イントロダクション
プロダクション環境で LLM アプリケーションを構築していますか? おそらく次の 2 つの問いが頭を離れないはずです:
- LLM が安全で適切なコンテンツを生成することをどのように保証するか?
- 時間の経過とともに、出力の品質をどのように測定し、改善していくか?
Weave の統合スコアリングシステムは、シンプルながらも強力なフレームワークを通じて、これら両方の問いに答えます。アクティブな安全制御(ガードレール)が必要な場合でも、パッシブな品質モニタリングが必要な場合でも、このガイドでは LLM アプリケーションに堅牢な評価システムを実装する方法を解説します。
Weave の評価システムの基礎となるのは Scorer です。これは、関数の入力と出力を評価して、品質、安全性、または関心のあるその他のメトリクスを測定するコンポーネントです。Scorer は多機能で、次の 2 つの方法で使用できます。
- ガードレールとして: 不安全なコンテンツがユーザーに届く前に、ブロックまたは修正する
- モニターとして: 品質メトリクスを長期的に追跡し、トレンドや改善点を特定する
用語
このガイドでは、@weave.op でデコレートされた関数を 「ops」 と呼びます。これらは、Weave のトラッキング機能で強化された通常の Python 関数です。
すぐに使える Scorer
このガイドではカスタム Scorer の作成方法を説明しますが、Weave には以下を含む、すぐに使用できるさまざまな 定義済み Scorer が用意されています。
ガードレール vs. モニター:使い分けのタイミング
Scorer はガードレールとモニターの両方を支えていますが、その目的は異なります。
| 側面 | ガードレール | モニター |
|---|
| 目的 | 問題を防ぐためのアクティブな介入 | 分析のためのパッシブな観察 |
| タイミング | リアルタイム、出力がユーザーに届く前 | 非同期またはバッチ処理が可能 |
| パフォーマンス | 高速である必要がある(応答時間に影響するため) | 低速でも可、バックグラウンドで実行可能 |
| サンプリング | 通常、すべてのリクエスト | 多くの場合サンプリングされる(例:コールの 10%) |
| 制御フロー | 出力をブロック/修正できる | アプリケーションのフローに影響を与えない |
| リソース使用量 | 効率的である必要がある | 必要に応じてより多くのリソースを使用可能 |
- ガードレールとして: 有害なコンテンツを即座にブロックする
- モニターとして: 有害性のレベルを長期的に追跡する
すべての Scorer の結果は Weave のデータベースに自動的に保存されます。つまり、追加の作業なしでガードレールがモニターを兼ねることになります!もともとどのように使用されていたかに関わらず、いつでも過去の Scorer の結果を分析できます。
.call() メソッドの使用
Weave の ops で Scorer を使用するには、操作の結果とトラッキング情報の両方にアクセスする必要があります。.call() メソッドはその両方を提供します。
# op を直接呼び出す代わりに:
result = generate_text(input) # op を呼び出す主な方法ですが、Call オブジェクトにアクセスできません
# .call() メソッドを使用して結果と Call オブジェクトの両方を取得します:
result, call = generate_text.call(input) # これで Scorer と共に Call オブジェクトを使用できます
なぜ .call() を使うのか?
Call オブジェクトは、データベース内でスコアをコールに関連付けるために不可欠です。スコアリング関数を直接呼び出すこともできますが、それではコールに関連付けられないため、後で分析する際、検索、フィルタリング、エクスポートができなくなります。Call オブジェクトの詳細については、Calls ガイドの Call オブジェクトのセクションを参照してください。 Scorer を使ってみる
基本的な例
.call() を Scorer と共に使用する簡単な例を次に示します。
import weave
from weave import Scorer
class LengthScorer(Scorer):
@weave.op
def score(self, output: str) -> dict:
"""出力の長さをチェックするシンプルな Scorer。"""
return {
"length": len(output),
"is_short": len(output) < 100
}
@weave.op
def generate_text(prompt: str) -> str:
return "Hello, world!"
# 結果と Call オブジェクトの両方を取得
result, call = generate_text.call("Say hello")
# これで Scorer を適用できます
await call.apply_scorer(LengthScorer())
Scorer をガードレールとして使用する
ガードレールは、LLM の出力がユーザーに届くのを許可する前に実行される安全チェックとして機能します。実践的な例を次に示します。
import weave
from weave import Scorer
@weave.op
def generate_text(prompt: str) -> str:
"""LLM を使用してテキストを生成。"""
# LLM 生成ロジックをここに記述
return "Generated response..."
class ToxicityScorer(Scorer):
@weave.op
def score(self, output: str) -> dict:
"""
コンテンツに有害な表現が含まれていないか評価。
"""
# 有害性検出ロジックをここに記述
return {
"flagged": False, # コンテンツが有害な場合は True
"reason": None # フラグが立てられた場合のオプションの理由
}
async def generate_safe_response(prompt: str) -> str:
# 結果と Call オブジェクトを取得
result, call = generate_text.call(prompt)
# 安全性をチェック
safety = await call.apply_scorer(ToxicityScorer())
if safety.result["flagged"]:
return f"I cannot generate that content: {safety.result['reason']}"
return result
Scorer のタイミング
Scorer を適用する際:
- メインの操作(
generate_text)が完了し、UI 上で終了としてマークされます
- Scorer はメインの操作の後に非同期で実行されます
- Scorer の結果は完了次第、コールにアタッチされます
- UI で Scorer の結果を確認したり、API 経由でクエリしたりできます
Scorer をモニターとして使用する
この機能は、マルチテナント (MT) SaaS デプロイメントでのみ利用可能です。
weave.op でデコレートされた 1 つ以上の指定された関数を監視する- LLM-as-a-judge Scorer を使用して、コールのサブセットをスコアリングする。これは、スコアリングしたい ops に合わせて調整された特定のプロンプトを持つ LLM モデルです
- 指定された
weave.op が呼び出されるたびに自動的に実行されるため、手動で .apply_scorer() を呼び出す必要はありません
モニターは以下のような場合に最適です:
- プロダクション環境の振る舞いの評価と追跡
- デグレードやドリフトの検知
- 実際のパフォーマンスデータの経時的な収集
一般的なモニターの作成方法を学ぶか、真実性モニター作成のエンドツーエンドの例を試してみてください。
モニターを作成する
- 左メニューから Monitors タブを選択します。
- モニターページで、New Monitor をクリックします。
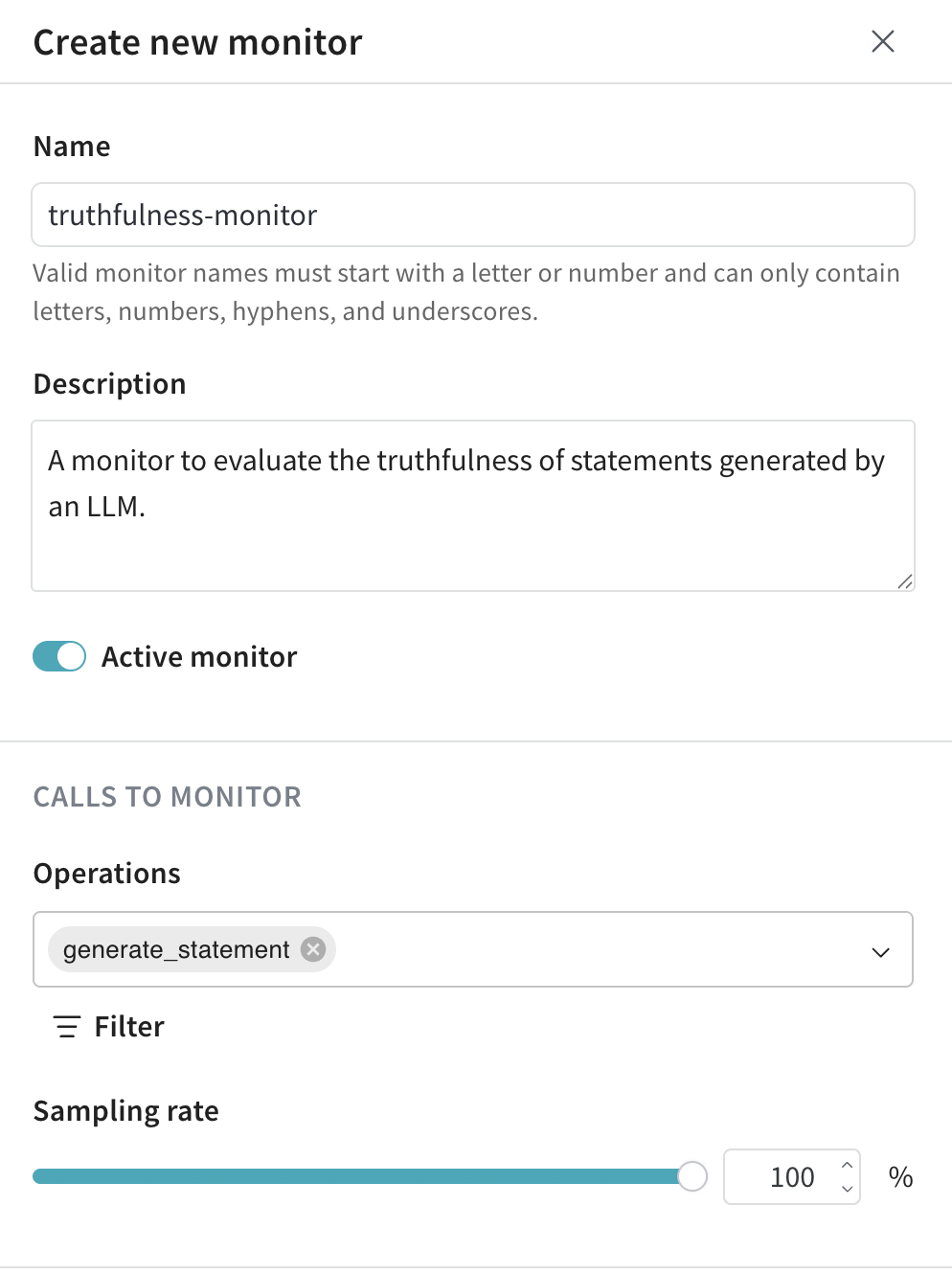
- ドロワーで、モニターを設定します。
- Name: 有効なモニター名は、文字または数字で始まり、文字、数字、ハイフン、アンダースコアのみを含めることができます。
- Description (任意): モニターの役割を説明します。
- Active monitor トグル: モニターのオン/オフを切り替えます。
- Calls to monitor:
- Operations: 監視する 1 つ以上の
@weave.op を選択します。
Op が利用可能な操作のリストに表示されるには、その Op に対して少なくとも 1 つのトレースをログに記録する必要があります。
- Filter (任意): モニタリング対象とする Op のカラム(例:
max_tokens や top_p)を絞り込みます。
- Sampling rate: スコアリングするコールの割合を 0% から 100% の間で設定します(例:10%)。
サンプリングレートを低く設定することは、各スコアリングコールにコストがかかるため、コストを抑えるのに役立ちます。
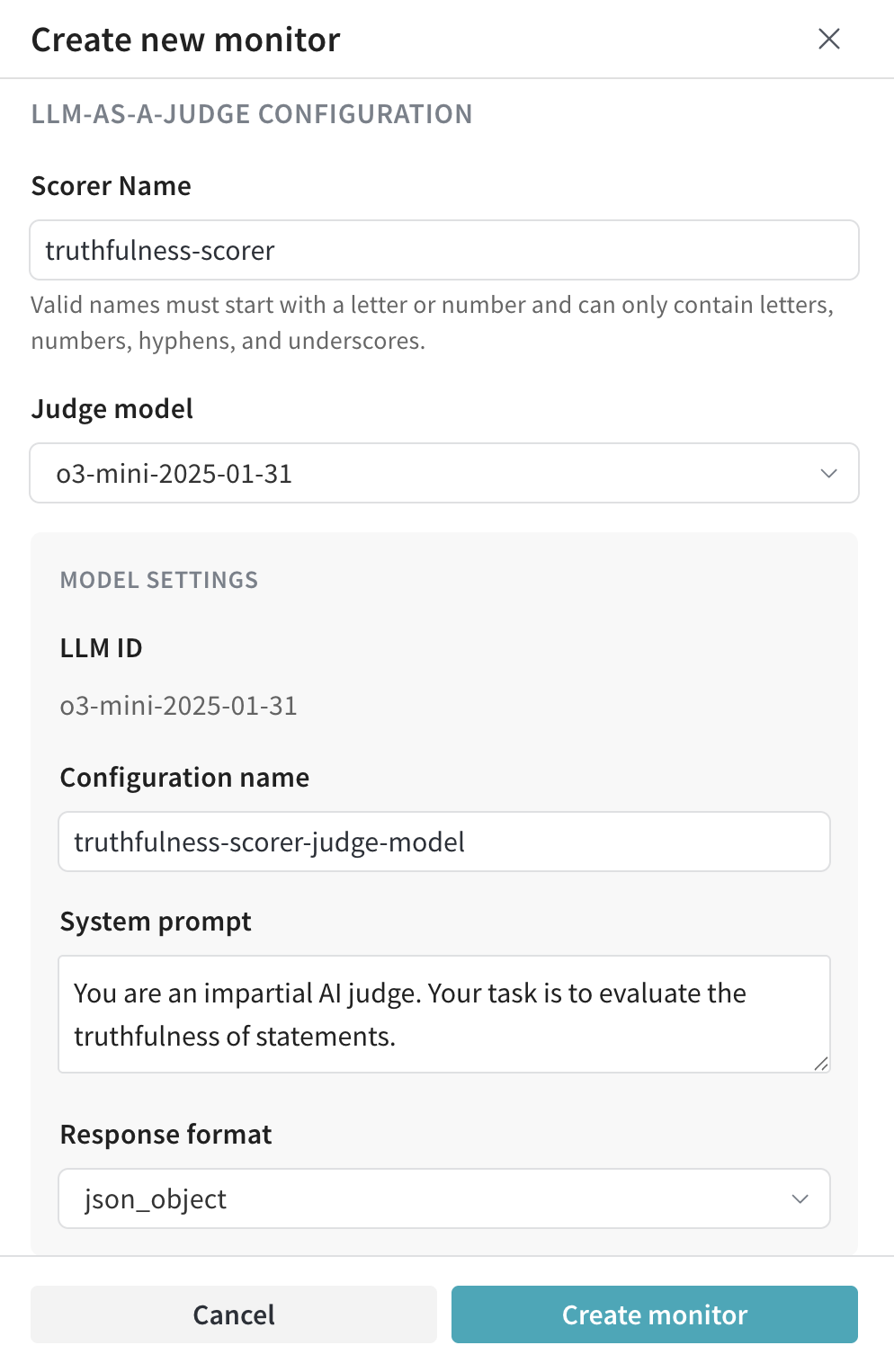
- LLM-as-a-Judge configuration:
- Scorer name: 有効な Scorer 名は、文字または数字で始まり、文字、数字、ハイフン、アンダースコアのみを含めることができます。
- Judge model: ops をスコアリングするモデルを選択します。3 種類のモデルが利用可能です。
- Configuration name
- System prompt
- Response format
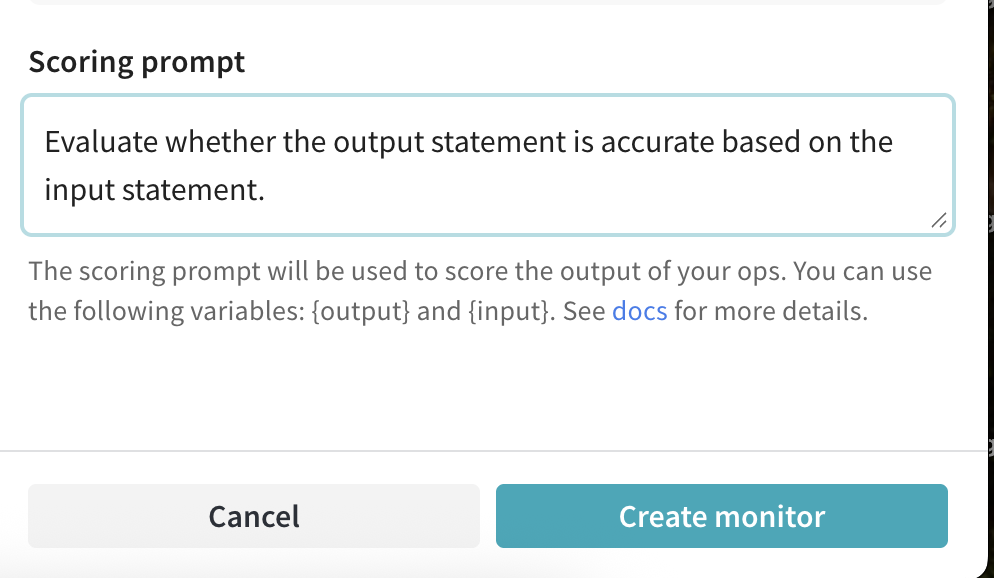
- Scoring prompt: LLM-as-a-judge が ops をスコアリングするために使用するプロンプト。「
{output}、個別の入力(例:{foo})、および辞書としての {inputs} を参照できます。詳細はプロンプト変数を参照してください。」
- Create Monitor をクリックします。Weave は、指定された条件に一致するコールのモニタリングとスコアリングを自動的に開始します。モニターの詳細は Monitors タブで確認できます。
例:真実性モニターを作成する
次の例では、以下を作成します。
- 監視対象となる
weave.op である generate_statement。この関数は、入力された ground_truth の記述(例:"地球は太陽の周りを回っている。")をそのまま返すか、ground_truth に基づいて不正確な記述(例:"地球は土星の周りを回っている。")を生成して出力します。
- 生成された記述の真実性を評価するためのモニター、
truthfulness-monitor。
generate_statement を定義します:
import weave
import random
import openai
# my-team/my-weave-project をあなたの Weave チーム名とプロジェクト名に置き換えてください
weave.init("my-team/my-weave-project")
client = openai.OpenAI()
@weave.op()
def generate_statement(ground_truth: str) -> str:
if random.random() < 0.5:
response = openai.ChatCompletion.create(
model="gpt-4.1",
messages=[
{
"role": "user",
"content": f"Generate a statement that is incorrect based on this fact: {ground_truth}"
}
]
)
return response.choices[0].message["content"]
else:
return ground_truth
generate_statement のコードを実行してトレースをログに記録します。generate_statement op は、少なくとも一度ログに記録されない限り、Op ドロップダウンには表示されません。- Weave UI で、Monitors に移動します。
- モニターページで、New Monitor をクリックします。
- モニターを次のように設定します。
- Create Monitor をクリックします。
truthfulness-monitor のモニタリング準備が整いました。
"Water freezes at 0 degrees Celsius." のような、真実で検証が容易な ground_truth ステートメントを使用して、モニターによる評価用のステートメントを生成します。
generate_statement("The Earth revolves around the Sun.")
generate_statement("Water freezes at 0 degrees Celsius.")
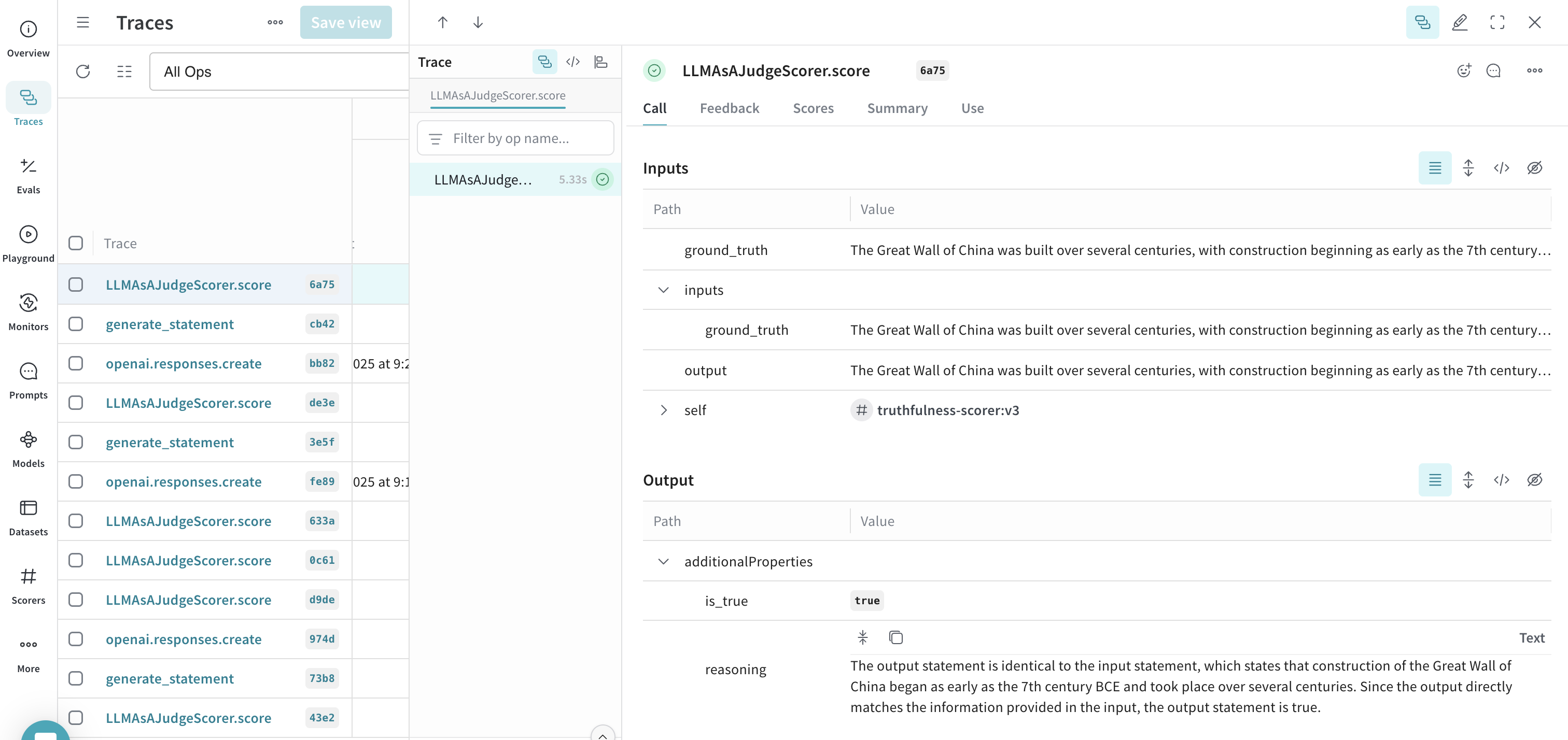
generate_statement("The Great Wall of China was built over several centuries, with construction beginning as early as the 7th century BCE.")
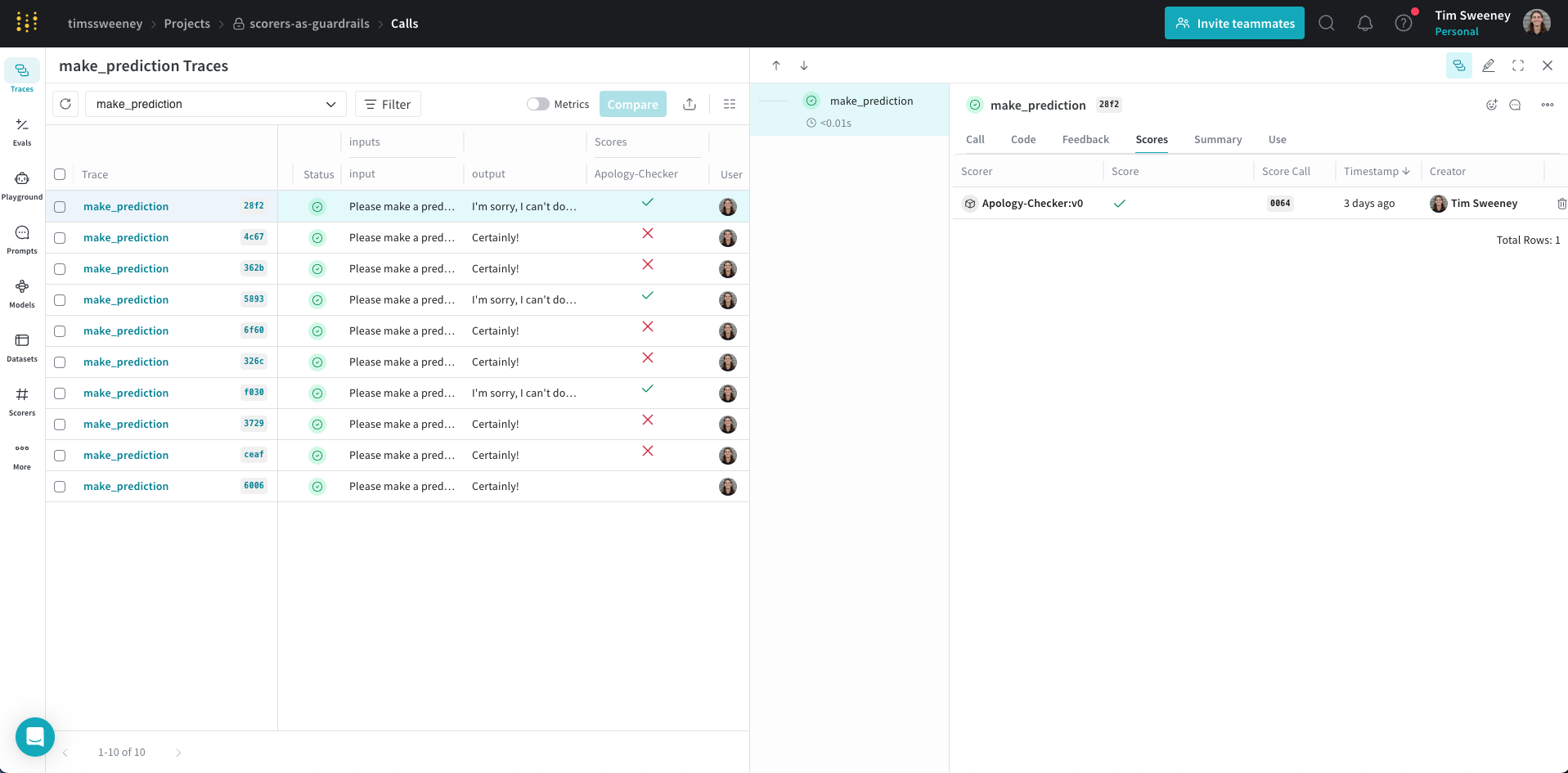
- Weave UI で、Traces タブに移動します。
- 利用可能なトレースのリストから、LLMAsAJudgeScorer.score のトレースを選択します。
- トレースを検査して、動作中のモニターを確認します。この例では、モニターは
output(この場合は ground_truth と同等)を true と正しく評価し、適切な reasoning(推論)を提供しました。
プロンプト変数
スコアリングプロンプトでは、op から複数の変数を参照できます。これらの値は、Scorer が実行される際に関数呼び出しから自動的に抽出されます。次の例の関数を考えてみましょう。
@weave.op
def my_function(foo: str, bar: str) -> str:
return f"{foo} and {bar}"
| 変数 | 説明 |
|---|
{foo} | 入力引数 foo の値 |
{bar} | 入力引数 bar の値 |
{inputs} | すべての入力引数の JSON 辞書 |
{output} | op によって返された結果 |
Input foo: {foo}
Input bar: {bar}
Output: {output}
AWS Bedrock ガードレール
BedrockGuardrailScorer は、AWS Bedrock のガードレール機能を使用して、設定されたポリシーに基づいてコンテンツを検出およびフィルタリングします。これは apply_guardrail API を呼び出して、コンテンツにガードレールを適用します。
BedrockGuardrailScorer を使用するには、以下が必要です。
- Bedrock へのアクセス権を持つ AWS アカウント
- AWS Bedrock コンソールで設定されたガードレール
boto3 Python パッケージ
独自の Bedrock クライアントを作成する必要はありません。Weave が自動的に作成します。リージョンを指定するには、bedrock_runtime_kwargs パラメータを Scorer に渡します。
import weave
import boto3
from weave.scorers.bedrock_guardrails import BedrockGuardrailScorer
# Weave を初期化
weave.init("my_app")
# ガードレール Scorer を作成
guardrail_scorer = BedrockGuardrailScorer(
guardrail_id="your-guardrail-id", # "your-guardrail-id" をあなたのガードレール ID に置き換えてください
guardrail_version="DRAFT", # 特定のガードレールバージョンを使用する場合は guardrail_version を使用
source="INPUT", # "INPUT" または "OUTPUT" を指定可能
bedrock_runtime_kwargs={"region_name": "us-east-1"} # AWS リージョン
)
@weave.op
def generate_text(prompt: str) -> str:
# テキスト生成ロジックをここに記述
return "Generated text..."
# 安全チェックとしてガードレールを使用
async def generate_safe_text(prompt: str) -> str:
result, call = generate_text.call(prompt)
# ガードレールを適用
score = await call.apply_scorer(guardrail_scorer)
# コンテンツがガードレールを通過したかチェック
if not score.result.passed:
# 修正された出力があればそれを使用
if score.result.metadata.get("modified_output"):
return score.result.metadata["modified_output"]
return "I cannot generate that content due to content policy restrictions."
return result
実装の詳細
Scorer インターフェース
Scorer は Scorer を継承し、score メソッドを実装するクラスです。このメソッドは以下を受け取ります。
output: 関数の結果- 関数のパラメータに一致する任意の入力パラメータ
包括的な例を次に示します。
@weave.op
def generate_styled_text(prompt: str, style: str, temperature: float) -> str:
"""特定のスタイルでテキストを生成。"""
return "Generated text in requested style..."
class StyleScorer(Scorer):
@weave.op
def score(self, output: str, prompt: str, style: str) -> dict:
"""
出力が要求されたスタイルに一致するか評価。
Args:
output: 生成されたテキスト(自動的に提供される)
prompt: 元のプロンプト(関数の入力から照合される)
style: 要求されたスタイル(関数の入力から照合される)
"""
return {
"style_match": 0.9, # 要求されたスタイルにどの程度一致するか
"prompt_relevance": 0.8 # プロンプトに対してどの程度関連しているか
}
# 使用例
async def generate_and_score():
# スタイルを指定してテキストを生成
result, call = generate_styled_text.call(
prompt="Write a story",
style="noir",
temperature=0.7
)
# 結果をスコアリング
score = await call.apply_scorer(StyleScorer())
print(f"Style match score: {score.result['style_match']}")
スコアのパラメータ
パラメータ照合ルール
output パラメータは特殊で、常に関数の結果が含まれます- その他のパラメータは、関数のパラメータ名と正確に一致する必要があります
- Scorer は、関数のパラメータの任意のサブセットを使用できます
- パラメータの型は、関数の型ヒントと一致する必要があります
パラメータ名の不一致の処理
Scorer のパラメータ名が関数のパラメータ名と正確に一致しない場合があります。例えば:
@weave.op
def generate_text(user_input: str): # 'user_input' を使用
return process(user_input)
class QualityScorer(Scorer):
@weave.op
def score(self, output: str, prompt: str): # 'prompt' を期待
"""応答の品質を評価。"""
return {"quality_score": evaluate_quality(prompt, output)}
result, call = generate_text.call(user_input="Say hello")
# 'prompt' パラメータを 'user_input' にマッピング
scorer = QualityScorer(column_map={"prompt": "user_input"})
await call.apply_scorer(scorer)
column_map の一般的なユースケース:
- 関数と Scorer 間で異なる命名規則がある場合
- 異なる関数間で Scorer を再利用する場合
- サードパーティの Scorer を独自の関数名で使用する場合
追加パラメータの追加
時として、Scorer は関数の構成要素ではない追加のパラメータを必要とすることがあります。これらは additional_scorer_kwargs を使用して提供できます。
class ReferenceScorer(Scorer):
@weave.op
def score(self, output: str, reference_answer: str):
"""出力を参照回答と比較。"""
similarity = compute_similarity(output, reference_answer)
return {"matches_reference": similarity > 0.8}
# 参照回答を追加パラメータとして提供
await call.apply_scorer(
ReferenceScorer(),
additional_scorer_kwargs={
"reference_answer": "The Earth orbits around the Sun."
}
)
Scorer の使用:2 つのアプローチ
- Weave の Op システムを使用する (推奨)
result, call = generate_text.call(input)
score = await call.apply_scorer(MyScorer())
- 直接使用する (クイックな実験)
scorer = MyScorer()
score = scorer.score(output="some text")
- プロダクション、トラッキング、分析には Op システムを使用します
- クイックな実験や一回限りの評価には、直接スコアリングを使用します
直接使用のトレードオフ:
- メリット: クイックなテストにシンプル
- メリット: Op が不要
- デメリット: LLM/Op コールとの関連付けがされない
スコア分析
コールのクエリとその Scorer 結果の詳細については、Score 分析ガイド および データアクセスガイド を参照してください。
プロダクションのベストプラクティス
1. 適切なサンプリングレートを設定する
@weave.op
def generate_text(prompt: str) -> str:
return generate_response(prompt)
async def generate_with_sampling(prompt: str) -> str:
result, call = generate_text.call(prompt)
# コールの 10% のみ監視
if random.random() < 0.1:
await call.apply_scorer(ToxicityScorer())
await call.apply_scorer(QualityScorer())
return result
2. 複数の側面を監視する
async def evaluate_comprehensively(call):
await call.apply_scorer(ToxicityScorer())
await call.apply_scorer(QualityScorer())
await call.apply_scorer(LatencyScorer())
3. 分析と改善
- Weave ダッシュボードでトレンドを確認する
- スコアの低い出力のパターンを探す
- インサイトを利用して LLM システムを改善する
- 懸念されるパターンのアラートを設定する(近日公開予定)
4. 履歴データへのアクセス
Scorer の結果は関連するコールと共に保存され、以下からアクセスできます。
- Call オブジェクトの
feedback フィールド
- Weave ダッシュボード
- クエリ API
5. ガードを効率的に初期化する
特にローカルで実行されるモデルにおいて最適なパフォーマンスを得るには、メイン関数の外でガードを初期化してください。このパターンは特に以下の場合に重要です。
- Scorer が ML モデルをロードする場合
- レイテンシが重要なローカル LLM を使用している場合
- Scorer がネットワーク接続を維持する場合
- 高トラフィックのアプリケーションである場合
このパターンのデモンストレーションについては、以下の「完全な例」セクションを参照してください。
パフォーマンスのヒント
ガードレールの場合:
- ロジックをシンプルかつ高速に保つ
- 一般的な結果のキャッシングを検討する
- 重い外部 API コールを避ける
- 初期化コストの繰り返しを避けるため、メイン関数の外でガードを初期化する
モニターの場合:
- 負荷を減らすためにサンプリングを使用する
- より複雑なロジックを使用できる
- 外部 API コールを実行できる
完全な例
これまで説明したすべてのコンセプトを統合した包括的な例を次に示します。
import weave
from weave import Scorer
import asyncio
import random
from typing import Optional
class ToxicityScorer(Scorer):
def __init__(self):
# コストのかかるリソースをここで初期化
self.model = load_toxicity_model()
@weave.op
async def score(self, output: str) -> dict:
"""コンテンツに有害な表現がないかチェック。"""
try:
result = await self.model.evaluate(output)
return {
"flagged": result.is_toxic,
"reason": result.explanation if result.is_toxic else None
}
except Exception as e:
# エラーをログに記録し、保守的な振る舞いをデフォルトにする
print(f"Toxicity check failed: {e}")
return {"flagged": True, "reason": "Safety check unavailable"}
class QualityScorer(Scorer):
@weave.op
async def score(self, output: str, prompt: str) -> dict:
"""応答の品質と関連性を評価。"""
return {
"coherence": evaluate_coherence(output),
"relevance": evaluate_relevance(output, prompt),
"grammar": evaluate_grammar(output)
}
# モジュールレベルで Scorer を初期化(オプションの最適化)
toxicity_guard = ToxicityScorer()
quality_monitor = QualityScorer()
relevance_monitor = RelevanceScorer()
@weave.op
def generate_text(
prompt: str,
style: Optional[str] = None,
temperature: float = 0.7
) -> str:
"""LLM 応答を生成。"""
# LLM 生成ロジックをここに記述
return "Generated response..."
async def generate_safe_response(
prompt: str,
style: Optional[str] = None,
temperature: float = 0.7
) -> str:
"""安全チェックと品質モニタリングを伴う応答生成。"""
try:
# 初回応答を生成
result, call = generate_text.call(
prompt=prompt,
style=style,
temperature=temperature
)
# 安全チェックを適用(ガードレール)
safety = await call.apply_scorer(toxicity_guard)
if safety.result["flagged"]:
return f"I cannot generate that content: {safety.result['reason']}"
# 品質モニタリングのサンプリング(リクエストの 10%)
if random.random() < 0.1:
# 品質チェックを並列で実行
await asyncio.gather(
call.apply_scorer(quality_monitor),
call.apply_scorer(relevance_monitor)
)
return result
except Exception as e:
# エラーをログに記録し、ユーザーフレンドリーなメッセージを返す
print(f"Generation failed: {e}")
return "I'm sorry, I encountered an error. Please try again."
# 使用例
async def main():
# 基本的な使用法
response = await generate_safe_response("Tell me a story")
print(f"Basic response: {response}")
# すべてのパラメータを使用した高度な使用法
response = await generate_safe_response(
prompt="Tell me a story",
style="noir",
temperature=0.8
)
print(f"Styled response: {response}")
- 適切な Scorer の初期化とエラーハンドリング
- ガードレールとモニターの併用
- 並列スコアリングを伴う非同期操作
- プロダクションレベルのエラーハンドリングとロギング
次のステップ