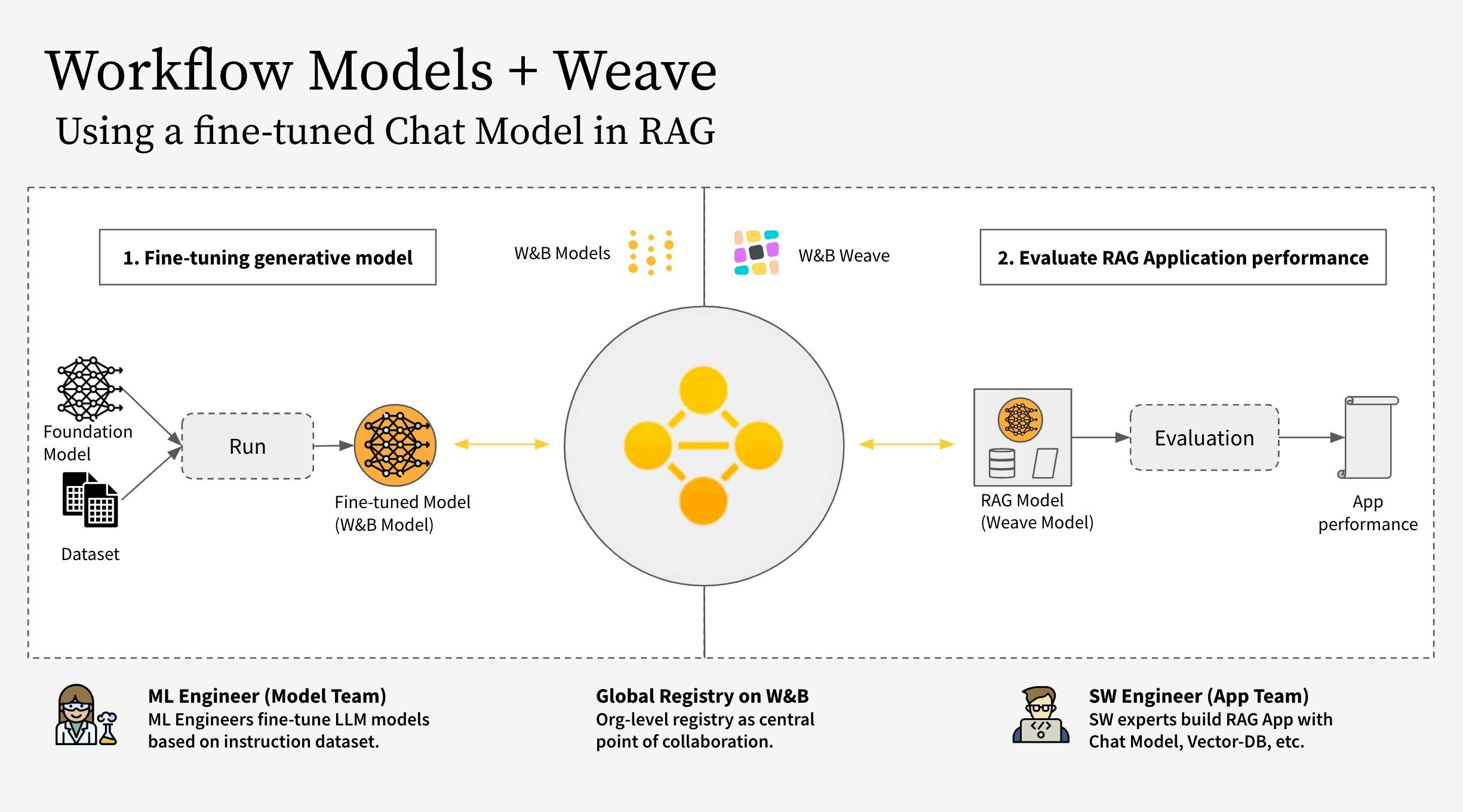
- モデルチーム: モデル構築チームが新しいチャットモデル (Llama 3.2) をファインチューンし、 W&B Models を使用してレジストリに保存します。
- アプリチーム: アプリ開発チームがチャットモデルを取得し、 W&B Weave を使用して新しい RAG チャットボットを作成および評価します。
- W&B Weave を使用して RAG アプリのコードをインスツルメント(計測)する
- LLM (Llama 3.2 など。他の LLM に置き換え可能) をファインチューニングし、 W&B Models で追跡する
- ファインチューニングされたモデルを W&B Registry にログ記録する
- 新しいファインチューニング済みモデルを使用して RAG アプリを実装し、 W&B Weave でアプリを評価する
- 結果に満足したら、更新された RAG アプリへの参照を W&B Registry に保存する
RagModel は、完全な RAG アプリと見なすことができるトップレベルの weave.Model です。これには ChatModel 、ベクトルデータベース、およびプロンプトが含まれています。 ChatModel も別の weave.Model であり、 W&B Registry から Artifact をダウンロードするコードを含んでおり、 RagModel の一部として他の任意のチャットモデルをサポートするように変更できます。詳細については、 Weave上の完全なモデル を参照してください。
1. セットアップ
まず、weave と wandb をインストールし、 APIキーでログインします。 APIキーは User Settings で作成および確認できます。
2. Artifact に基づく ChatModel の作成
Registry からファインチューニングされたチャットモデルを取得し、それから weave.Model を作成して、次のステップで RagModel に直接プラグインできるようにします。これは既存の ChatModel と同じパラメータを受け取りますが、 init と predict のみが異なります。
unsloth ライブラリを使用してさまざまな Llama-3.2 モデルをファインチューニングしました。そのため、 Registry からダウンロードしたモデルをロードするには、アダプターを備えた特別な unsloth.FastLanguageModel または peft.AutoPeftModelForCausalLM モデルを使用します。 Registry の “Use” タブからロード用コードをコピーし、 model_post_init に貼り付けてください。
3. 新しい ChatModel バージョンを RagModel に統合する
ファインチューニングされたチャットモデルから RAG アプリを構築すると、特に対話型 AI システムのパフォーマンスと汎用性を高める上で、いくつかの利点が得られます。
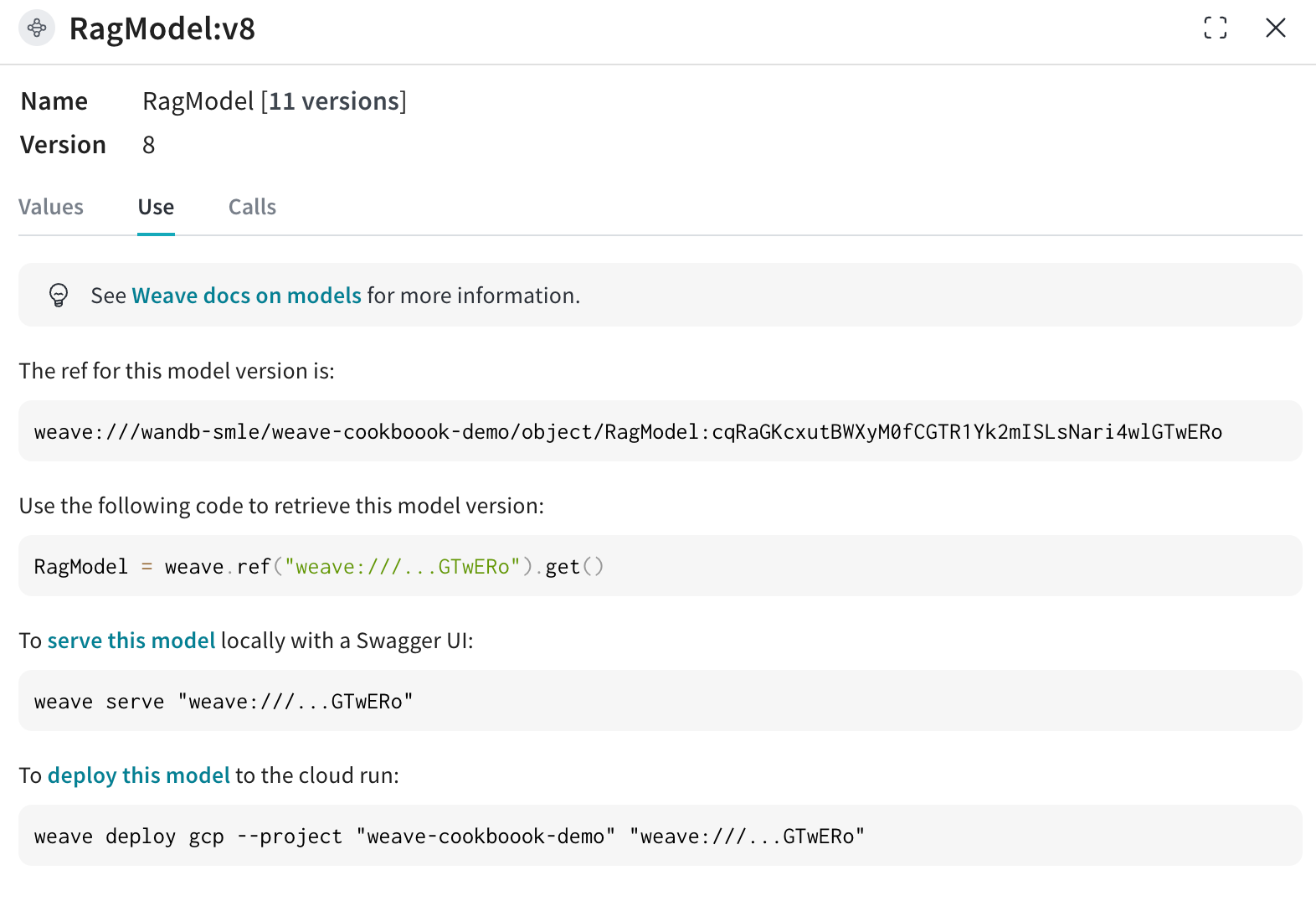
既存の Weave プロジェクトから RagModel を取得し(下図のように “Use” タブから現在の RagModel の weave 参照を取得できます)、 ChatModel を新しいものに入れ替えます。他のコンポーネント(ベクトル DB、プロンプトなど)を変更したり再作成したりする必要はありません。
4. 既存のモデルの run に接続して新しい weave.Evaluation を実行する
最後に、既存の weave.Evaluation 上で新しい RagModel を評価します。統合をできるだけ簡単にするために、以下の変更を加えます。
Models の観点から:
- Registry からモデルを取得すると、チャットモデルのエンドツーエンドの Lineage の一部である新しい
runオブジェクトが作成されます。 - run の設定に Trace ID(現在の評価 ID を含む)を追加し、モデルチームがリンクをクリックして対応する Weave ページに移動できるようにします。
- Artifact / Registry のリンクを
ChatModel(つまりRagModel)への入力として保存します。 weave.attributesを使用して、 run.id を トレース の追加カラムとして保存します。