これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクを使用できます: DSPy と Weave を使用した LLM ワークフローの最適化
BIG-bench (Beyond the Imitation Game Benchmark) は、大型言語モデルを調査し、その将来の能力を推測することを目的とした共同ベンチマークであり、200 以上のタスクで構成されています。BIG-Bench Hard (BBH) は、現世代の言語モデルでは解決が非常に困難な、最も難易度の高い 23 の BIG-Bench タスクのセットです。
このチュートリアルでは、BIG-bench Hard ベンチマークの causal judgement(因果判断)タスク で実装された LLM ワークフローのパフォーマンスを向上させ、プロンプティング戦略を評価する方法を実演します。LLM ワークフローの実装とプロンプティング戦略の最適化には DSPy を使用します。また、LLM ワークフローの追跡とプロンプティング戦略の評価には Weave を使用します。
依存関係のインストール
このチュートリアルには以下のライブラリが必要です。
- DSPy: LLM ワークフローの構築と最適化に使用。
- Weave: LLM ワークフローの追跡とプロンプティング戦略の評価に使用。
- datasets: HuggingFace Hub から Big-Bench Hard データセットにアクセスするために使用。
!pip install -qU dspy-ai weave datasets
import os
from getpass import getpass
api_key = getpass("Enter you OpenAI API key: ")
os.environ["OPENAI_API_KEY"] = api_key
Weave を使用したトラッキングの有効化
Weave は現在 DSPy と統合されており、コードの最初に weave.init を含めることで、DSPy 関数のトレースを自動的に行い、Weave の UI で確認できるようになります。詳細は DSPy の Weave インテグレーションガイド をご覧ください。
import weave
weave.init(project_name="dspy-bigbench-hard")
weave.Object を継承したメタデータクラスを使用してメタデータを管理します。
class Metadata(weave.Object):
dataset_address: str = "maveriq/bigbenchhard"
big_bench_hard_task: str = "causal_judgement"
num_train_examples: int = 50
openai_model: str = "gpt-3.5-turbo"
openai_max_tokens: int = 2048
max_bootstrapped_demos: int = 8
max_labeled_demos: int = 8
metadata = Metadata()
オブジェクトのバージョン管理: Metadata オブジェクトは、それを使用する関数がトレースされる際に、自動的にバージョン管理(versioning)およびトレースされます。
BIG-Bench Hard データセットのロード
HuggingFace Hub からこのデータセットをロードし、トレーニングセットと検証セットに分割して、Weave 上に パブリッシュ します。これにより、Datasets のバージョン管理が可能になり、weave.Evaluation を使用してプロンプティング戦略を評価できるようになります。
import dspy
from datasets import load_dataset
@weave.op()
def get_dataset(metadata: Metadata):
# Huggingface Hub からタスクに対応する BIG-Bench Hard データセットをロード
dataset = load_dataset(metadata.dataset_address, metadata.big_bench_hard_task)[
"train"
]
# トレーニング用と検証用のデータセットを作成
rows = [{"question": data["input"], "answer": data["target"]} for data in dataset]
train_rows = rows[0 : metadata.num_train_examples]
val_rows = rows[metadata.num_train_examples :]
# `dspy.Example` オブジェクトで構成されるトレーニング用と検証用の例を作成
dspy_train_examples = [
dspy.Example(row).with_inputs("question") for row in train_rows
]
dspy_val_examples = [dspy.Example(row).with_inputs("question") for row in val_rows]
# データセットを Weave にパブリッシュ。これによりデータのバージョン管理と評価への利用が可能になる
weave.publish(
weave.Dataset(
name=f"bigbenchhard_{metadata.big_bench_hard_task}_train", rows=train_rows
)
)
weave.publish(
weave.Dataset(
name=f"bigbenchhard_{metadata.big_bench_hard_task}_val", rows=val_rows
)
)
return dspy_train_examples, dspy_val_examples
dspy_train_examples, dspy_val_examples = get_dataset(metadata)
DSPy プログラム
DSPy は、新しい LM パイプラインの構築を、自由形式の文字列の操作から、プログラミング(テキスト変換グラフを構築するためのモジュール式オペレーターの構成)へとシフトさせるフレームワークです。コンパイラがプログラムから、最適化された LM 呼び出し戦略とプロンプトを自動的に生成します。
ここでは dspy.OpenAI 抽象化を使用して、GPT3.5 Turbo への LLM 呼び出しを行います。
system_prompt = """
あなたは因果推論の分野の専門家です。与えられた質問を注意深く分析し、`Yes` または `No` で答えてください。
また、あなたの答えを正当化する詳細な説明も提供してください。
"""
llm = dspy.OpenAI(model="gpt-3.5-turbo", system_prompt=system_prompt)
dspy.settings.configure(lm=llm)
因果推論シグネチャの作成
シグネチャ (signature) は、DSPy モジュール の入出力動作を宣言的に定義する仕様です。DSPy モジュールはタスク適応型のコンポーネントであり、ニューラルネットワークのレイヤーに似ており、特定のテキスト変換を抽象化します。
from pydantic import BaseModel, Field
class Input(BaseModel):
query: str = Field(description="回答すべき質問")
class Output(BaseModel):
answer: str = Field(description="質問に対する回答")
confidence: float = Field(
ge=0, le=1, description="回答の信頼度スコア"
)
explanation: str = Field(description="回答の理由説明")
class QuestionAnswerSignature(dspy.Signature):
input: Input = dspy.InputField()
output: Output = dspy.OutputField()
class CausalReasoningModule(dspy.Module):
def __init__(self):
self.prog = dspy.TypedPredictor(QuestionAnswerSignature)
@weave.op()
def forward(self, question) -> dict:
return self.prog(input=Input(query=question)).output.dict()
CausalReasoningModule)をテストしてみましょう。
import rich
baseline_module = CausalReasoningModule()
prediction = baseline_module(dspy_train_examples[0]["question"])
rich.print(prediction)
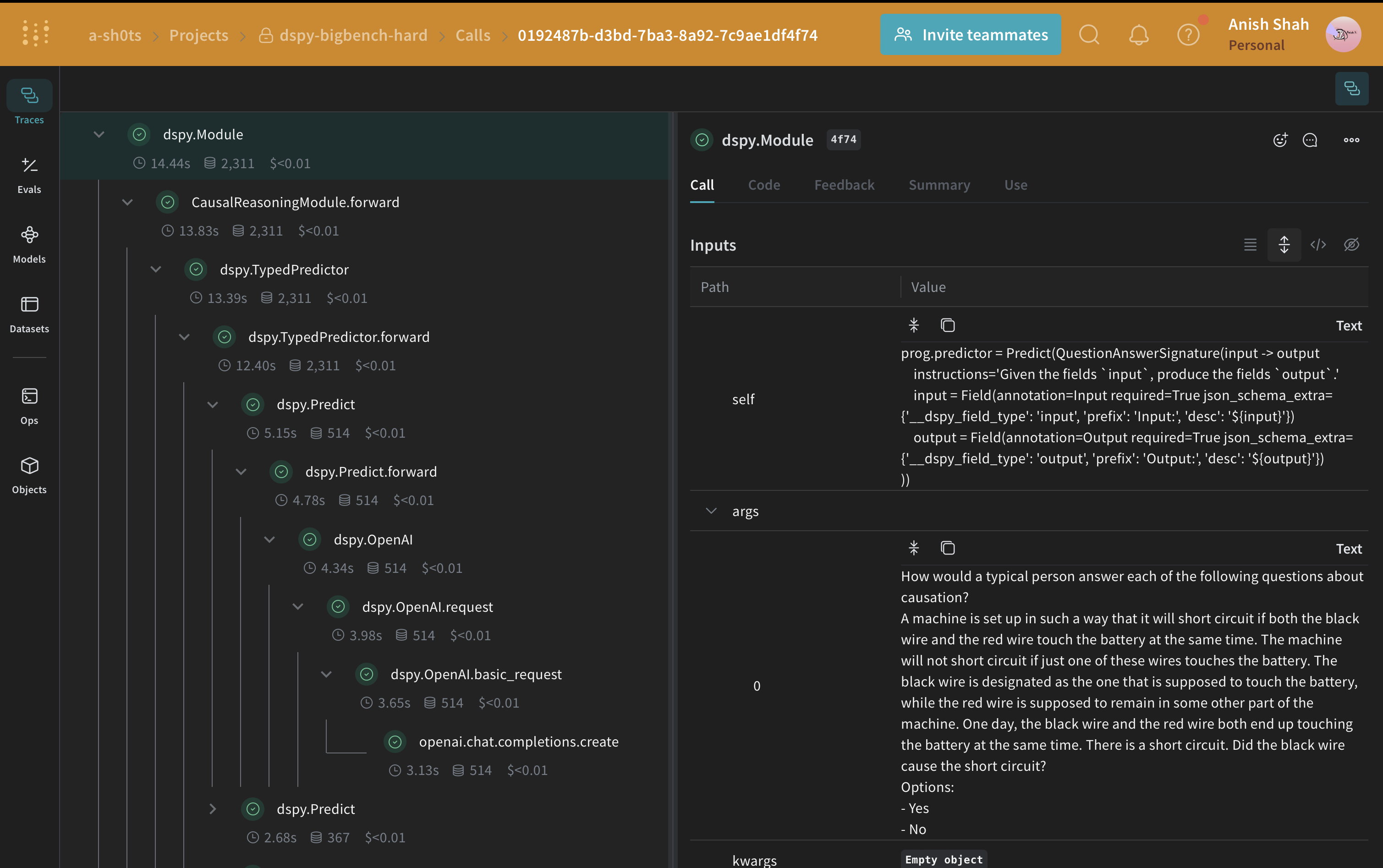
DSPy プログラムの評価
weave.Evaluation を行いましょう。Weave は各例を取得し、アプリケーションを通過させ、複数のカスタムスコアリング関数で出力をスコアリングします。これにより、アプリケーションのパフォーマンスを俯瞰できるだけでなく、個別の出力やスコアを掘り下げて確認できるリッチな UI が提供されます。
まず、ベースラインモジュールの出力結果が正解と一致するかどうかを判定する、シンプルな Weave 評価スコアリング関数を作成する必要があります。スコアリング関数には model_output というキーワード引数が必要ですが、その他の引数はユーザー定義であり、データセットの例から取得されます。引数名に基づいた辞書キーを使用することで、必要なキーのみを取得します。
@weave.op()
def weave_evaluation_scorer(answer: str, output: Output) -> dict:
return {"match": int(answer.lower() == output["answer"].lower())}
validation_dataset = weave.ref(
f"bigbenchhard_{metadata.big_bench_hard_task}_val:v0"
).get()
evaluation = weave.Evaluation(
name="baseline_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(baseline_module.forward)
Python スクリプトから実行する場合は、以下のコードを使用して評価を実行できます:import asyncio
asyncio.run(evaluation.evaluate(baseline_module.forward))
因果推論データセットの評価を実行すると、OpenAI のクレジットが約 0.24 ドル消費されます。
DSPy プログラムの最適化
ベースラインの DSPy プログラムが完成したので、指定されたメトリクスを最大化するように DSPy プログラムのパラメータをチューニングできる DSPy テレプロンプター(optimizer) を使用して、因果推論のパフォーマンス向上を試みます。このチュートリアルでは、BootstrapFewShot テレプロンプターを使用します。
from dspy.teleprompt import BootstrapFewShot
@weave.op()
def get_optimized_program(model: dspy.Module, metadata: Metadata) -> dspy.Module:
@weave.op()
def dspy_evaluation_metric(true, prediction, trace=None):
return prediction["answer"].lower() == true.answer.lower()
teleprompter = BootstrapFewShot(
metric=dspy_evaluation_metric,
max_bootstrapped_demos=metadata.max_bootstrapped_demos,
max_labeled_demos=metadata.max_labeled_demos,
)
return teleprompter.compile(model, trainset=dspy_train_examples)
optimized_module = get_optimized_program(baseline_module, metadata)
因果推論データセットの評価を実行すると、OpenAI のクレジットが約 0.04 ドル消費されます。
evaluation = weave.Evaluation(
name="optimized_causal_reasoning_module",
dataset=validation_dataset,
scorers=[weave_evaluation_scorer],
)
await evaluation.evaluate(optimized_module.forward)



