これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクを使用してください:
Chain of Density を用いた要約
重要な詳細を維持しながら複雑な技術文書を要約することは、困難な課題です。Chain of Density(CoD)要約手法は、要約を繰り返し洗練させ、より簡潔で情報密度の高いものにすることで、この課題への解決策を提示します。このガイドでは、アプリケーションの追跡と評価に Weave を使用して CoD を実装する方法をデモします。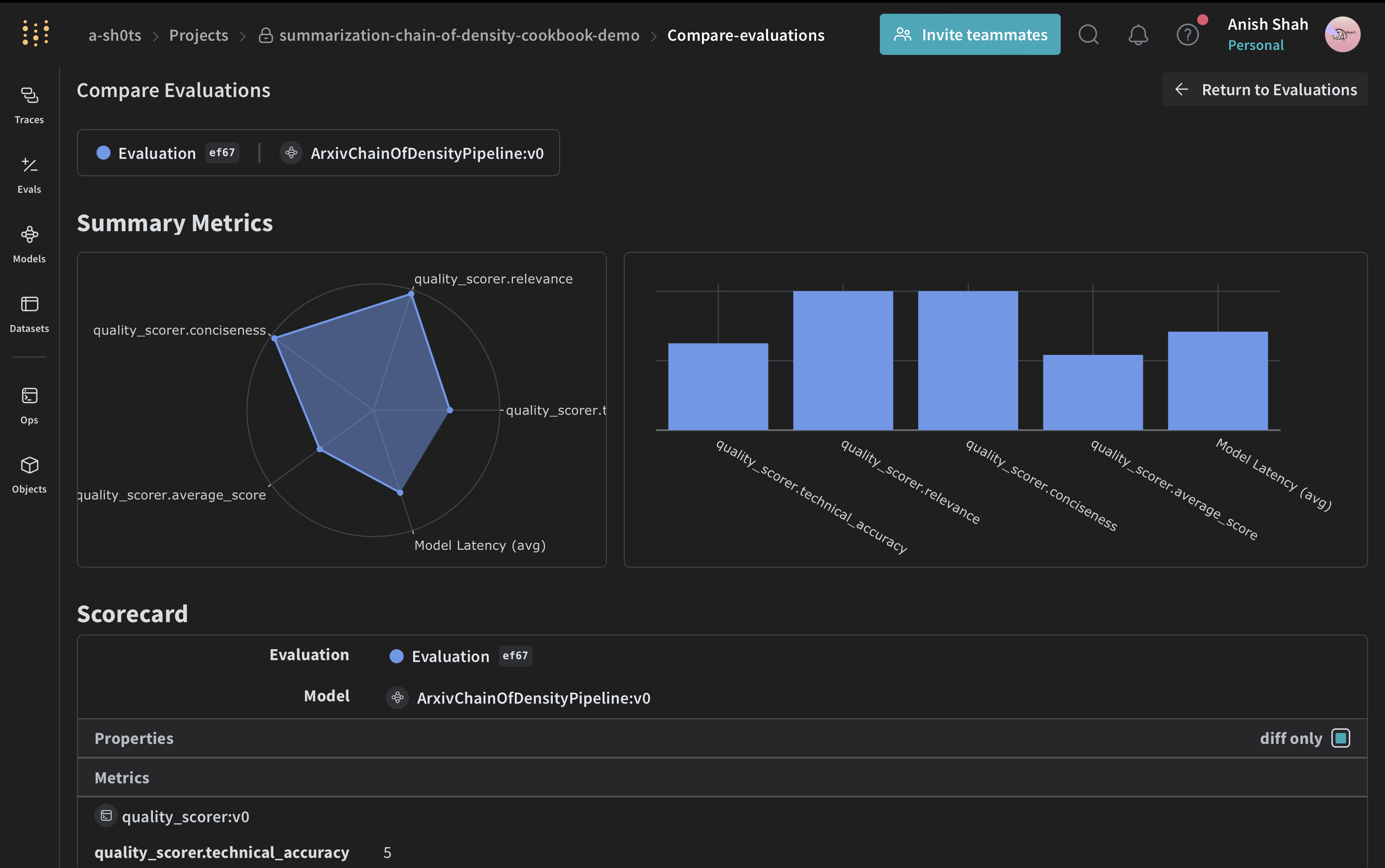
Chain of Density 要約とは?
- 最初の要約から開始する
- 要約を繰り返し洗練させ、主要な情報を保持しながらより簡潔にする
- 反復ごとにエンティティ(固有表現)や技術的な詳細の密度を高める
なぜ Weave を使うのか?
このチュートリアルでは、Weave を使用して ArXiv 論文向けの Chain of Density 要約パイプラインを実装し、評価します。以下の方法を学習します。- LLM パイプラインの追跡: Weave を使用して、要約プロセスの入力、出力、および中間ステップを自動的にログに記録します。
- LLM 出力の評価: Weave の組み込みツールを使用して、要約の厳密で公平な(apples-to-apples)評価を作成します。
- 構成可能な操作の構築: 要約パイプラインの異なる部分で Weave の operation を組み合わせ、再利用します。
- シームレスな統合: 最小限のオーバーヘッドで、既存の Python コードに Weave を追加します。
環境のセットアップ
まず、環境をセットアップし、必要なライブラリをインポートしましょう。Anthropic の APIキー を取得するには:
- https://www.anthropic.com でアカウントを登録します
- アカウント設定の API セクションに移動します
- 新しい APIキー を生成します
- .env ファイルに APIキー を安全に保存します
weave.init(<project name>) を呼び出すことで、要約タスク用の新しい Weave プロジェクトがセットアップされます。
ArxivPaper モデルの定義
データを表すためのシンプルなArxivPaper クラスを作成します。
PDF コンテンツのロード
論文の全文を扱うために、PDF をロードしてテキストを抽出する関数を追加します。Chain of Density 要約の実装
次に、Weave の operation を使用して CoD 要約のコアロジックを実装します。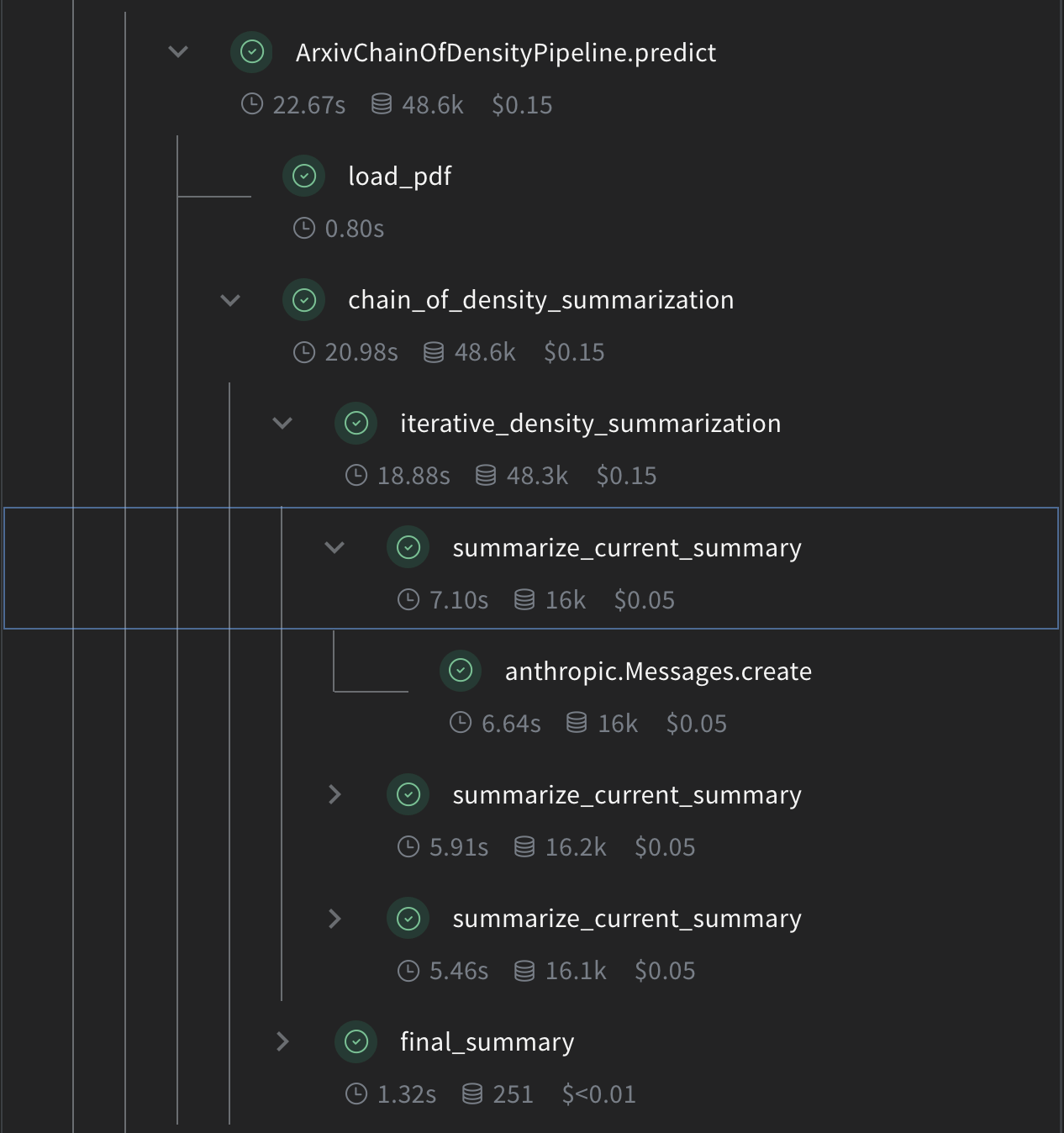
summarize_current_summary: 現在の状態に基づき、1回の要約反復を生成します。iterative_density_summarization:summarize_current_summaryを複数回呼び出すことで CoD 手法を適用します。chain_of_density_summarization: 要約プロセス全体をオーケストレートし、結果を返します。
@weave.op() デコレータを使用することで、Weave がこれらの関数の入力、出力、および実行を確実に追跡できるようになります。
Weave Model の作成
次に、要約パイプラインを Weave Model でラップしましょう。
ArxivChainOfDensityPipeline クラスは要約ロジックを Weave Model としてカプセル化し、いくつかの主要なメリットを提供します。
- 自動的な実験管理: Weave はモデルの各実行における入力、出力、およびパラメータをキャプチャします。
- バージョン管理: モデルの属性やコードへの変更は自動的にバージョン管理され、要約パイプラインの進化の歴史を明確にします。
- 再現性: バージョン管理と追跡により、要約パイプラインの以前の結果や設定を簡単に再現できます。
- ハイパーパラメーター管理: モデル属性(
modelやdensity_iterationsなど)が明確に定義および追跡され、実験を促進します。 - Weave エコシステムとの統合:
weave.Modelを使用することで、評価やサービング機能など、他の Weave ツールとシームレスに統合できます。
評価メトリクスの実装
要約の質を評価するために、シンプルな評価メトリクスを実装します。Weave Dataset の作成と評価の実行
パイプラインを評価するために、Weave Dataset を作成して評価を実行します。
結論
この例では、Weave を使用して ArXiv 論文用の Chain of Density 要約パイプラインを実装する方法を実演しました。以下の内容を紹介しました:- 要約プロセスの各ステップに対して Weave operation を作成する方法
- 追跡と評価を容易にするためにパイプラインを Weave Model でラップする方法
- Weave operation を使用してカスタム評価メトリクスを実装する方法
- データセットを作成し、パイプラインの評価を実行する方法