wandb==0.12.11 から有効になっており、 kfp<2.0.0 が必要です。
サインアップと APIキー の作成
APIキー は、お使いのマシンを W&B に対して認証するために使用されます。 APIキー はユーザープロフィールから生成できます。For a more streamlined approach, create an API key by going directly to User Settings. Copy the newly created API key immediately and save it in a secure location such as a password manager.
- 右上隅にあるユーザープロフィールアイコンをクリックします。
- User Settings を選択し、 API Keys セクションまでスクロールします。
wandb ライブラリのインストールとログイン
ローカル環境に wandb ライブラリをインストールしてログインするには:
- Command Line
- Python
- Python notebook
-
WANDB_API_KEY環境変数 に APIキー を設定します。 -
wandbライブラリをインストールしてログインします。
コンポーネントへのデコレータ追加
@wandb_log デコレータを追加し、通常通りコンポーネントを作成します。これにより、パイプラインを実行するたびに、入力/出力 パラメータ と アーティファクト が W&B に自動的に ログ 記録されます。
コンテナへの環境変数の受け渡し
コンテナに対して明示的に 環境変数 を渡す必要がある場合があります。双方向のリンクを有効にするには、WANDB_KUBEFLOW_URL 環境変数 に Kubeflow Pipelines インスタンスのベース URL(例: https://kubeflow.mysite.com)を設定してください。
プログラムによるデータへのアクセス
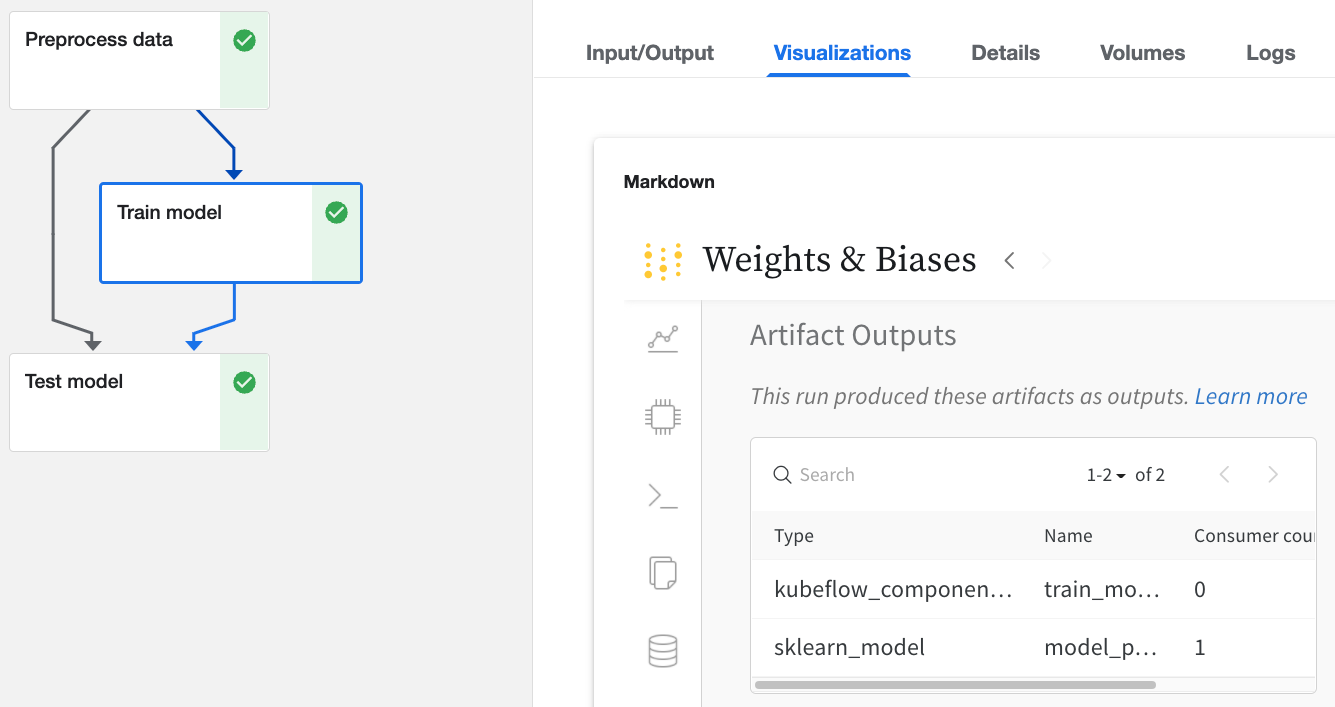
Kubeflow Pipelines UI 経由
W&B で ログ 記録された Kubeflow Pipelines UI 上の任意の Run をクリックします。- 入出力の詳細は、
Input/OutputタブおよびML Metadataタブで確認できます。 Visualizationsタブから W&B ウェブアプリを表示できます。
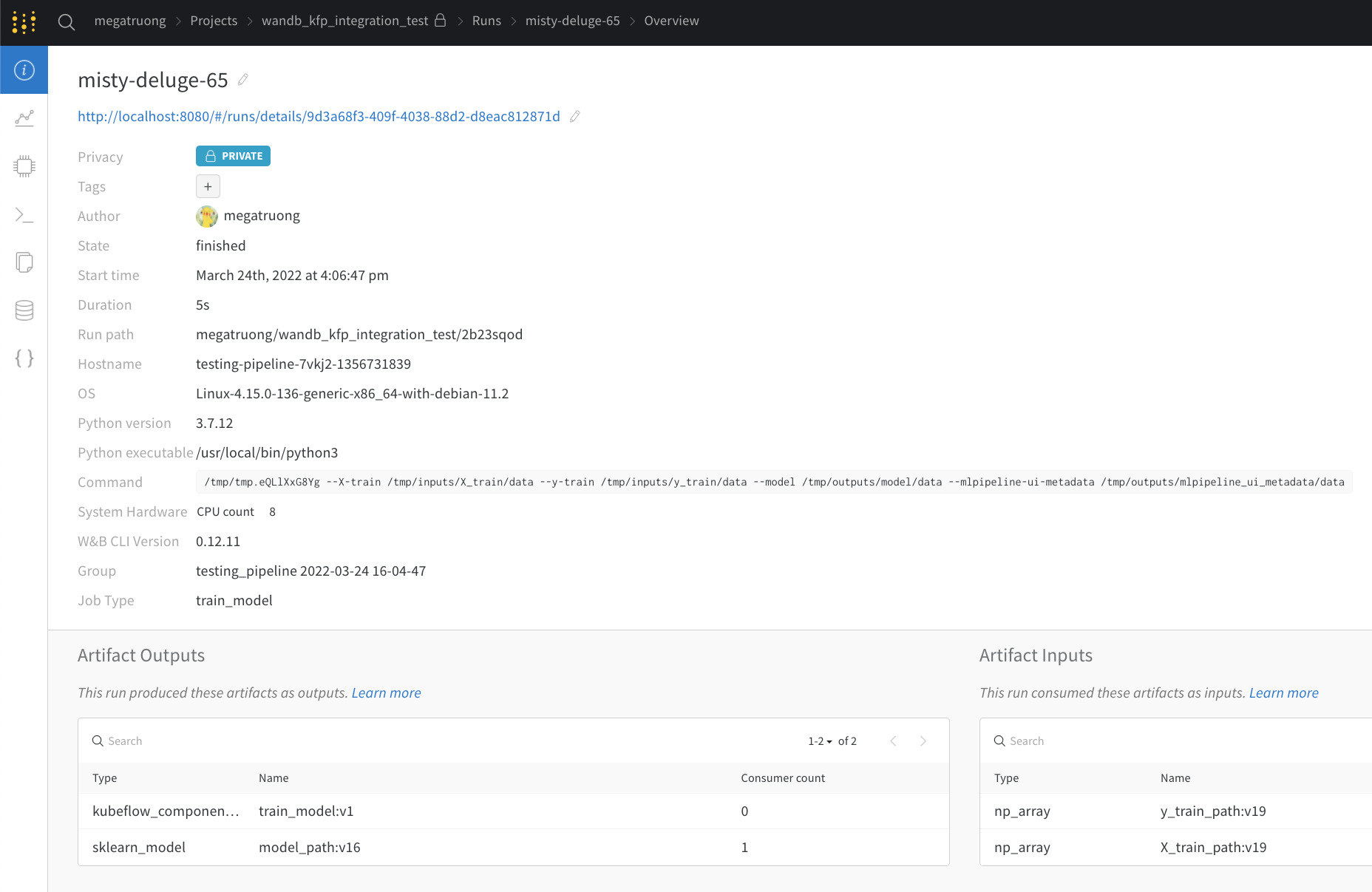
ウェブアプリ UI 経由
ウェブアプリ UI には、 Kubeflow Pipelines のVisualizations タブと同じ内容が表示されますが、より広い画面で操作できます。ウェブアプリ UI についての詳細は こちら をご覧ください。

Public API 経由(プログラムによるアクセス)
- プログラムによる アクセス については、 Public API ドキュメント を参照してください。
Kubeflow Pipelines から W&B へのコンセプトマッピング
Kubeflow Pipelines のコンセプトと W&B の対応表は以下の通りです。| Kubeflow Pipelines | W&B | W&B内での場所 |
|---|---|---|
| Input Scalar | config | Overviewタブ |
| Output Scalar | summary | Overviewタブ |
| Input Artifact | Input Artifact | Artifactsタブ |
| Output Artifact | Output Artifact | Artifactsタブ |
きめ細かなログ記録
ログ 記録をより詳細に制御したい場合は、コンポーネント内でwandb.log や wandb.log_artifact を呼び出すことができます。
明示的な wandb.log_artifacts の呼び出し
以下の例では、 モデル を トレーニング しています。 @wandb_log デコレータは関連する入出力を自動的に追跡します。 トレーニング プロセスを ログ 記録したい場合は、次のように明示的に ログ を追加できます: