LLM Evaluation Jobs is in Preview for W&B Multi-tenant Cloud. Compute is free during the preview period. Learn more
仕組み
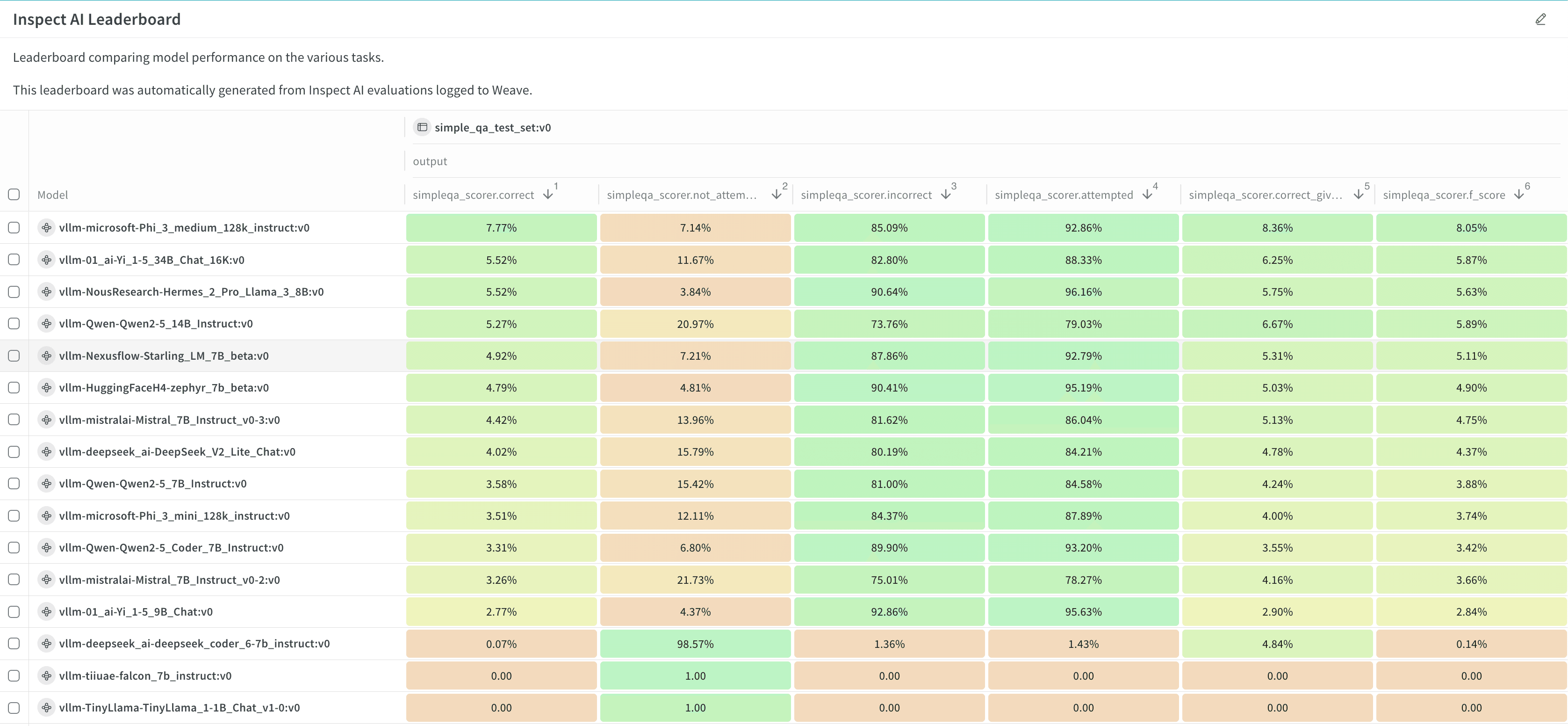
以下の数ステップで、モデルの チェックポイント や、パブリックにアクセス可能な OpenAI 互換のホスト型 モデル を 評価 できます。- W&B Models で評価ジョブを セットアップ します。ベンチマークと、リーダーボードを生成するかどうかなどの 設定 を定義します。
- 評価ジョブを Launch します。
- 結果 とリーダーボードを表示・分析します。
次のステップ
詳細
料金
LLM Evaluation Jobs は、完全に管理された CoreWeave の計算リソース上で、一般的なベンチマークに対して モデル の チェックポイント やホスト型 API を 評価 します。インフラストラクチャー を管理する必要はありません。支払いは消費したリソースに対してのみ発生し、アイドル時間には発生しません。料金は「計算リソース」と「ストレージ」の 2 つの要素で構成されます。計算リソースはパブリックプレビュー期間中は無料です。一般提供開始時に料金をアナウンス予定です。保存される 結果 には、Models の Runs に保存された メトリクス やサンプルごとの Traces が含まれます。ストレージ料金は データ 量に基づき、月単位で請求されます。プレビュー期間中、LLM Evaluation Jobs はマルチテナントの クラウド でのみ利用可能です。詳細は 料金ページ を参照してください。ジョブの制限
個々の評価ジョブには以下の制限があります。- 評価対象の モデル の最大サイズは、コンテキストを含めて 86 GB です。
- 各ジョブは 2 枚の GPU に制限されています。
要件
- モデル の チェックポイント を 評価 するには、モデル の重みが VLLM 互換の Artifacts としてパッケージ化されている必要があります。詳細とサンプル コード については、例:モデルの準備 を参照してください。
- OpenAI 互換 モデル を 評価 するには、その モデル がパブリックな URL でアクセス可能である必要があり、また、組織または Team の管理者が認証用の APIキー を Team Secret として 設定 する必要があります。
- 一部のベンチマークでは、スコアリングに OpenAI モデル を使用します。これらのベンチマークを実行するには、組織または Team の管理者が、必要な APIキー を Team Secret として 設定 する必要があります。評価ベンチマークカタログ で、ベンチマークにこの要件があるかどうかを確認してください。
- 一部のベンチマークでは、Hugging Face のゲート付き データセット への アクセス が必要です。これらのベンチマークのいずれかを実行するには、組織または Team の管理者が Hugging Face でゲート付き データセット への アクセス をリクエストし、Hugging Face ユーザー アクセス トークンを生成して、それを Team Secret として 設定 する必要があります。評価ベンチマークカタログ で、ベンチマークにこの要件があるかどうかを確認してください。