このチュートリアルは、複数の GPU を搭載したマシンに直接アクセスできるユーザーを対象としています。クラウドマシンをレンタルしているユーザー向けではありません。クラウドマシン上に minikube クラスターをセットアップしたい場合は、W&B はご利用のクラウドプロバイダーを使用して GPU サポート付きの Kubernetes クラスターを作成することをお勧めします。例えば、AWS、Google Cloud、Azure、Coreweave、およびその他のクラウドプロバイダーには、GPU サポート付きの Kubernetes クラスターを作成するためのツールが用意されています。単一の GPU を搭載したマシン上で GPU スケジューリングのために minikube クラスターをセットアップしたい場合は、W&B は Launch Docker queue の使用をお勧めします。このチュートリアルを読み進めることも可能ですが、GPU スケジューリングの有用性はそれほど高くありません。
背景
NVIDIA container toolkit により、Docker 上で GPU 対応のワークフローを実行することが容易になりました。1つの制限は、ボリュームによる GPU スケジューリングのネイティブサポートが欠けていることです。docker run コマンドで GPU を使用する場合、ID で特定の GPU を指定するか、存在するすべての GPU を要求する必要があり、多くの分散型 GPU ワークロードの実装が困難でした。Kubernetes はボリューム要求によるスケジューリングをサポートしていますが、ローカルの Kubernetes クラスターで GPU スケジューリングをセットアップするには、最近までかなりの時間と労力が必要でした。シングルノードの Kubernetes クラスターを実行するための最も人気のあるツールの1つである Minikube は、最近 GPU スケジューリングのサポート をリリースしました。このチュートリアルでは、マルチ GPU マシン上に Minikube クラスターを作成し、W&B Launch を使用してクラスターに並列の Stable Diffusion 推論ジョブを起動します。
事前準備
開始する前に、以下が必要になります。- W&B アカウント。
- 以下がインストールされ実行されている Linux マシン:
- Docker ランタイム
- 使用したい GPU のドライバー
- Nvidia container toolkit
このチュートリアルのテストおよび作成には、4枚の NVIDIA Tesla T4 GPU を接続した Google Cloud Compute Engine の
n1-standard-16 インスタンスを使用しました。Launch ジョブ用のキューを作成する
まず、Launch ジョブ用の Launch キューを作成します。- wandb.ai/launch(プライベート W&B サーバーを使用している場合は
<your-wandb-url>/launch)に移動します。 - 画面の右上の隅にある青い Create a queue ボタンをクリックします。画面の右側からキュー作成ドロワーがスライドして表示されます。
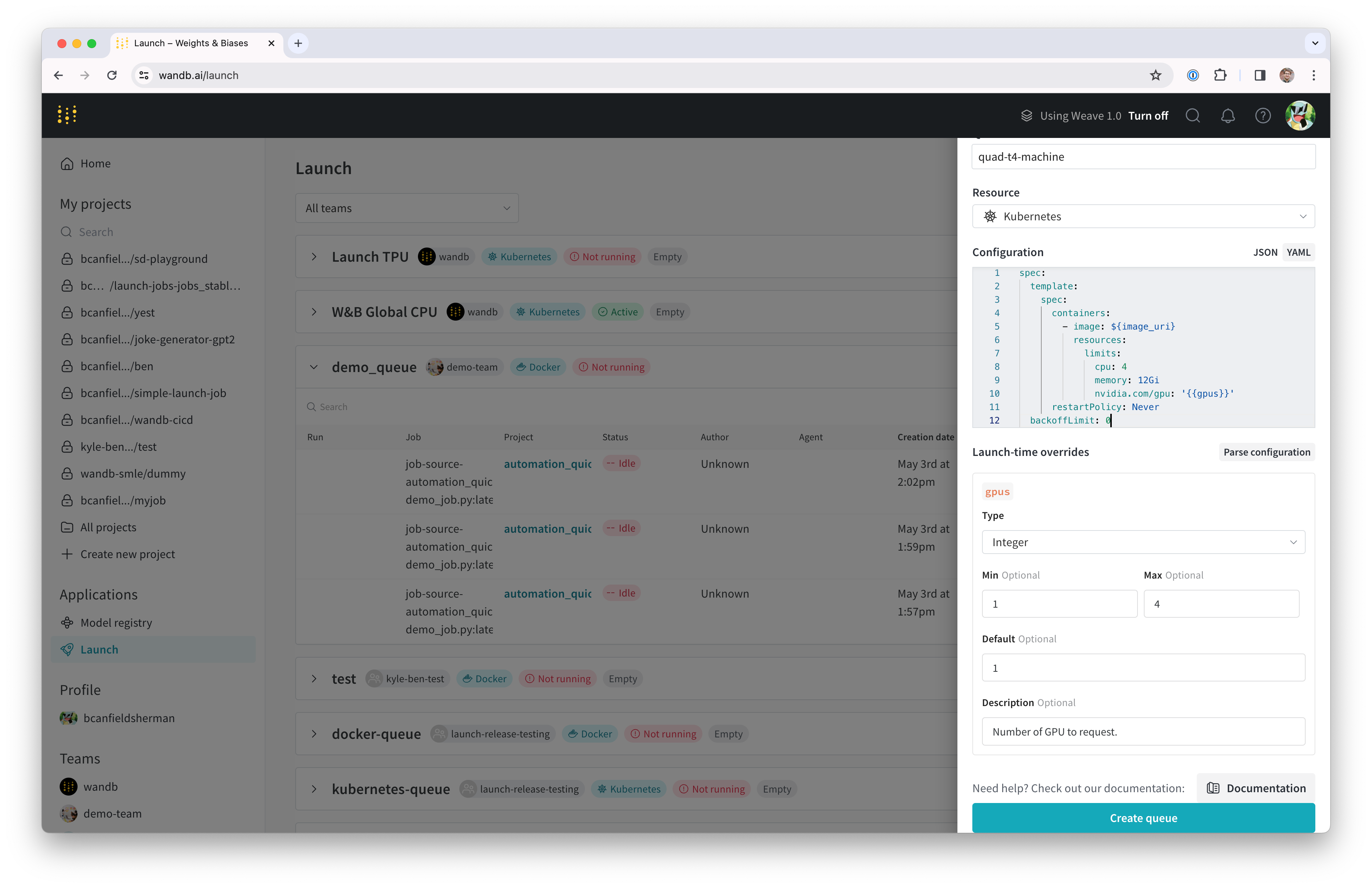
- Entity を選択し、名前を入力して、キューのタイプとして Kubernetes を選択します。
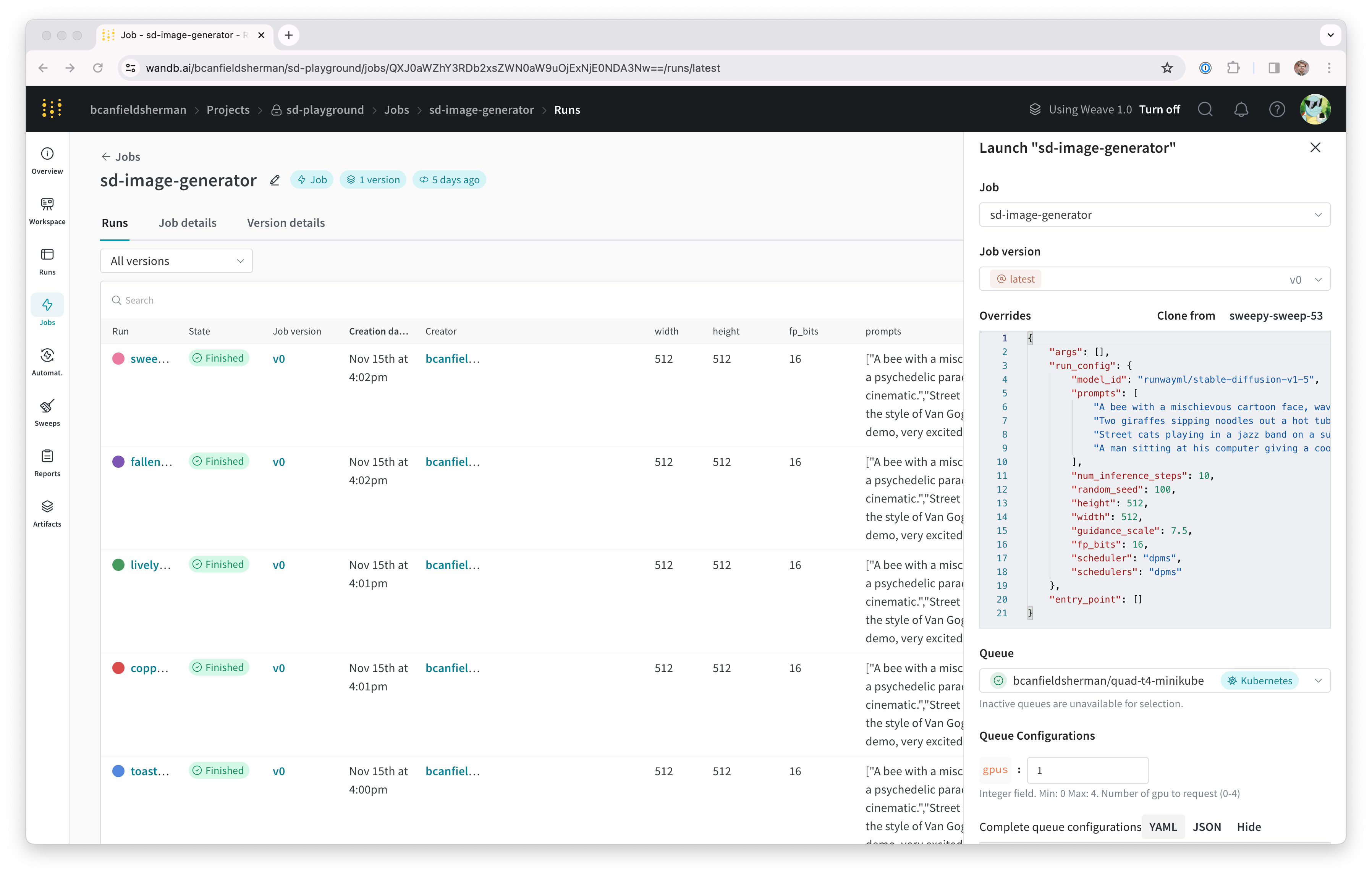
- ドロワーの Config セクションは、Launch キューの Kubernetes ジョブ仕様 を入力する場所です。このキューから起動される Runs はすべてこのジョブ仕様を使用して作成されるため、必要に応じてこの設定を変更してジョブをカスタマイズできます。このチュートリアルでは、以下のサンプル設定を YAML または JSON としてキュー設定にコピー&ペーストしてください。
- YAML
- JSON
${image_uri} と {{gpus}} 文字列は、キュー設定で使用できる2種類の変数テンプレートの例です。${image_uri} テンプレートは、エージェントによって起動されるジョブのイメージ URI に置き換えられます。{{gpus}} テンプレートは、ジョブを送信する際に Launch UI、CLI、または SDK からオーバーライドできるテンプレート変数を作成するために使用されます。これらの値はジョブ仕様内に配置され、ジョブが使用するイメージと GPU リソースを制御する正しいフィールドを修正します。
- Parse configuration ボタンをクリックして、
gpusテンプレート変数のカスタマイズを開始します。 - Type を
Integerに設定し、Default、Min、Max を任意の値に設定します。テンプレート変数の制約に違反する Run をこのキューに送信しようとすると拒否されます。
- Create queue をクリックしてキューを作成します。新しいキューのキューページにリダイレクトされます。
Docker + NVIDIA CTK のセットアップ
すでにマシンに Docker と Nvidia container toolkit がセットアップされている場合は、このセクションをスキップできます。 システムへの Docker コンテナエンジンのセットアップ手順については、Docker のドキュメント を参照してください。 Docker がインストールされたら、Nvidia のドキュメントの指示に従って Nvidia container toolkit をインストールします。 コンテナランタイムが GPU にアクセスできることを確認するには、以下を実行します。nvidia-smi の出力が表示されるはずです。例えば、私たちのセットアップでは出力は以下のようになります。
Minikube のセットアップ
Minikube の GPU サポートにはバージョンv1.32.0 以降が必要です。最新のインストールヘルプについては、Minikube のインストールドキュメント を参照してください。このチュートリアルでは、以下のコマンドを使用して最新の Minikube リリースをインストールしました。
Launch エージェントの起動
新しいクラスター用の Launch エージェントは、wandb launch-agent を直接呼び出すか、W&B が管理する helm チャート を使用してデプロイすることで開始できます。
このチュートリアルでは、ホストマシン上でエージェントを直接実行します。
コンテナの外でエージェントを実行することは、ローカルの Docker ホストを使用してクラスターで実行するイメージをビルドできることも意味します。
wandb login を実行するか、WANDB_API_KEY 環境変数を設定します。
エージェントを開始するには、このコマンドを実行します。
ジョブの起動
エージェントにジョブを送信してみましょう。W&B アカウントにログインしているターミナルから、シンプルな “hello world” を起動できます。(オプション) NFS によるモデルとデータのキャッシュ
ML ワークロードでは、複数のジョブが同じデータにアクセスできるようにしたいことがよくあります。例えば、データセットやモデルの重みのような大きなアセットを繰り返しダウンロードするのを避けるために、共有キャッシュを持たせたい場合があります。Kubernetes は Persistent Volumes と Persistent Volume Claims を通じてこれをサポートしています。Persistent Volumes を使用して Kubernetes ワークロードにvolumeMounts を作成し、共有キャッシュへの直接的なファイルシステムアクセスを提供できます。
このステップでは、モデルの重みの共有キャッシュとして使用できるネットワークファイルシステム (NFS) サーバーをセットアップします。最初のステップは、NFS のインストールと設定です。このプロセスはオペレーティングシステムによって異なります。私たちの VM は Ubuntu を実行しているため、nfs-kernel-server をインストールし、/srv/nfs/kubedata にエクスポートを設定しました。
nfs-persistent-volume.yaml という名前のファイルにコピーし、希望するボリューム容量とクレーム要求を記入してください。PersistentVolume.spec.capcity.storage フィールドは、基礎となるボリュームの最大サイズを制御します。PersistentVolumeClaim.spec.resources.requests.stroage は、特定のクレームに割り当てられるボリューム容量を制限するために使用できます。私たちのユースケースでは、それぞれに同じ値を使用するのが妥当です。
volumes と volumeMounts を追加する必要があります。Launch 設定を編集するには、wandb.ai/launch(wandb サーバーのユーザーは <your-wandb-url>/launch)に戻り、キューを見つけてキューページをクリックし、Edit config タブをクリックします。元の設定は以下のように修正できます。
- YAML
- JSON
/root/.cache に NFS がマウントされます。コンテナが root 以外のユーザーとして実行される場合は、マウントパスの調整が必要になります。Huggingface のライブラリと W&B Artifacts はどちらもデフォルトで $HOME/.cache/ を使用するため、ダウンロードは一度だけで済むはずです。
Stable Diffusion で遊ぶ
新しいシステムをテストするために、Stable Diffusion の推論パラメータを試してみましょう。 デフォルトのプロンプトと適切なパラメータでシンプルな Stable Diffusion 推論ジョブを実行するには、以下を実行します。wandb/job_stable_diffusion_inference:main をキューに送信します。
エージェントがジョブを取得しクラスターでの実行をスケジュールすると、接続環境によってはイメージのプルに時間がかかる場合があります。
ジョブのステータスは、wandb.ai/launch(wandb サーバーのユーザーは <your-wandb-url>/launch)のキューページで確認できます。
Run が終了すると、指定したプロジェクトにジョブアーティファクトが作成されているはずです。
プロジェクトのジョブページ (<project-url>/jobs) をチェックして、ジョブアーティファクトを確認できます。デフォルト名は job-wandb_job_stable_diffusion_inference になるはずですが、ジョブ名の横にある鉛筆アイコンをクリックして、ジョブページで好きな名前に変更できます。
これで、このジョブを使用してクラスター上でさらに Stable Diffusion の推論を実行できます。
ジョブページから、右上隅にある Launch ボタンをクリックして、新しい推論ジョブを設定し、キューに送信できます。ジョブ設定ページには元の Run のパラメータが事前入力されていますが、Launch ドロワーの Overrides セクションで値を修正することで、好きなように変更できます。