これはインタラクティブなノートブックです。ローカルで実行するか、以下のリンクを使用してください:
Not Diamond を使用した LLM プロンプトのカスタムルーティング
このノートブックでは、Weave と Not Diamond のカスタムルーティング を使用して、評価結果に基づき LLM プロンプトを最も適切なモデルにルーティングする方法を説明します。プロンプトのルーティング
複雑な LLM ワークフローを構築する際、ユーザーは精度、コスト、または呼び出しのレイテンシに応じて、異なるモデルにプロンプトを送信する必要がある場合があります。 ユーザーは Not Diamond を使用して、これらのワークフロー内のプロンプトをニーズに合った適切なモデルにルーティングし、精度を最大化しながらモデルコストを節約できます。 どのようなデータの分布においても、単一のモデルがすべてのクエリに対して他のすべてのモデルを上回ることは稀です。各 LLM をいつ呼び出すべきかを学習する「メタモデル」に複数のモデルを組み合わせることで、個々のモデルのパフォーマンスを上回り、その過程でコストやレイテンシを削減することも可能です。カスタムルーティング
プロンプト用のカスタムルーターをトレーニングするには、次の3つが必要です。- LLM プロンプトのセット:プロンプトは文字列である必要があり、アプリケーションで使用されるプロンプトを代表するものである必要があります。
- LLM のレスポンス:各入力に対する候補 LLM からのレスポンス。候補 LLM には、サポートされている LLM と独自のカスタムモデルの両方を含めることができます。
- 候補 LLM からの入力に対するレスポンスの評価スコア:スコアは数値であり、ニーズに合った任意のメトリクスを使用できます。
トレーニングデータのセットアップ
実際には、独自の Evaluations を使用してカスタムルーターをトレーニングします。ただし、この例のノートブックでは、コーディングタスク用のカスタムルーターをトレーニングするために、HumanEval データセット に対する LLM のレスポンスを使用します。 まず、この例のために用意したデータセットをダウンロードし、LLM のレスポンスを各モデルのEvaluationResults にパースすることから始めます。
カスタムルーターのトレーニング
EvaluationResults が用意できたので、カスタムルーターをトレーニングできます。アカウントを作成 し、APIキーを生成 したことを確認してから、以下に API キーを挿入してください。
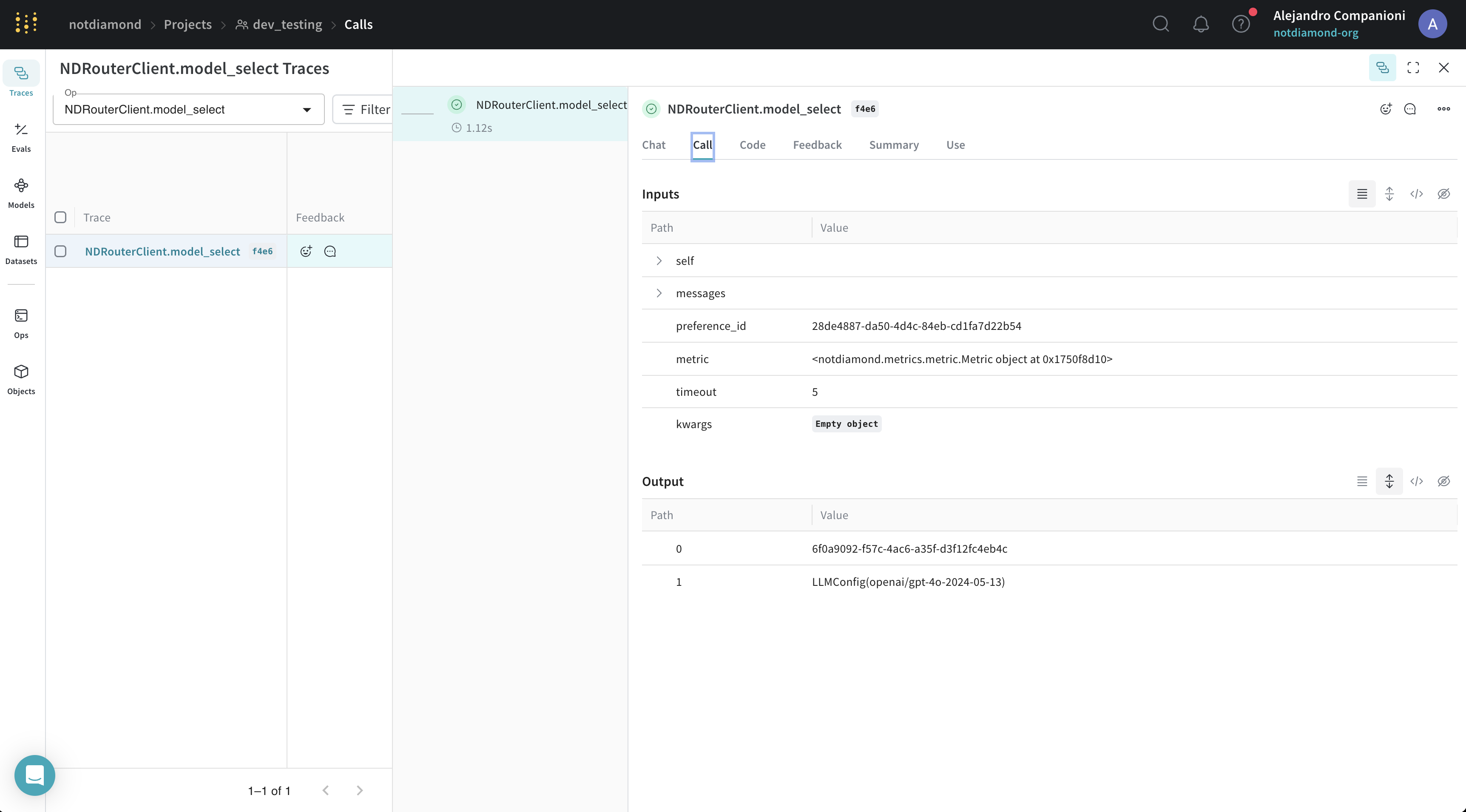
カスタムルーターの評価
カスタムルーターのトレーニングが完了したら、以下のいずれかのパフォーマンスを評価できます。- インサンプルのパフォーマンス(トレーニングプロンプトを送信)
- アウトオブサンプルのパフォーマンス(新規またはホールドアウトされたプロンプトを送信)
