
このノートブックで学べること
このチュートリアルでは、W&BをPyTorchコードに統合し、パイプラインに 実験管理 機能を追加する方法を紹介します。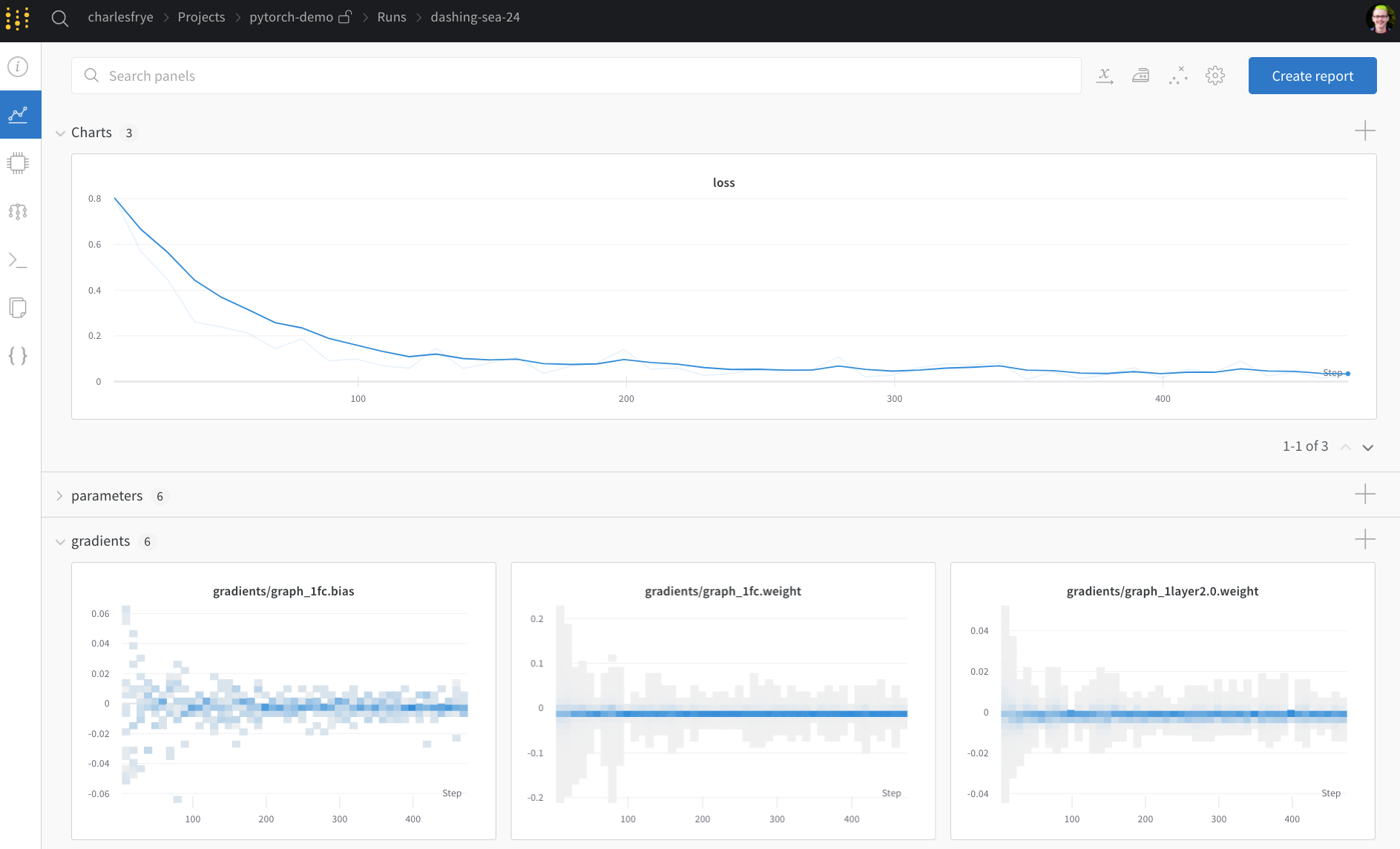
インストール、インポート、ログイン
ステップ 0: W&Bのインストール
まずはライブラリを入手する必要があります。wandb は pip を使って簡単にインストールできます。
ステップ 1: W&Bのインポートとログイン
Webサービスにデータをログ記録するには、ログインする必要があります。 W&Bを初めて使用する場合は、表示されるリンクから無料アカウントを登録してください。実験とパイプラインの定義
wandb.init でメタデータとハイパーパラメーターをトラックする
プログラム的にまず行うのは、実験の定義です。
ハイパーパラメーターは何か? この run に関連付けられている メタデータ は何か?
これらの情報を config 辞書(または同様の オブジェクト )に保存し、必要に応じてアクセスするのが一般的な ワークフロー です。
この例では、一部の ハイパーパラメーター のみを変更可能にし、残りはハードコードしています。しかし、 モデル のあらゆる部分を config に含めることができます。
また、MNIST データセット と 畳み込み アーキテクチャー を使用しているという メタデータ も含めています。後で同じ プロジェクト 内で CIFAR の全結合 アーキテクチャー を扱う場合などに、これによって Runs を区別しやすくなります。
- モデル、および関連する データ と オプティマイザー を
make(作成)し、 - それに応じてモデルを
train(トレーニング)し、最後に test(テスト)してトレーニングの結果を確認します。
wandb.init のコンテキスト内で行われることです。この関数を呼び出すことで、コードとW&Bの サーバー 間の通信がセットアップされます。
config 辞書を wandb.init に渡すと、それらの情報が即座にログ記録されます。これにより、実験で使用した ハイパーパラメーター の値を常に把握できます。
選択してログに記録した値が常に モデル で使用されることを確実にするために、オブジェクトのコピーである run.config を使用することをお勧めします。以下の make の定義で例を確認してください。
補足: 私たちはコードを別 プロセス で実行するように配慮しています。そのため、こちら側で問題が発生しても(巨大な海獣がデータセンターを襲ったとしても)、お客様のコードがクラッシュすることはありません。問題が解決した後(クラーケンが深海に戻った後など)に、wandb sync を使ってデータをログに記録できます。
データのロードとモデルの定義
次に、データのロード方法とモデルの構成を指定する必要があります。 この部分は非常に重要ですが、wandb がなくても変わらない部分ですので、詳細は省略します。
wandb を使っても何も変わらないため、ここでは標準的な ConvNet アーキテクチャー を使用します。
自由にモデルを調整して実験を試してみてください。すべての 結果 は wandb.ai にログ記録されます。
トレーニングロジックの定義
model_pipeline を進めて、train(トレーニング)の方法を指定しましょう。
ここでは watch と log という2つの wandb 関数が登場します。
run.watch() で勾配を、それ以外を run.log() でトラックする
run.watch は、トレーニングの log_freq ステップごとに、モデルの 勾配(gradients)と パラメータ をログ記録します。
トレーニングを開始する前にこれを呼び出すだけです。
残りのトレーニングコードは同じです。 エポック と バッチ をイテレートし、 forward pass と backward pass を実行して オプティマイザー を適用します。
run.log() に渡します。
run.log() は文字列を キー とする 辞書 を期待します。これらの文字列は、ログ記録される値である オブジェクト を識別します。オプションで、現在どのトレーニング step にいるかをログ記録することもできます。
補足: 私はモデルが処理したサンプル数を使用するのが好きです。これにより、バッチサイズ が異なっても比較が容易になります。もちろん、生のステップ数やバッチ数を使用することもできます。長時間のトレーニングの場合は、 epoch ごとにログを記録するのも理にかなっています。
テストロジックの定義
モデルのトレーニングが終わったら、テストを行います。プロダクションからの新しいデータに対して実行したり、厳選されたサンプルに適用したりします。(オプション) run.save() の呼び出し
これは、モデルの アーキテクチャー と最終的な パラメータ をディスクに保存する絶好の機会でもあります。互換性を最大限に高めるために、モデルを Open Neural Network eXchange (ONNX) 形式 で export(エクスポート)します。
そのファイル名を run.save() に渡すと、モデル パラメータ がW&Bの サーバー に保存されます。どの .h5 や .pb がどのトレーニング Runs に対応するか分からなくなることはもうありません。
モデルの保存、 バージョン管理 、配布のためのより高度な wandb 機能については、 Artifacts ツール をご覧ください。
トレーニングを実行し、wandb.ai でメトリクスをライブで確認する
パイプライン全体を定義し、数行のW&Bコードを挿入したので、完全にトラックされた実験を実行する準備が整いました。 いくつかのリンクが表示されます: ドキュメント、 プロジェクト 内のすべての Runs を整理する Project ページ、そしてこの run の 結果 が保存される Run ページです。 Run ページに移動して、以下のタブを確認してください:- Charts: トレーニング中にモデルの 勾配 、 パラメータ 値、損失がログ記録されます。
- System: ディスク I/O 使用率、 CPU および GPU メトリクス(温度の上昇を確認してください)など、さまざまなシステムメトリクスが含まれます。
- Logs: トレーニング中に標準出力に送られたすべての内容のコピーが含まれます。
- Files: トレーニング完了後、
model.onnxをクリックして Netron モデルビューアー でネットワークを表示できます。
with wandb.init ブロックを抜けると、セルの出力に 結果 のサマリーも表示されます。
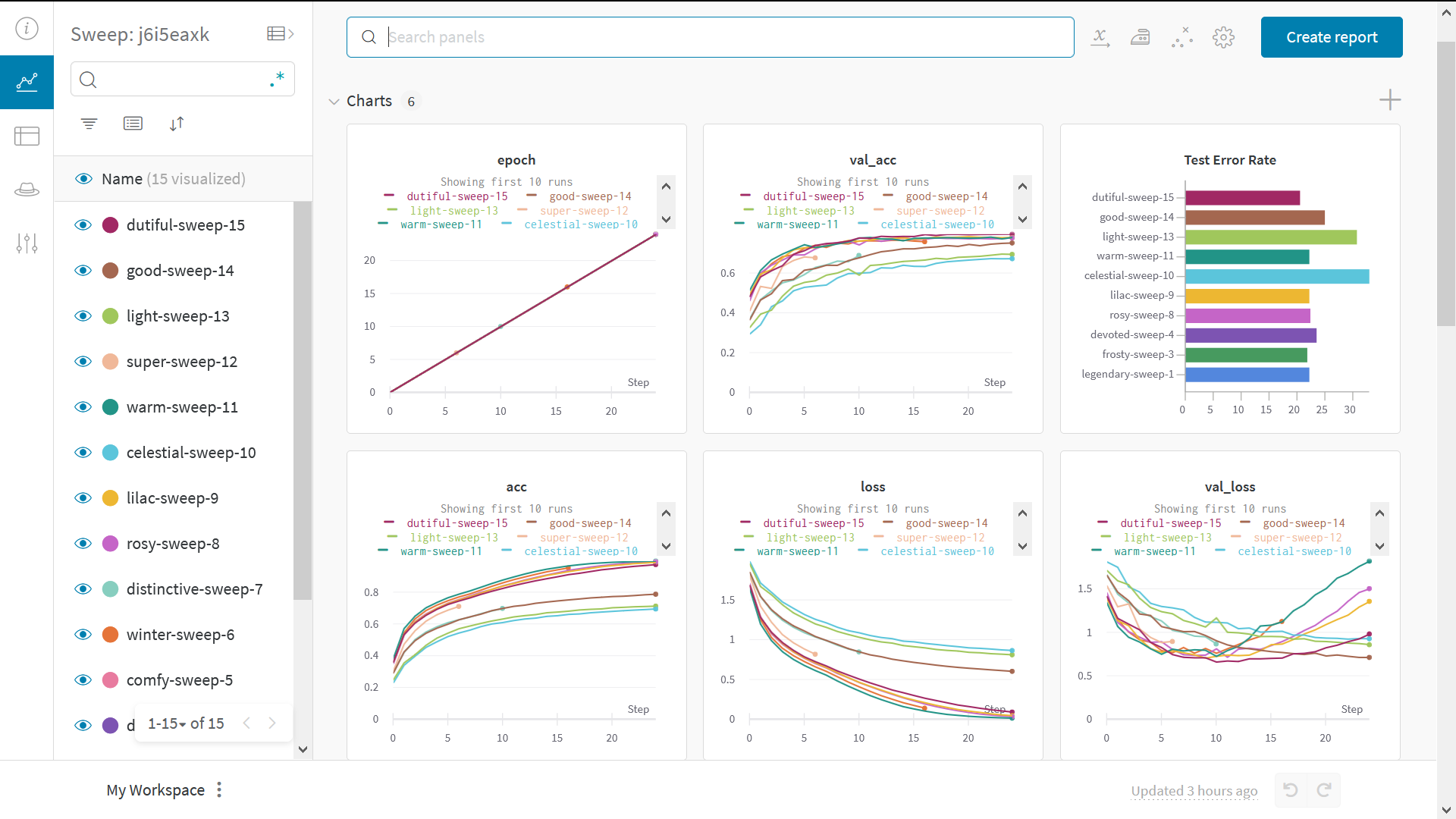
Sweeps でハイパーパラメーターをテストする
この例では1セットの ハイパーパラメーター のみを確認しました。しかし、多くの機械学習 ワークフロー において重要なのは、複数の ハイパーパラメーター を反復試行することです。 W&B Sweeps を使用すると、 ハイパーパラメーター テストを自動化し、可能な モデル や最適化戦略の空間を探索できます。 W&B Sweeps を使用したハイパーパラメーター最適化の Colabノートブック をご覧ください。 W&Bでの ハイパーパラメーター探索(sweep) の実行は非常に簡単です。シンプルな3つのステップで行えます。- sweep を定義する: 探索する パラメータ 、探索戦略、最適化 メトリクス などを指定する 辞書 または YAML ファイル を作成します。
-
sweep を初期化する:
sweep_id = wandb.sweep(sweep_config) -
sweep agent を実行する:
wandb.agent(sweep_id, function=train)
ギャラリー
W&Bでトラック・可視化された プロジェクト の例を ギャラリー → でご覧いただけます。高度なセットアップ
- 環境変数: 環境変数に APIキー を設定して、管理された クラスター でトレーニングを実行できます。
- オフラインモード:
dryrunモードを使用してオフラインでトレーニングし、後で 結果 を同期できます。 - オンプレミス(On-prem): 自社 インフラストラクチャー 内の プライベートクラウド やエアギャップのある サーバー にW&Bをインストールできます。個人研究者からエンタープライズチームまで利用可能なローカルインストールを提供しています。
- Sweeps: チューニングのための軽量な ツール を使用して、 ハイパーパラメーター 探索を迅速にセットアップできます。