Sweeps: 概要
W&B でハイパーパラメーター sweep を実行するのは非常に簡単です。以下の 3 つのシンプルなステップで行えます。- sweep を定義する: 探索するパラメータ、検索戦略、最適化メトリクスなどを指定した辞書または YAML ファイル を作成します。
-
sweep を初期化する: 1 行のコードで sweep を初期化し、sweep 設定の辞書を渡します:
sweep_id = wandb.sweep(sweep_config) -
sweep agent を実行する: これも 1 行のコードで完了します。
wandb.agent()を呼び出し、実行するsweep_idと、モデルアーキテクチャーを定義してトレーニングを行う関数を渡します:wandb.agent(sweep_id, function=train)
始める前に
W&B をインストールし、W&B Python SDK をノートブックにインポートします。!pip installでインストールします:
- W&B をインポートします:
- W&B にログインし、プロンプトが表示されたら APIキー を入力します:
ステップ 1: sweep を定義する
W&B Sweep は、多数のハイパーパラメーター値を試行する戦略と、それらを評価するコードを組み合わせたものです。 sweep を開始する前に、 sweep configuration(sweep 設定)で sweep 戦略を定義する必要があります。Jupyter Notebook で sweep を開始する場合、作成する sweep 設定はネストされた辞書形式である必要があります。コマンドラインで sweep を実行する場合は、YAML ファイル で sweep 設定を指定する必要があります。
検索メソッドを選択する
まず、設定辞書の中でハイパーパラメーター検索メソッドを指定します。グリッド検索、ランダム検索、ベイズ探索の 3 つのハイパーパラメーター検索戦略から選択できます。 このチュートリアルでは、ランダム検索を使用します。ノートブック内で辞書を作成し、method キーに random を指定します。
探索するハイパーパラメーターを指定する
sweep 設定で検索メソッドを指定したので、次は探索したいハイパーパラメーターを指定します。 これを行うには、parameter キーに 1 つ以上のハイパーパラメーター名を指定し、value キーに 1 つ以上のハイパーパラメーター値を指定します。
特定のハイパーパラメーターに対して検索する値は、調査しているハイパーパラメーターのタイプによって異なります。
例えば、機械学習のオプティマイザーを選択する場合、Adam オプティマイザーや確率的勾配降下法(SGD)など、1 つ以上の具体的なオプティマイザー名を指定する必要があります。
epochs を 1 に設定しています。
random 検索の場合、ある run においてパラメータのすべての values が選ばれる確率は等しくなります。
あるいは、名前付きの distribution(分布)とそのパラメータ(normal 分布の平均 mu や標準偏差 sigma など)を指定することもできます。
sweep_config は、試行したい parameters と、それらを試行するために使用する method を正確に指定したネストされた辞書になります。
sweep 設定がどのようになっているか見てみましょう:
無限の選択肢がある可能性のあるハイパーパラメーターの場合、通常はいくつかの厳選された
values を試すのが合理的です。例えば、上記の sweep 設定では、layer_size と dropout パラメータキーに対して有限の値のリストが指定されています。ステップ 2: Sweep を初期化する
検索戦略を定義したら、それを実装するものをセットアップします。 W&B は Sweep Controller を使用して、クラウド上または 1 つ以上のマシン間でローカルに sweep を管理します。このチュートリアルでは、W&B が管理する Sweep Controller を使用します。 Sweep Controller が sweep を管理する一方で、実際に sweep を実行するコンポーネントは sweep agent と呼ばれます。デフォルトでは、Sweep Controller コンポーネントは W&B のサーバー上で開始され、sweep を作成するコンポーネントである sweep agent はローカルマシン上でアクティブ化されます。
wandb.sweep メソッドで Sweep Controller をアクティブ化できます。先ほど定義した sweep 設定辞書を sweep_config フィールドに渡します:
wandb.sweep 関数は sweep_id を返します。これは後のステップで sweep をアクティブ化するために使用します。
コマンドラインでは、この関数は以下に置き換えられます:
ステップ 3: 機械学習コードを定義する
sweep を実行する前に、試したいハイパーパラメーター値を使用するトレーニング手順を定義します。W&B Sweeps をトレーニングコードに統合する鍵は、各トレーニング実験において、トレーニングロジックが sweep 設定で定義したハイパーパラメーター値にアクセスできるようにすることです。 以下のコード例では、ヘルパー関数build_dataset、build_network、build_optimizer、および train_epoch が sweep のハイパーパラメーター設定辞書にアクセスします。
ノートブックで以下の機械学習トレーニングコードを実行してください。これらの関数は、PyTorch で基本的な全結合ニューラルネットワークを定義しています。
train 関数内には、以下の W&B Python SDK メソッドがあることに気づくでしょう:
wandb.init(): 新しい W&B Run を初期化します。各 run はトレーニング関数の 1 回の実行です。run.config: 実験したいハイパーパラメーターを含む sweep 設定を渡します。run.log(): 各エポックのトレーニング損失をログに記録します。
build_dataset、build_network、build_optimizer、および train_epoch の 4 つの関数を定義しています。
これらの関数は基本的な PyTorch パイプラインの標準的な部分であり、その実装は W&B の使用によって影響を受けません。
ステップ 4: sweep agent をアクティブ化する
sweep 設定を定義し、それらのハイパーパラメーターをインタラクティブに利用できるトレーニングスクリプトが用意できたので、sweep agent をアクティブ化する準備が整いました。sweep agent は、sweep 設定で定義したハイパーパラメーター値のセットを使用して実験を実行する役割を担います。wandb.agent メソッドで sweep agent を作成します。以下を提供してください:
- エージェントが所属する sweep (
sweep_id) - sweep が実行すべき関数。この例では、sweep は
train関数を使用します。 - (オプション) Sweep Controller に要求する設定の数 (
count)
同じ
sweep_id を持つ複数の sweep agent を、異なる計算リソース上で開始できます。Sweep Controller は、定義された sweep 設定に従って、それらが連携して動作するように管理します。train) を 5 回実行する sweep agent をアクティブ化します:
sweep 設定で
random 検索メソッドが指定されているため、Sweep Controller はランダムに生成されたハイパーパラメーター値を提供します。Sweep 結果の可視化
平行座標プロット (Parallel Coordinates Plot)
このプロットは、ハイパーパラメーター値をモデルのメトリクスに対応付けます。最高のモデルパフォーマンスにつながったハイパーパラメーターの組み合わせを絞り込むのに役立ちます。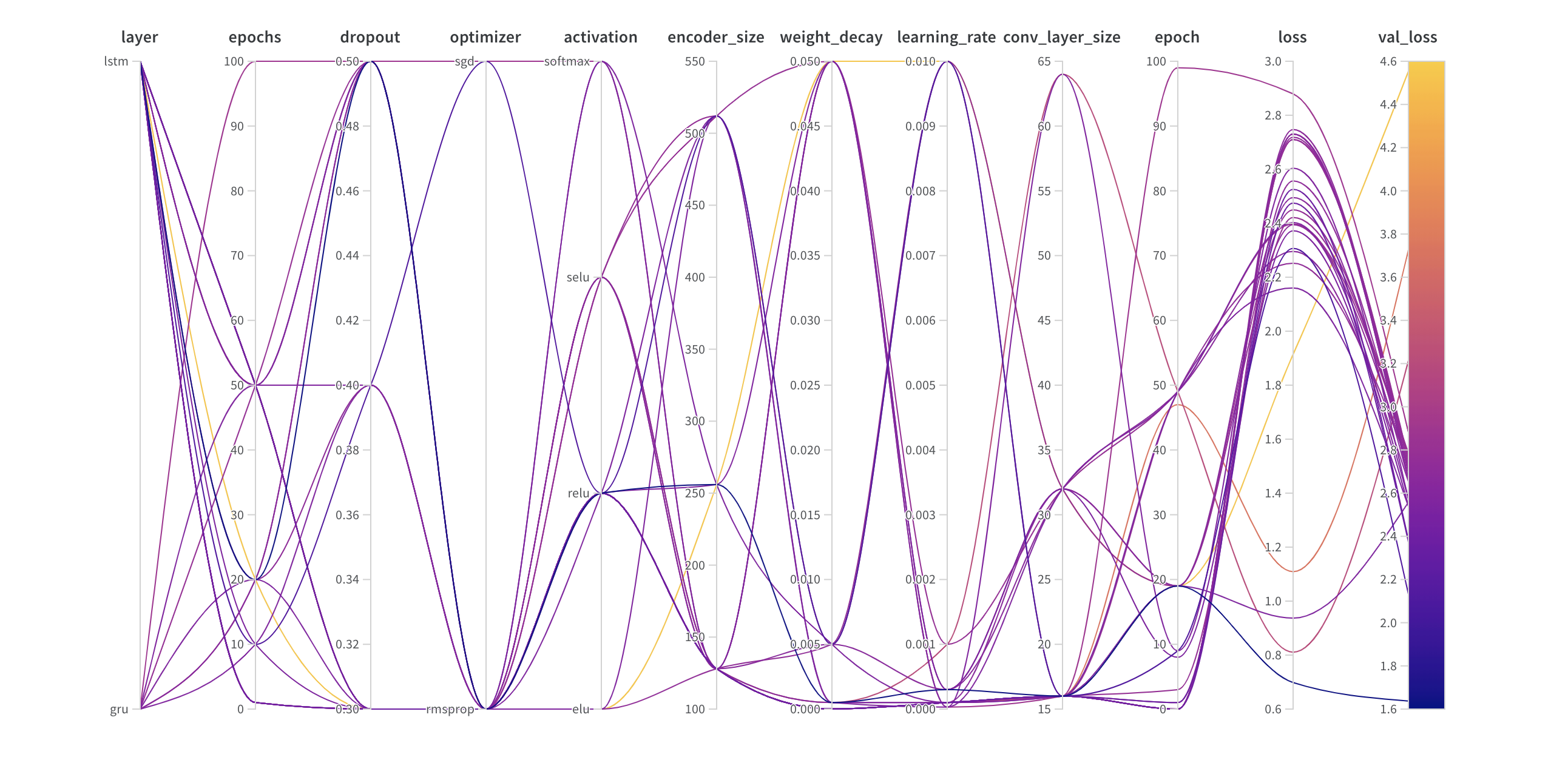
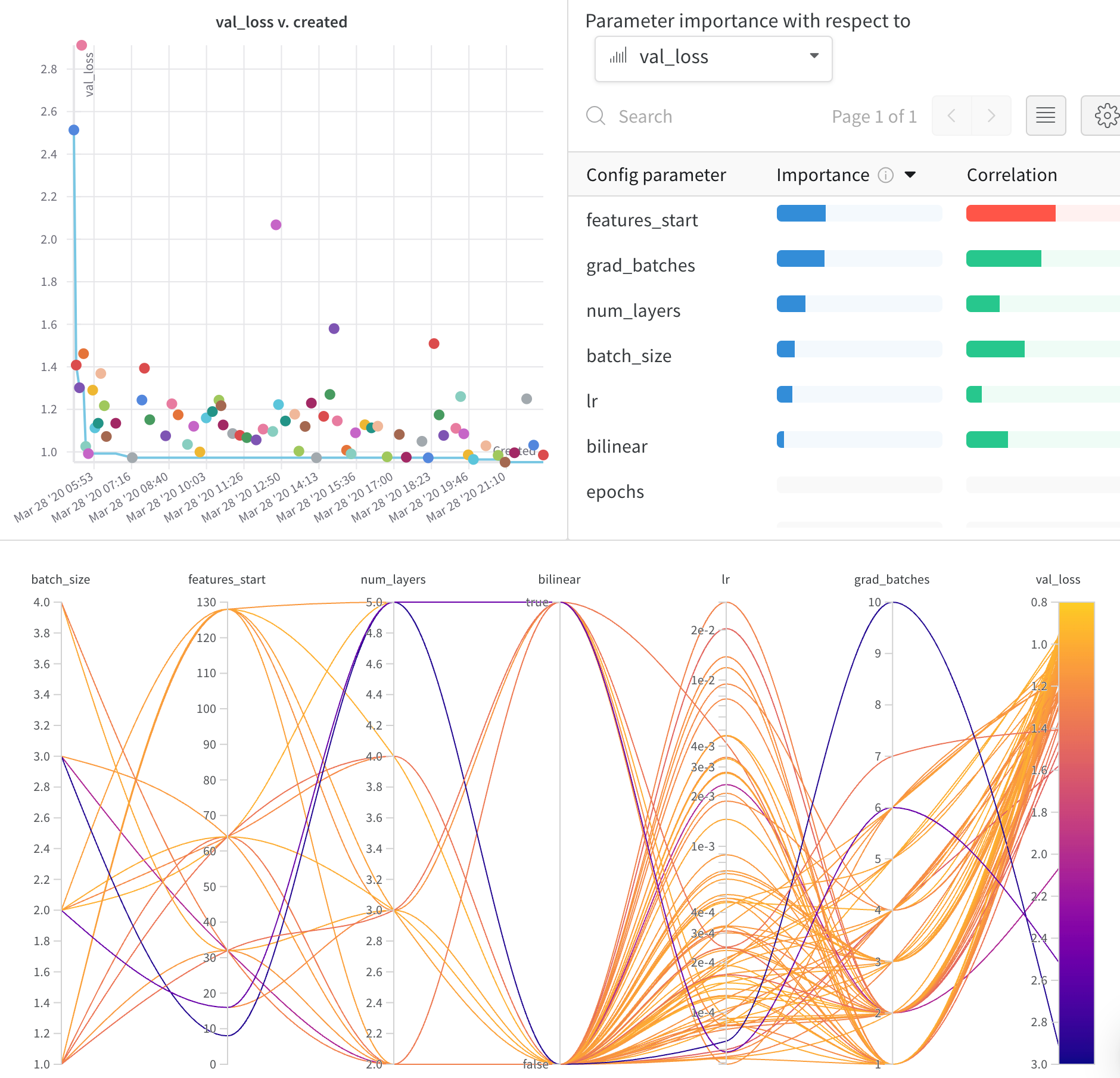
パラメータの重要度プロット (Hyperparameter Importance Plot)
パラメータの重要度プロットは、どのハイパーパラメーターがメトリクスの最良の予測因子であったかを明らかにします。 特徴量の重要度(ランダムフォレストモデルから算出)と相関(暗黙的に線形モデルから算出)をレポートします。