early_stopping_rounds は何回にすべきか? ツリー の max_depth はどのくらいが適切か?
高次元の ハイパーパラメーター 空間を探索して最もパフォーマンスの高い モデル を見つけ出す作業は、すぐに手に負えなくなることがあります。
Hyperparameter Sweeps は、 モデル 同士を競わせ、勝者を決定するための整理された効率的な手段を提供します。
これは、 ハイパーパラメーター の 値 の組み合わせを自動的に探索し、最適な 値 を見つけ出すことで実現されます。
このチュートリアルでは、W&B を使用して 3 つの簡単なステップで XGBoost モデル に対して高度な ハイパーパラメーター探索 を実行する方法を説明します。
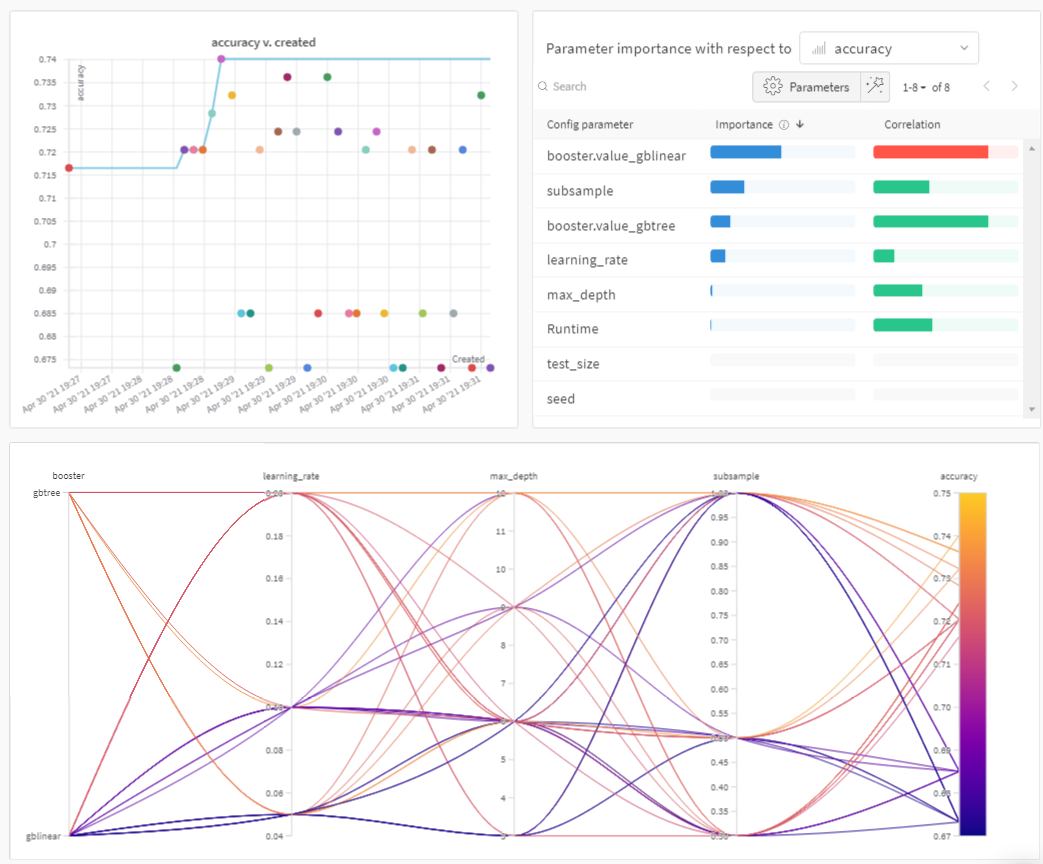
まずは、以下のプロットをチェックしてみてください:
Sweeps: 概要
W&B で ハイパーパラメーター探索 を実行するのは非常に簡単です。以下の 3 つのステップに従うだけです:- sweep を定義する: どの パラメータ を探索するか、どの探索戦略を使用するか、どの メトリクス を最適化するかを指定する 辞書 形式の オブジェクト を作成します。
-
sweep を初期化する: 1 行の コード で sweep を初期化し、 sweep configuration の 辞書 を渡します:
sweep_id = wandb.sweep(sweep_config) -
sweep agent を実行する: これも 1 行の コード で実行できます。
wandb.agent()を呼び出し、sweep_idと共に、 モデル アーキテクチャー を定義して トレーニング を行う関数を渡します:wandb.agent(sweep_id, function=train)
リソース
1. Sweep を定義する
W&B Sweeps では、わずか数行の コード で、思い通りに sweep を 設定 するための強力なレバーが提供されます。 sweep 設定 は 辞書または YAML ファイル として定義できます。 主な設定項目を見ていきましょう:- Metric (メトリクス): これは sweep が最適化しようとする指標です。 メトリクス には
name( トレーニングスクリプト で ログ を記録する名前) とgoal(maximize(最大化) またはminimize(最小化)) を指定できます。 - Search Strategy (探索戦略):
"method"キーを使用して指定します。 Sweeps ではいくつかの異なる探索戦略をサポートしています。 - Grid Search (グリッド検索): ハイパーパラメーター の 値 のあらゆる組み合わせを反復します。
- Random Search (ランダム検索): ランダムに選択された ハイパーパラメーター の 値 の組み合わせを反復します。
- Bayesian Search (ベイズ探索): ハイパーパラメーター と メトリクス スコアの確率をマッピングする確率的 モデル を作成し、 メトリクス を改善する可能性が高い パラメータ を選択します。 ベイズ最適化 の目的は、 ハイパーパラメーター の 値 の選択により多くの時間をかける代わりに、試行する ハイパーパラメーター の 値 の回数を減らすことにあります。
- Parameters (パラメータ): ハイパーパラメーター 名と、各反復でその 値 を取得するための 離散値 、範囲、または分布を含む 辞書 です。
2. Sweep を初期化する
wandb.sweep を呼び出すと、 Sweep Controller が起動します。これは、問い合わせてきたものに対して parameters の 設定 を提供し、 wandb の ログ 記録を通じて metrics のパフォーマンスが返されるのを待機する集中型 プロセス です。
トレーニングプロセスの定義
sweep を実行する前に、 モデル を作成して トレーニング する関数を定義する必要があります。これは、 ハイパーパラメーター の 値 を受け取り、 メトリクス を出力する関数です。 また、 スクリプト にwandb を統合する必要があります。主に 3 つのコンポーネントがあります:
wandb.init(): 新しい W&B Run を初期化します。各 Run は トレーニングスクリプト の 1 回の実行を指します。run.config: すべての ハイパーパラメーター を 設定 オブジェクト に保存します。これにより、 W&B のアプリ を使用して、 ハイパーパラメーター の 値 ごとに Run を並べ替えたり比較したりできます。run.log(): メトリクス や、画像、動画、音声ファイル、HTML、プロット、ポイントクラウドなどのカスタム オブジェクト を ログ に記録します。
3. Agent で Sweep を実行する
次に、wandb.agent を呼び出して sweep を開始します。
W&B にログインしており、以下のものがある任意のマシンで wandb.agent を呼び出すことができます:
sweep_id- データセット と
train関数
注意:random(ランダム) スイープは、デフォルトでは新しい パラメータ の組み合わせを延々と試し続けます。これを止めるには、 アプリの UI から sweep をオフにする か、agentに完了させたい合計 Run 数countを指定します。
結果の可視化
sweep が完了したら、 結果 を確認しましょう。 W&B は、いくつかの有用なプロットを自動的に生成します。並行座標プロット (Parallel coordinates plot)
このプロットは、 ハイパーパラメーター の 値 と モデル の メトリクス をマッピングします。最高の モデル パフォーマンスにつながった ハイパーパラメーター の組み合わせを絞り込むのに役立ちます。 このプロットからは、学習器として ツリー を使用した方が、単純な線形 モデル を使用するよりも、驚くほどではないにせよ、わずかにパフォーマンスが良いことが示唆されています。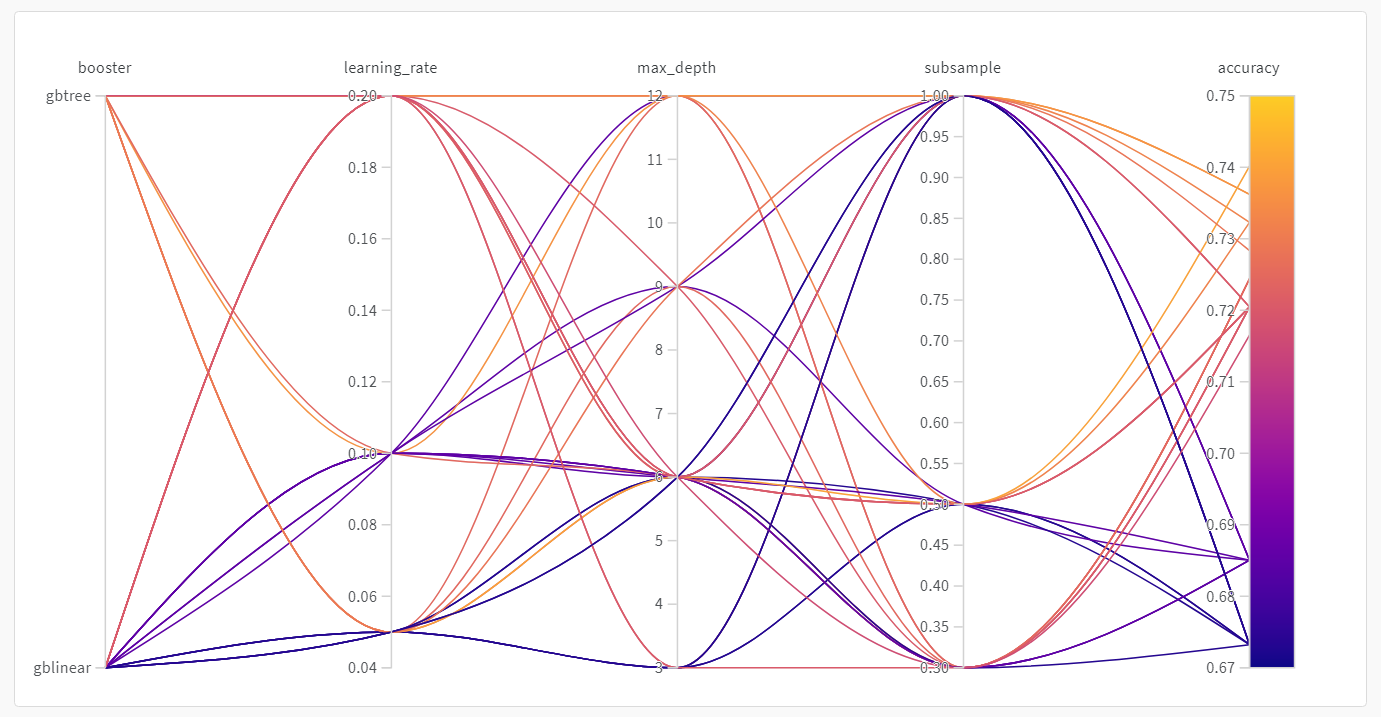
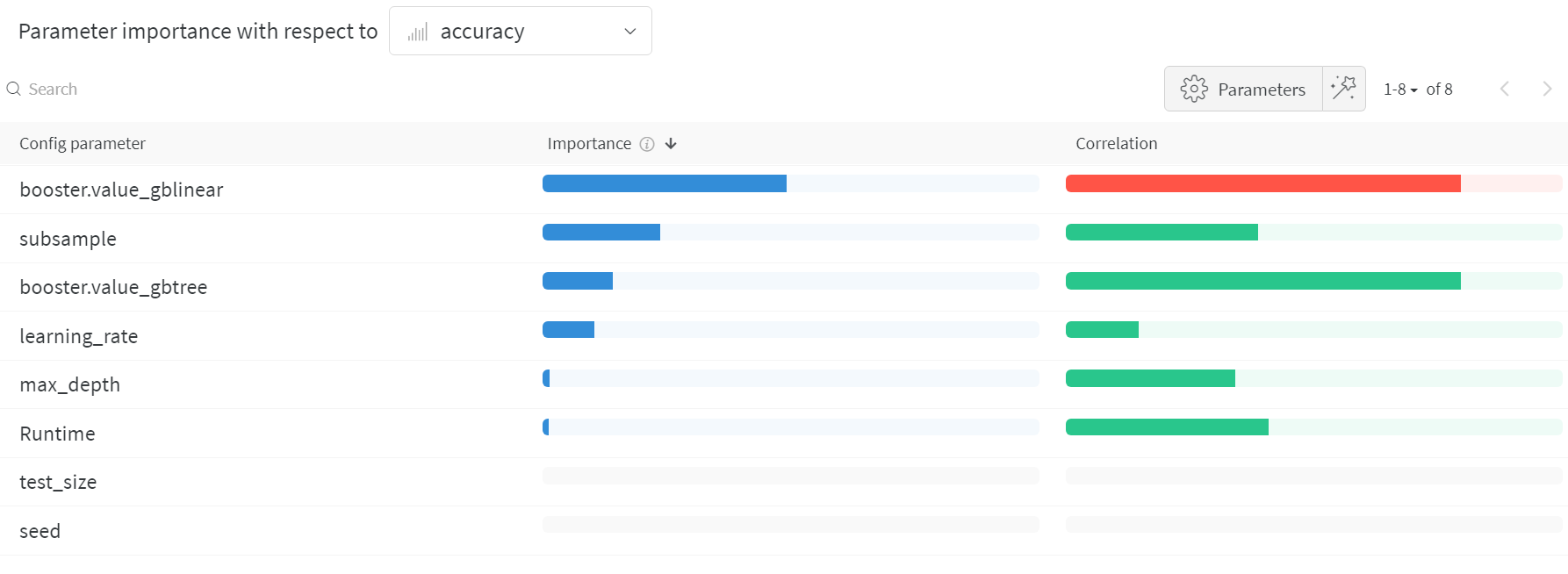
パラメータの重要度プロット (Hyperparameter importance plot)
パラメータの重要度プロット は、どの ハイパーパラメーター の 値 が メトリクス に最も大きな影響を与えたかを示します。 相関関係 (線形予測子として扱う) と 特徴量の重要度 ( 結果 に対してランダムフォレストを トレーニング した後) の両方をレポートするため、どの パラメータ が最も大きな影響を与えたか、そしてその影響が正であったか負であったかを確認できます。 このチャートを見ると、上記の並行座標プロットで気づいた傾向が定量的に確認できます。 検証精度 に最も大きな影響を与えたのは学習器の選択であり、gblinear 学習器は概して gbtree 学習器よりも劣っていました。