使用できます。名前はプロジェクト内で一意である必要があります。@op では必須です。type: (str) Artifact の整理と区別に使用される Artifact のタイプ。一般的なタイプには dataset や model がありますが、英数字、アンダースコア、ハイフン、ドットを含む任意の文字列を使用できます。出力がまだ Artifact でない場合は必須です。description: (str) Artifact の説明を提供するフリーテキスト。説明は UI で Markdown としてレンダリングされるため、テーブルやリンクなどを配置するのに適しています。aliases: (list[str]) Artifact に適用する 1 つ以上のエイリアスを含む配列。インテグレーションは、設定されているかどうかにかかわらず、そのリストに “latest” タグも追加します。これは、モデルやデータセットのバージョン管理を管理するための効果的な方法です。add_dirs: (list[dict[str, Any]]): Artifact に含める各ローカルディレクトリの設定を含む配列。add_files: (list[dict[str, Any]]): Artifact に含める各ローカルファイルの設定を含む配列。add_references: (list[dict[str, Any]]): Artifact に含める各外部リファレンスの設定を含む配列。serialization_module: (dict) 使用するシリアライゼーションモジュールの設定。詳細については、Serialization セクションを参照してください。
name: (str) シリアライゼーションモジュールの名前。許容される値: pickle, dill, cloudpickle, joblib。モジュールがローカルで使用可能である必要があります。parameters: (dict[str, Any]) シリアライゼーション関数に渡されるオプションの引数。そのモジュールの dump メソッドと同じパラメータを受け入れます。例: {"compress": 3, "protocol": 4}。
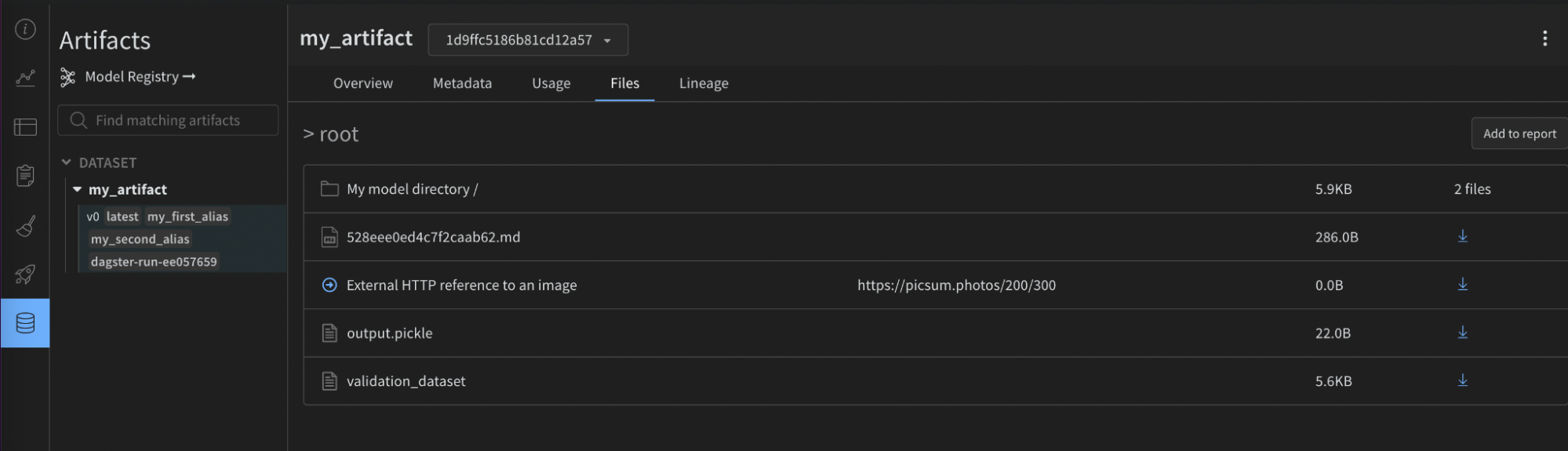
高度な例:
@asset(
name="my_advanced_artifact",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
"description": "My *Markdown* description",
"aliases": ["my_first_alias", "my_second_alias"],
"add_dirs": [
{
"name": "My directory",
"local_path": "path/to/directory",
}
],
"add_files": [
{
"name": "validation_dataset",
"local_path": "path/to/data.json",
},
{
"is_tmp": True,
"local_path": "path/to/temp",
},
],
"add_references": [
{
"uri": "https://picsum.photos/200/300",
"name": "External HTTP reference to an image",
},
{
"uri": "s3://my-bucket/datasets/mnist",
"name": "External S3 reference",
},
],
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_advanced_artifact():
return [1, 2, 3]
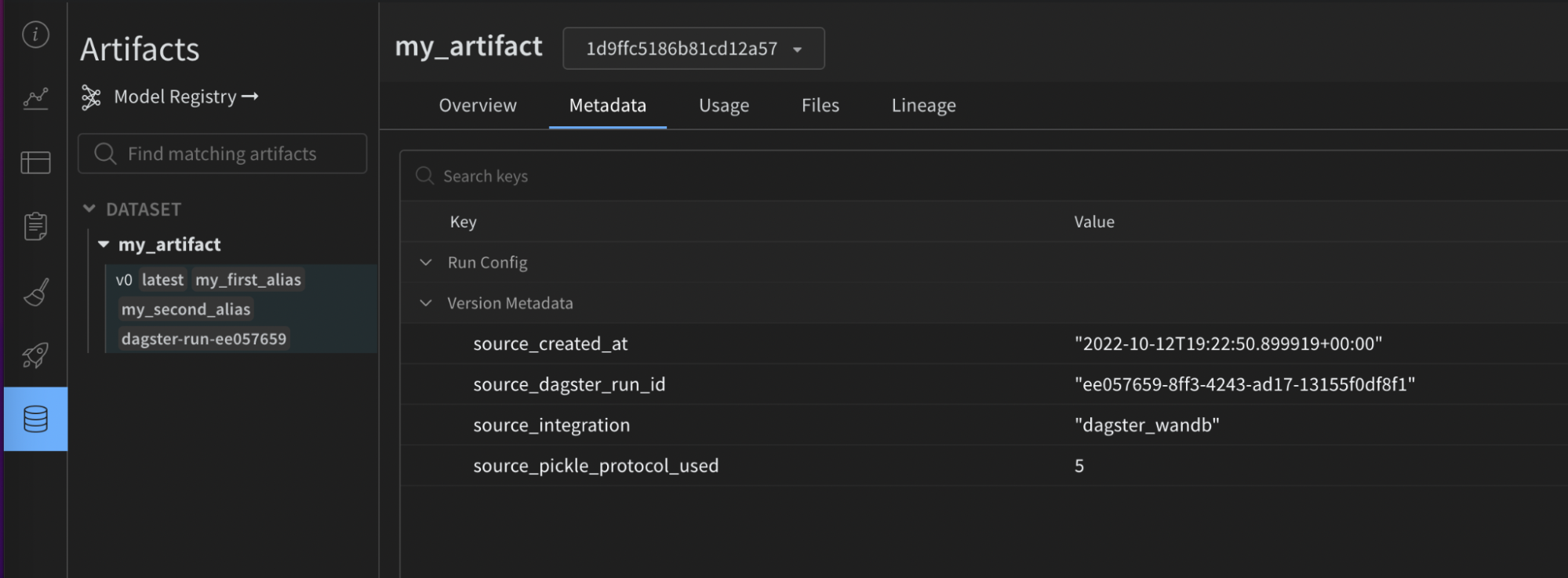
- W&B 側: ソースインテグレーションの名前とバージョン、使用された Python バージョン、pickle プロトコルバージョンなど。
- Dagster 側:
- Dagster Run ID
- W&B Run: ID, 名前, パス, URL
- W&B Artifact: ID, 名前, タイプ, バージョン, サイズ, URL
- W&B Entity
- W&B Project
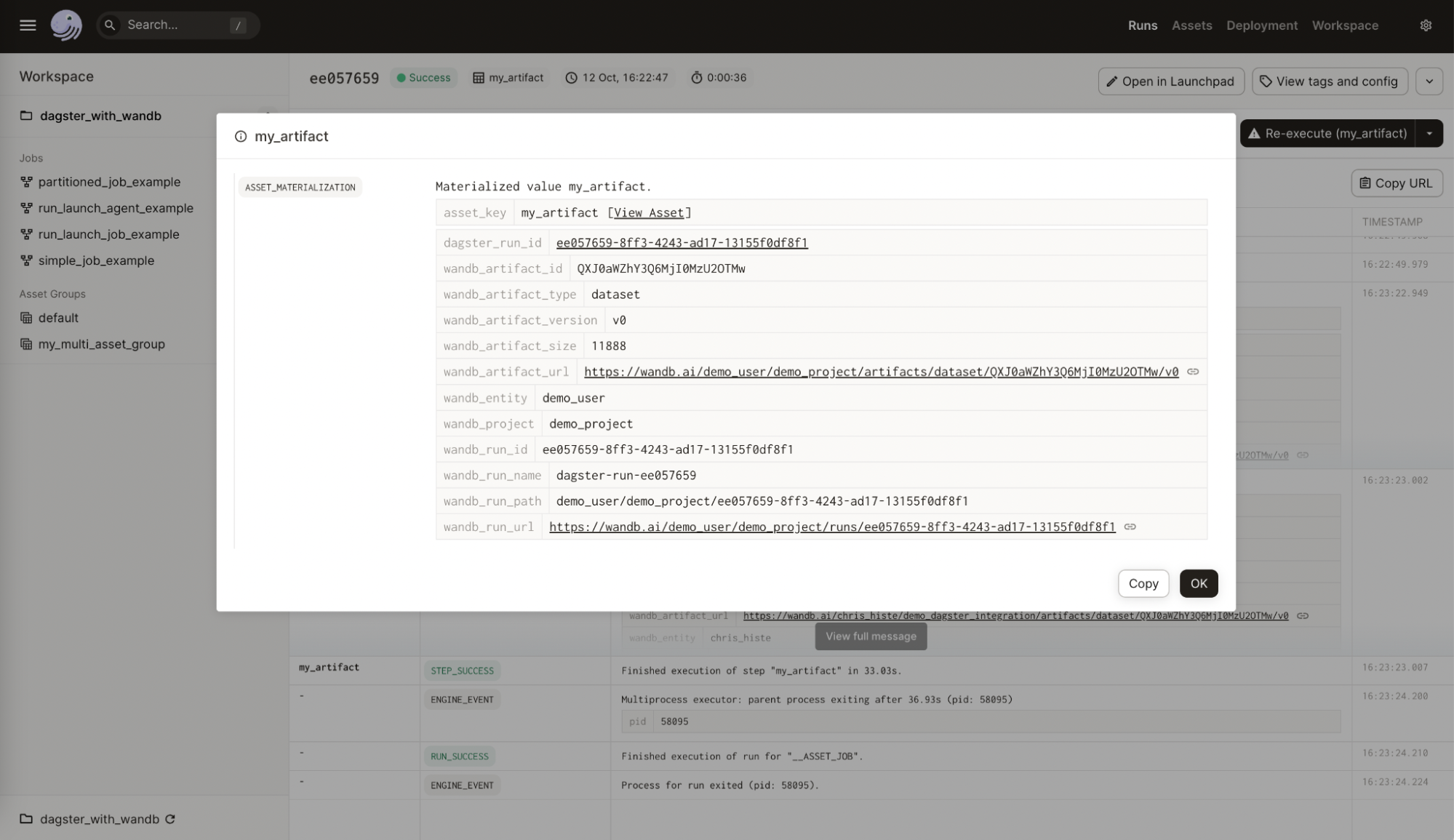
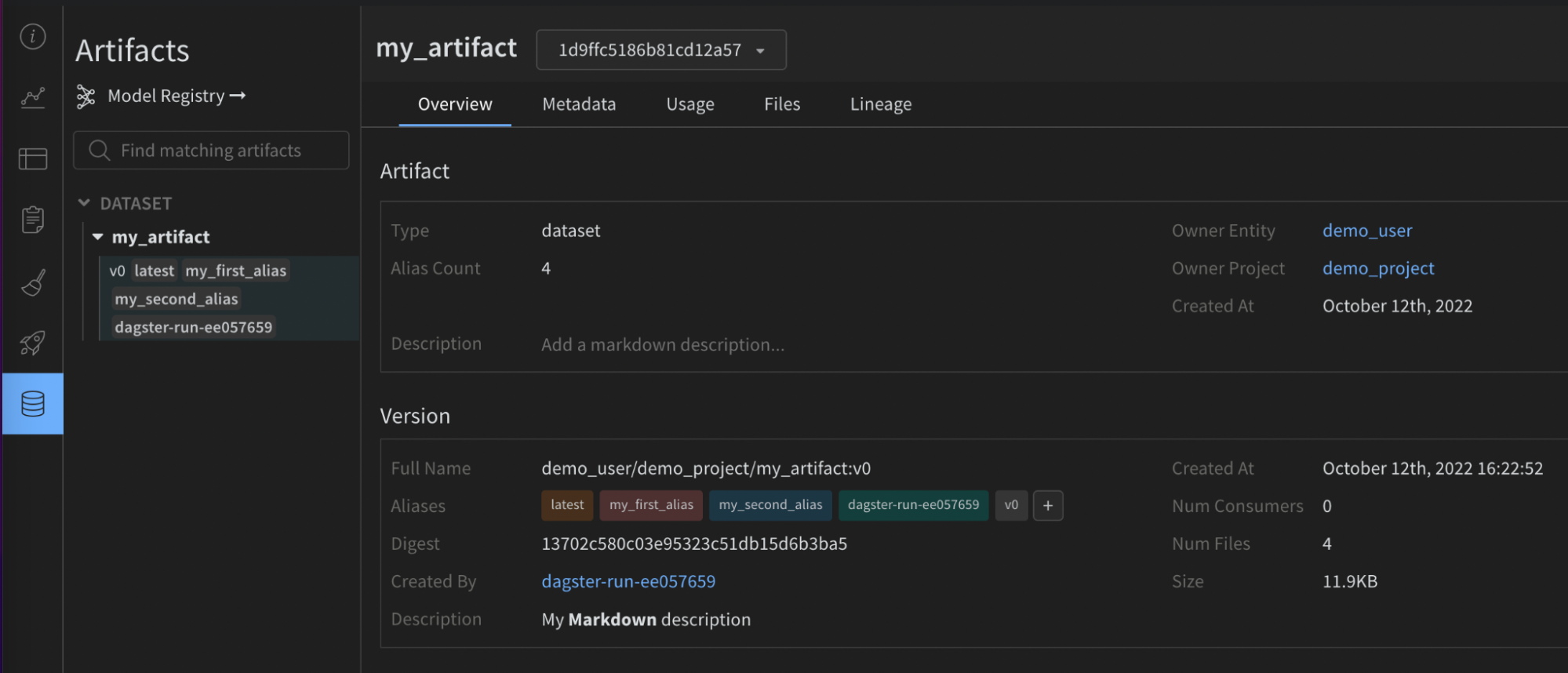
次の画像は、W&B から Dagster asset に追加されたメタデータを示しています。この情報はインテグレーションなしでは利用できません。
次の画像は、提供された設定が W&B Artifact 上の有用なメタデータでどのように強化されたかを示しています。この情報は再現性とメンテナンスに役立ちます。これもインテグレーションなしでは利用できません。
mypy のような静的タイプチェッカーを使用している場合は、次のようにして設定タイプ定義オブジェクトをインポートしてください。from dagster_wandb import WandbArtifactConfiguration
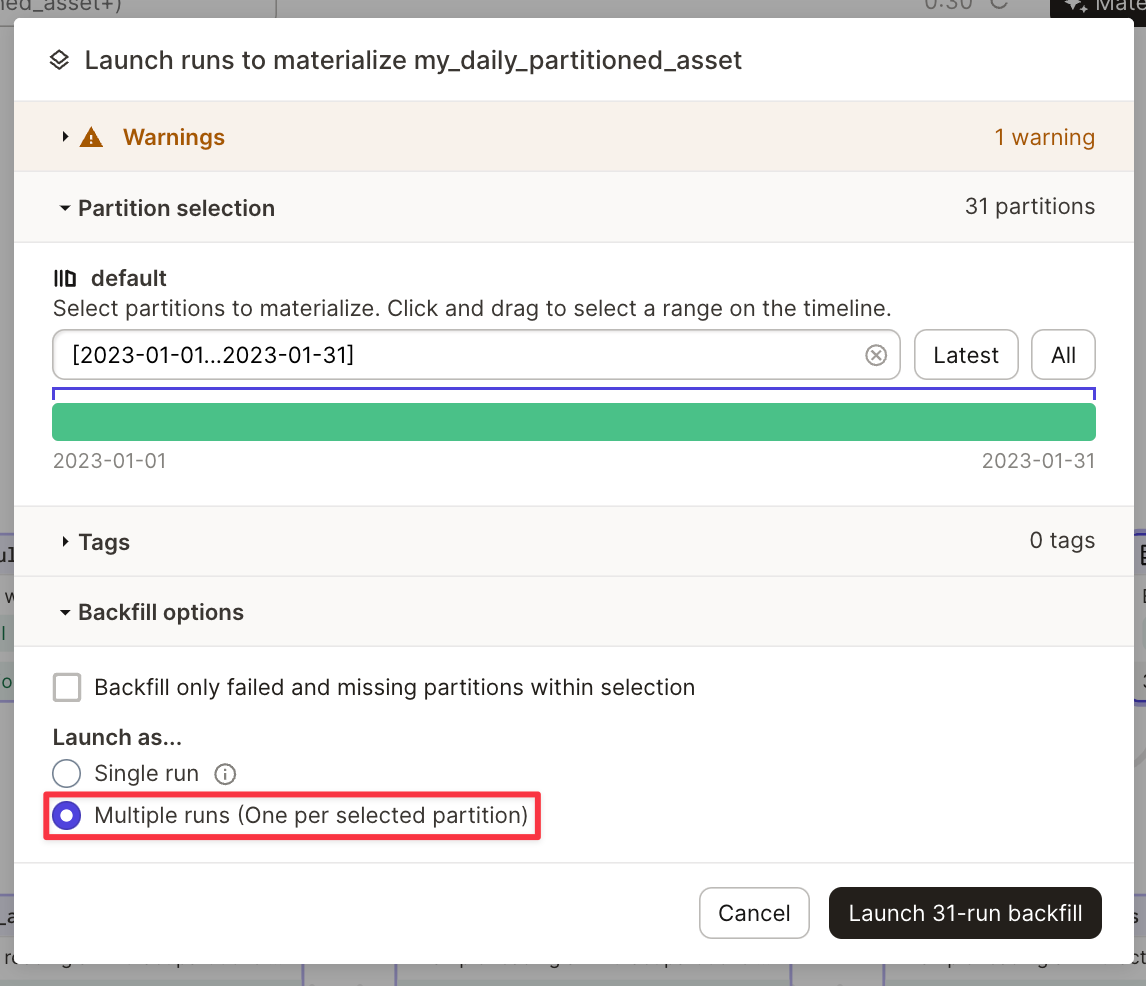
パーティションの使用
インテグレーションは Dagster partitions をネイティブにサポートしています。
以下は、DailyPartitionsDefinition を使用したパーティション化の例です。
@asset(
partitions_def=DailyPartitionsDefinition(start_date="2023-01-01", end_date="2023-02-01"),
name="my_daily_partitioned_asset",
compute_kind="wandb",
metadata={
"wandb_artifact_configuration": {
"type": "dataset",
}
},
)
def create_my_daily_partitioned_asset(context):
partition_key = context.asset_partition_key_for_output()
context.log.info(f"Creating partitioned asset for {partition_key}")
return random.randint(0, 100)
my_daily_partitioned_asset.2023-01-01, my_daily_partitioned_asset.2023-01-02, my_daily_partitioned_asset.2023-01-03)の下に表示されます。複数のディメンションにまたがってパーティション化された asset は、各ディメンションがドット区切り形式で表示されます(例: my_asset.car.blue)。
このインテグレーションでは、1 つの Run 内で複数のパーティションを実体化(materialize)することはできません。asset を実体化するには、複数の Run を実行する必要があります。これは、Dagit で asset を実体化する際に実行できます。 高度な使用法
W&B Artifacts の読み込み
W&B Artifacts の読み込みは、書き込みと同様です。wandb_artifact_configuration と呼ばれる設定辞書を @op または @asset に設定できます。唯一の違いは、出力ではなく入力に設定を行う必要がある点です。
@op の場合、In メタデータ引数を通じて入力メタデータ内に配置されます。Artifact の名前を明示的に渡す必要があります。
@asset の場合、AssetIn メタデータ引数を通じて入力メタデータ内に配置されます。親 asset の名前が一致する必要があるため、Artifact 名を渡す必要はありません。
インテグレーション外で作成された Artifact に依存関係を持たせたい場合は、SourceAsset を使用する必要があります。これにより、常にその asset の最新バージョンが読み込まれます。
以下の例は、さまざまな ops から Artifact を読み込む方法を示しています。
@op から
別の @asset によって作成されたもの
Dagster 外で作成された Artifact
@op から Artifact を読み込む@op(
ins={
"artifact": In(
metadata={
"wandb_artifact_configuration": {
"name": "my_artifact",
}
}
)
},
io_manager_key="wandb_artifacts_manager"
)
def read_artifact(context, artifact):
context.log.info(artifact)
別の @asset によって作成された Artifact を読み込む@asset(
name="my_asset",
ins={
"artifact": AssetIn(
# 入力引数の名前を変更したくない場合は、'key' を削除できます
key="parent_dagster_asset_name",
input_manager_key="wandb_artifacts_manager",
)
},
)
def read_artifact(context, artifact):
context.log.info(artifact)
Dagster 外で作成された Artifact を読み込む:my_artifact = SourceAsset(
key=AssetKey("my_artifact"), # W&B Artifact の名前
description="Artifact created outside Dagster",
io_manager_key="wandb_artifacts_manager",
)
@asset
def read_artifact(context, my_artifact):
context.log.info(my_artifact)
Configuration (設定)
以下の設定は、IO マネージャーが何を収集し、デコレートされた関数に入力として提供するかを示すために使用されます。以下の読み込みパターンがサポートされています。
- Artifact 内に含まれる名前付きオブジェクトを取得するには、
get を使用します。
@asset(
ins={
"table": AssetIn(
key="my_artifact_with_table",
metadata={
"wandb_artifact_configuration": {
"get": "my_table",
}
},
input_manager_key="wandb_artifacts_manager",
)
}
)
def get_table(context, table):
context.log.info(table.get_column("a"))
- Artifact 内に含まれるダウンロード済みファイルのローカルパスを取得するには、
get_path を使用します。
@asset(
ins={
"path": AssetIn(
key="my_artifact_with_file",
metadata={
"wandb_artifact_configuration": {
"get_path": "name_of_file",
}
},
input_manager_key="wandb_artifacts_manager",
)
}
)
def get_path(context, path):
context.log.info(path)
- Artifact オブジェクト全体を取得するには(コンテンツはローカルにダウンロードされます):
@asset(
ins={
"artifact": AssetIn(
key="my_artifact",
input_manager_key="wandb_artifacts_manager",
)
},
)
def get_artifact(context, artifact):
context.log.info(artifact.name)
get: (str) Artifact の相対名にある W&B オブジェクトを取得します。get_path: (str) Artifact の相対名にあるファイルへのパスを取得します。
Serialization configuration (シリアライゼーション設定)
デフォルトでは、インテグレーションは標準の pickle モジュールを使用しますが、一部のオブジェクトはこれと互換性がありません。例えば、yield を含む関数を pickle 化しようとするとエラーが発生します。
より多くの Pickle ベースのシリアライゼーションモジュール (dill, cloudpickle, joblib) をサポートしています。また、シリアライズされた文字列を返すか、Artifact を直接作成することで、ONNX や PMML のようなより高度なシリアライゼーションも使用できます。適切な選択はユースケースに依存します。この主題に関する既存のドキュメントを参照してください。
Pickle ベースのシリアライゼーションモジュール
Pickle 化は安全でないことが知られています。セキュリティが懸念される場合は、W&B オブジェクトのみを使用してください。データに署名し、ハッシュキーを独自のシステムに保存することをお勧めします。より複雑なユースケースについては、お気軽にお問い合わせください。喜んでお手伝いいたします。
wandb_artifact_configuration 内の serialization_module 辞書を通じて、使用するシリアライゼーションを設定できます。Dagster を実行しているマシンでモジュールが利用可能であることを確認してください。
インテグレーションは、その Artifact を読み込む際に、どのシリアライゼーションモジュールを使用すべきかを自動的に判断します。
現在サポートされているモジュールは pickle, dill, cloudpickle, joblib です。
これは、joblib でシリアライズされた “model” を作成し、それを推論に使用する簡略化された例です。
@asset(
name="my_joblib_serialized_model",
compute_kind="Python",
metadata={
"wandb_artifact_configuration": {
"type": "model",
"serialization_module": {
"name": "joblib"
},
}
},
io_manager_key="wandb_artifacts_manager",
)
def create_model_serialized_with_joblib():
# これは本物の ML モデルではありませんが、pickle モジュールでは不可能なことです
return lambda x, y: x + y
@asset(
name="inference_result_from_joblib_serialized_model",
compute_kind="Python",
ins={
"my_joblib_serialized_model": AssetIn(
input_manager_key="wandb_artifacts_manager",
)
},
metadata={
"wandb_artifact_configuration": {
"type": "results",
}
},
io_manager_key="wandb_artifacts_manager",
)
def use_model_serialized_with_joblib(
context: OpExecutionContext, my_joblib_serialized_model
):
inference_result = my_joblib_serialized_model(1, 2)
context.log.info(inference_result) # 出力: 3
return inference_result
高度なシリアライゼーション形式 (ONNX, PMML)
ONNX や PMML のような相互交換ファイル形式を使用するのが一般的です。インテグレーションはこれらの形式をサポートしていますが、Pickle ベースのシリアライゼーションよりも少し手間がかかります。
これらの形式を使用するには 2 つの異なる方法があります。
- モデルを選択した形式に変換し、通常の Python オブジェクトであるかのようにその形式の文字列表現を返します。インテグレーションはその文字列を pickle 化します。その後、その文字列を使用してモデルを再構築できます。
- シリアライズされたモデルを含む新しいローカルファイルを作成し、
add_file 設定を使用してそのファイルでカスタム Artifact を構築します。
これは、ONNX を使用してシリアライズされる Scikit-learn モデルの例です。
import numpy
import onnxruntime as rt
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from dagster import AssetIn, AssetOut, asset, multi_asset
@multi_asset(
compute_kind="Python",
outs={
"my_onnx_model": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "model",
}
},
io_manager_key="wandb_artifacts_manager",
),
"my_test_set": AssetOut(
metadata={
"wandb_artifact_configuration": {
"type": "test_set",
}
},
io_manager_key="wandb_artifacts_manager",
),
},
group_name="onnx_example",
)
def create_onnx_model():
# https://onnx.ai/sklearn-onnx/ を参考に作成
# モデルをトレーニング
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
clr = RandomForestClassifier()
clr.fit(X_train, y_train)
# ONNX 形式に変換
initial_type = [("float_input", FloatTensorType([None, 4]))]
onx = convert_sklearn(clr, initial_types=initial_type)
# アーティファクトを書き出し (model + test_set)
return onx.SerializeToString(), {"X_test": X_test, "y_test": y_test}
@asset(
name="experiment_results",
compute_kind="Python",
ins={
"my_onnx_model": AssetIn(
input_manager_key="wandb_artifacts_manager",
),
"my_test_set": AssetIn(
input_manager_key="wandb_artifacts_manager",
),
},
group_name="onnx_example",
)
def use_onnx_model(context, my_onnx_model, my_test_set):
# https://onnx.ai/sklearn-onnx/ を参考に作成
# ONNX Runtime で予測を実行
sess = rt.InferenceSession(my_onnx_model)
input_name = sess.get_inputs()[0].name
label_name = sess.get_outputs()[0].name
pred_onx = sess.run(
[label_name], {input_name: my_test_set["X_test"].astype(numpy.float32)}
)[0]
context.log.info(pred_onx)
return pred_onx
パーティションの使用
インテグレーションは Dagster partitions をネイティブにサポートしています。
asset の 1 つ、複数、またはすべてのパーティションを選択的に読み込むことができます。
すべてのパーティションは辞書形式で提供され、キーと値はそれぞれパーティションキーと Artifact の内容を表します。
すべてのパーティションを読み込む
特定のパーティションを読み込む
上流の @asset のすべてのパーティションを辞書として読み込みます。この辞書では、キーと値がそれぞれパーティションキーと Artifact の内容に対応します。@asset(
compute_kind="wandb",
ins={"my_daily_partitioned_asset": AssetIn()},
output_required=False,
)
def read_all_partitions(context, my_daily_partitioned_asset):
for partition, content in my_daily_partitioned_asset.items():
context.log.info(f"partition={partition}, content={content}")
AssetIn の partition_mapping 設定により、特定のパーティションを選択できます。この場合、TimeWindowPartitionMapping を採用しています。@asset(
partitions_def=DailyPartitionsDefinition(start_date="2023-01-01", end_date="2023-02-01"),
compute_kind="wandb",
ins={
"my_daily_partitioned_asset": AssetIn(
partition_mapping=TimeWindowPartitionMapping(start_offset=-1)
)
},
output_required=False,
)
def read_specific_partitions(context, my_daily_partitioned_asset):
for partition, content in my_daily_partitioned_asset.items():
context.log.info(f"partition={partition}, content={content}")
metadata は、プロジェクト内のさまざまなアーティファクトパーティションと W&B がどのように相互作用するかを設定します。
metadata オブジェクトには wandb_artifact_configuration というキーが含まれており、さらにその中に partitions というネストされたオブジェクトが含まれています。
partitions オブジェクトは、各パーティションの名前をその設定にマッピングします。各パーティションの設定では、そこからデータを取得する方法を指定できます。これらの設定には、各パーティションの要件に応じて、get, version, alias といった異なるキーを含めることができます。
設定キー
get:
get キーは、データを取得する場所である W&B オブジェクト(Table, Image…)の名前を指定します。version:
version キーは、Artifact の特定のバージョンを取得したい場合に使用されます。alias:
alias キーを使用すると、エイリアスによって Artifact を取得できます。
ワイルドカード設定
ワイルドカード "*" は、設定されていないすべてのパーティションを表します。これは、partitions オブジェクトで明示的に言及されていないパーティションのデフォルト設定を提供します。
例えば、
"*": {
"get": "default_table_name",
},
default_table_name という名前のテーブルからデータが取得されることを意味します。
特定のパーティション設定
特定のパーティションの設定をキーとともに提供することで、ワイルドカード設定を上書きできます。
例えば、
"yellow": {
"get": "custom_table_name",
},
yellow という名前のパーティションについて、ワイルドカード設定を上書きして custom_table_name という名前のテーブルからデータが取得されることを意味します。
バージョニングとエイリアシング
バージョニングとエイリアシングのために、設定で特定の version および alias キーを提供できます。
バージョンの場合、
"orange": {
"version": "v0",
},
orange Artifact パーティションのバージョン v0 からデータを取得します。
エイリアスの場合、
"blue": {
"alias": "special_alias",
},
special_alias というエイリアスを持つ Artifact パーティション(設定内では blue として参照)の default_table_name テーブルからデータを取得します。
高度な使用法
インテグレーションの高度な使用法については、以下の完全なコード例を参照してください。
W&B Launch の使用
アクティブに開発中のベータ版製品です。
Launch に興味がありますか?W&B Launch のカスタマーパイロットプログラムへの参加については、アカウントチームにお問い合わせください。
パイロットカスタマーは、ベータプログラムの対象となるために AWS EKS または SageMaker を使用する必要があります。最終的には、追加のプラットフォームをサポートする予定です。
- Dagster インスタンスで 1 つまたは複数の Launch エージェントを実行する。
- Dagster インスタンス内でローカルの Launch ジョブを実行する。
- オンプレミスまたはクラウドでのリモート Launch ジョブ。
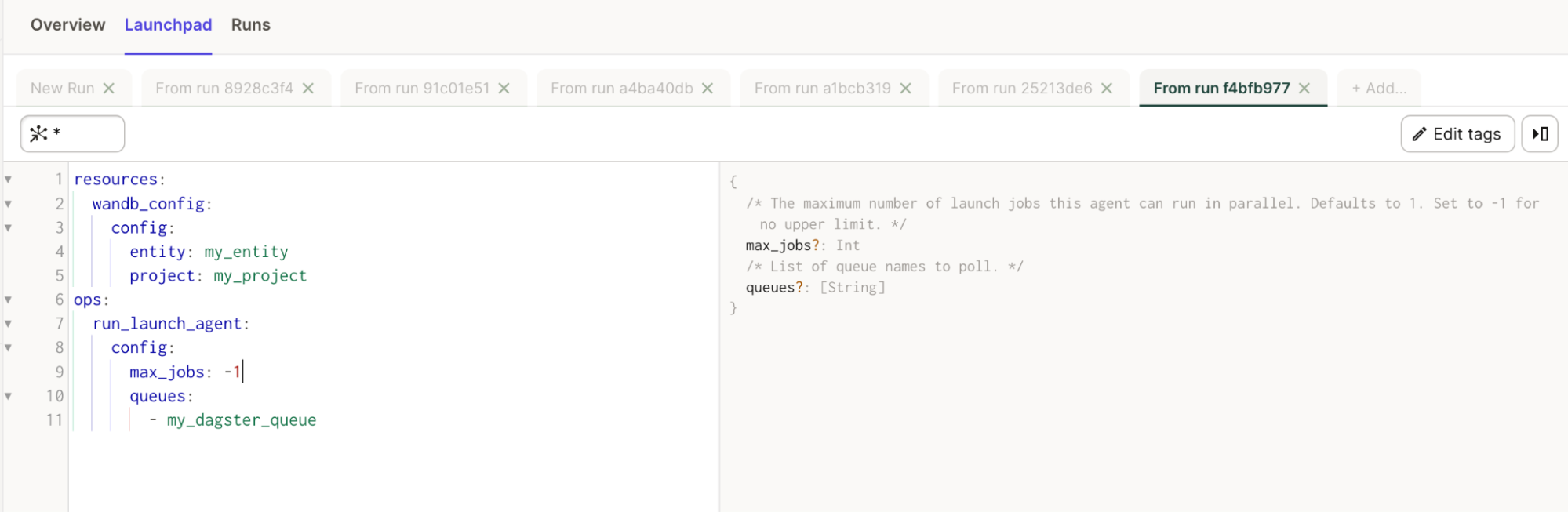
Launch agents
このインテグレーションは、run_launch_agent と呼ばれるインポート可能な @op を提供します。これは Launch Agent を起動し、手動で停止されるまで長時間実行プロセスとして実行します。
エージェントは、Launch キューをポーリングし、ジョブを順番に実行(または実行するために外部サービスにディスパッチ)するプロセスです。
Launch ページ を参照してください。
Launchpad ですべてのプロパティの有用な説明を確認することもできます。
簡単な例
# これを config.yaml に追加します
# あるいは、Dagit の Launchpad または JobDefinition.execute_in_process で設定することもできます
# 参照: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # これをあなたの W&B entity に置き換えてください
project: my_project # これをあなたの W&B プロジェクトに置き換えてください
ops:
run_launch_agent:
config:
max_jobs: -1
queues:
- my_dagster_queue
from dagster_wandb.launch.ops import run_launch_agent
from dagster_wandb.resources import wandb_resource
from dagster import job, make_values_resource
@job(
resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
},
)
def run_launch_agent_example():
run_launch_agent()
Launch jobs
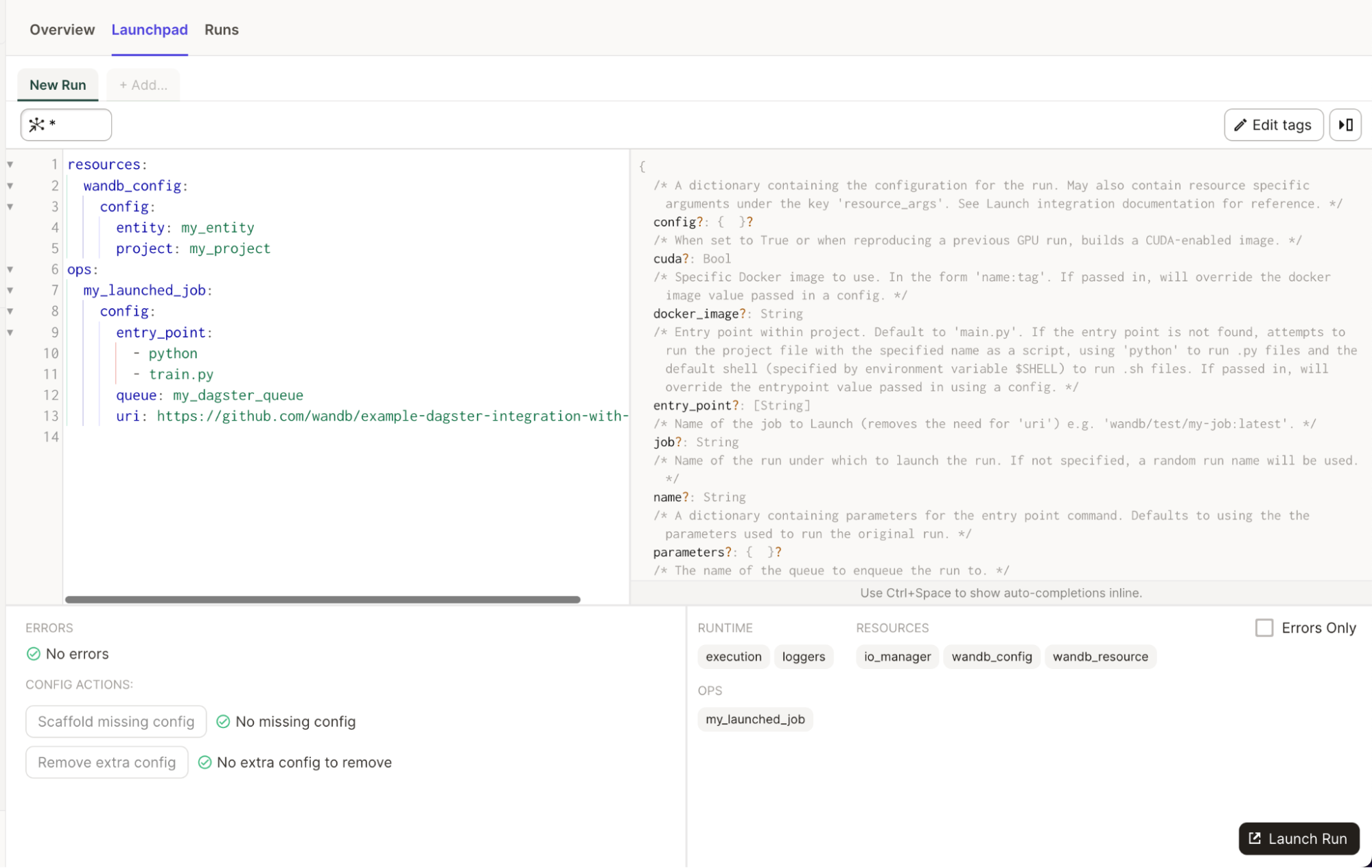
このインテグレーションは、run_launch_job と呼ばれるインポート可能な @op を提供します。これは Launch ジョブを実行します。
Launch ジョブは、実行されるためにキューに割り当てられます。キューを作成するか、デフォルトのものを使用できます。そのキューをリスニングしているアクティブなエージェントがあることを確認してください。Dagster インスタンス内でエージェントを実行することもできますが、Kubernetes で展開可能なエージェントの使用を検討することもできます。
Launch ページ を参照してください。
Launchpad ですべてのプロパティの有用な説明を確認することもできます。
簡単な例
# これを config.yaml に追加します
# あるいは、Dagit の Launchpad または JobDefinition.execute_in_process で設定することもできます
# 参照: https://docs.dagster.io/concepts/configuration/config-schema#specifying-runtime-configuration
resources:
wandb_config:
config:
entity: my_entity # これをあなたの W&B entity に置き換えてください
project: my_project # これをあなたの W&B プロジェクトに置き換えてください
ops:
my_launched_job:
config:
entry_point:
- python
- train.py
queue: my_dagster_queue
uri: https://github.com/wandb/example-dagster-integration-with-launch
from dagster_wandb.launch.ops import run_launch_job
from dagster_wandb.resources import wandb_resource
from dagster import job, make_values_resource
@job(resource_defs={
"wandb_config": make_values_resource(
entity=str,
project=str,
),
"wandb_resource": wandb_resource.configured(
{"api_key": {"env": "WANDB_API_KEY"}}
),
},
)
def run_launch_job_example():
run_launch_job.alias("my_launched_job")() # ジョブにエイリアスを付けて名前を変更します
ベストプラクティス
-
Artifacts の読み書きには IO マネージャーを使用してください。
Artifact.download() や Run.log_artifact() を直接使用することは避けてください。これらのメソッドはインテグレーションによって処理されます。代わりに、Artifact に保存したいデータを返し、残りはインテグレーションに任せてください。このアプローチにより、Artifact のリネージがより正確になります。
-
複雑なユースケースの場合のみ、自分で Artifact オブジェクトを構築してください。
Python オブジェクトと W&B オブジェクトは、ops/assets から返されるべきです。インテグレーションが Artifact のパッケージ化を処理します。
複雑なユースケースでは、Dagster ジョブで直接 Artifact を構築できます。ソースインテグレーションの名前とバージョン、使用された Python バージョン、pickle プロトコルバージョンなどのメタデータを強化するために、Artifact オブジェクトをインテグレーションに渡すことをお勧めします。
-
メタデータを通じて、ファイル、ディレクトリ、外部リファレンスを Artifacts に追加してください。
インテグレーションの
wandb_artifact_configuration オブジェクトを使用して、ファイル、ディレクトリ、または外部リファレンス(Amazon S3, GCS, HTTP…)を追加します。詳細については、Artifact configuration セクション の高度な例を参照してください。
-
Artifact が生成される場合は、@op の代わりに @asset を使用してください。
Artifacts は assets です。Dagster がその資産を維持する場合は、asset を使用することをお勧めします。これにより、Dagit Asset Catalog での可観測性が向上します。
-
Dagster 外で作成された Artifact を消費するには、SourceAsset を使用してください。
これにより、インテグレーションを利用して外部で作成された Artifact を読み取ることができます。そうしないと、インテグレーションによって作成された Artifact しか使用できません。
-
大規模モデルの専用計算リソースでのトレーニングのオーケストレーションには、W&B Launch を使用してください。
小規模なモデルは Dagster クラスター内でトレーニングでき、GPU ノードを持つ Kubernetes クラスターで Dagster を実行することもできます。大規模なモデルのトレーニングには W&B Launch を使用することをお勧めします。これにより、インスタンスの過負荷を防ぎ、より適切な計算リソースへのアクセスが可能になります。
-
Dagster 内で実験管理を行う場合は、W&B Run ID を Dagster Run ID の値に設定してください。
Run を再開可能 にし、かつ W&B Run ID を Dagster Run ID または任意の文字列に設定することをお勧めします。この推奨事項に従うことで、Dagster 内でモデルをトレーニングする際に、W&B メトリクスと W&B Artifacts が同じ W&B Run に保存されるようになります。
W&B Run ID を Dagster Run ID に設定するか、
wandb.init(
id=context.run_id,
resume="allow",
...
)
wandb.init(
id="my_resumable_run_id",
resume="allow",
...
)
@job(
resource_defs={
"io_manager": wandb_artifacts_io_manager.configured(
{"wandb_run_id": "my_resumable_run_id"}
),
}
)
-
大規模な W&B Artifacts の場合は、get または get_path を使用して必要なデータのみを収集してください。
デフォルトでは、インテグレーションは Artifact 全体をダウンロードします。非常に大きな Artifact を使用している場合は、必要な特定のファイルやオブジェクトのみを収集したい場合があります。これにより、速度とリソース使用率が向上します。
-
Python オブジェクトについては、ユースケースに合わせて pickle 化モジュールを適応させてください。
デフォルトでは、W&B インテグレーションは標準の pickle モジュールを使用します。しかし、一部のオブジェクトはこれと互換性がありません。例えば、
yield を含む関数を pickle 化しようとするとエラーが発生します。W&B は、他の Pickle ベースのシリアライゼーションモジュール (dill, cloudpickle, joblib) をサポートしています。
また、シリアライズされた文字列を返すか、Artifact を直接作成することで、ONNX や PMML のようなより高度なシリアライゼーションも使用できます。適切な選択はユースケースに依存します。この主題に関する既存のドキュメントを参照してください。