- Python
- TypeScript
Scorers は評価中に
weave.Evaluation オブジェクトに渡されます。Weave には 2 種類の Scorer があります。- 関数ベースの Scorers:
@weave.opでデコレートされたシンプルな Python 関数。 - クラスベースの Scorers: より複雑な評価のために
weave.Scorerを継承した Python クラス。
独自の Scorer を作成する
関数ベースの Scorers
- Python
- TypeScript
これらは 評価が実行されると、
@weave.op でデコレートされ、辞書を返す関数です。以下のようなシンプルな評価に最適です。evaluate_uppercase はテキストがすべて大文字かどうかをチェックします。クラスベースの Scorers
- Python
- TypeScript
より高度な評価、特に追加の Scorer メタデータを追跡する必要がある場合や、LLM エバリュエーターに異なるプロンプトを試す場合、または複数の関数呼び出しを行う場合には、 このクラスは、元のテキストと比較して要約がどれだけ優れているかを評価します。
Scorer クラスを使用できます。要件:weave.Scorerを継承すること。@weave.opでデコレートされたscoreメソッドを定義すること。scoreメソッドは辞書を返すこと。
Scorer の仕組み
Scorer のキーワード引数
- Python
- TypeScript
Scorers は AI システムからの出力と、データセットの行からの入力データの両方にアクセスできます。Weave の
これで、
- 入力: Scorer にデータセット行のデータ( “label” や “target” 列など)を使用させたい場合は、Scorer の定義に
labelやtargetといったキーワード引数を追加するだけで、簡単に利用可能になります。
score クラスメソッド)のパラメータリストは以下のようになります。Evaluation が実行されると、AI システムの出力が output パラメータに渡されます。また、 Evaluation は追加の Scorer 引数名をデータセットの列名に自動的に一致させようと試みます。Scorer の引数やデータセットの列をカスタマイズすることが難しい場合は、後述するカラムマッピングを使用できます。- 出力: AI システムの出力にアクセスするために、Scorer 関数のシグネチャに
outputパラメータを含めてください。
column_map による列名のマッピング
score メソッドの引数名がデータセットの列名と一致しないことがあります。これは column_map を使用して解決できます。クラスベースの Scorer を使用している場合は、Scorer クラスを初期化する際に column_map 属性に辞書を渡します。この辞書は、 score メソッドの引数名をデータセットの列名に {scorer_keyword_argument: dataset_column_name} の形式でマッピングします。例:score メソッドの text 引数は news_article データセット列からデータを受け取ります。備考:- 列をマッピングするためのもう一つの同等なオプションは、
Scorerをサブクラス化し、列を明示的にマッピングするようにscoreメソッドをオーバーロードすることです。
Scorer の最終的な集計 (summarization)
- Python
- TypeScript
評価中、Scorer はデータセットの各行に対して計算されます。評価の最終的なスコアを提供するために、出力の返り値の型に応じた
auto_summarize 機能を提供しています。- 数値列については平均値が計算されます
- ブール値列についてはカウントと割合が計算されます
- その他の列タイプは無視されます
Scorer クラスの summarize メソッドをオーバーライドして、最終スコアを計算する独自の方法を提供できます。 summarize 関数は以下を期待します。- 単一のパラメータ
score_rows: これは辞書のリストで、各辞書にはデータセットの 1 行に対してscoreメソッドから返されたスコアが含まれます。 - 集計されたスコアを含む辞書を返す必要があります。
この例では、デフォルトの auto_summarize は True のカウントと割合を返していたはずです。
詳細については、 CorrectnessLLMJudge の実装を確認してください。Call への Scorer の適用
Weave の ops に Scorer を適用するには、操作の結果とその追跡情報の両方にアクセスできる.call() メソッドを使用する必要があります。これにより、Scorer の結果を Weave データベース内の特定の call に関連付けることができます。
.call() メソッドの使用方法の詳細については、 Calling Ops ガイドを参照してください。
- Python
- TypeScript
基本的な例を次に示します。同じ call に対して複数の Scorer を適用することもできます。備考:
- Scorer の結果は自動的に Weave のデータベースに保存されます
- Scorer はメインの操作が完了した後、非同期で実行されます
- Scorer の結果は UI で表示したり、API 経由でクエリしたりできます
preprocess_model_input の使用
preprocess_model_input パラメータを使用すると、評価中にデータセットの例がモデルに到達する前にそれらを変更できます。
使用方法と例については、 Using preprocess_model_input to format dataset rows before evaluating を参照してください。
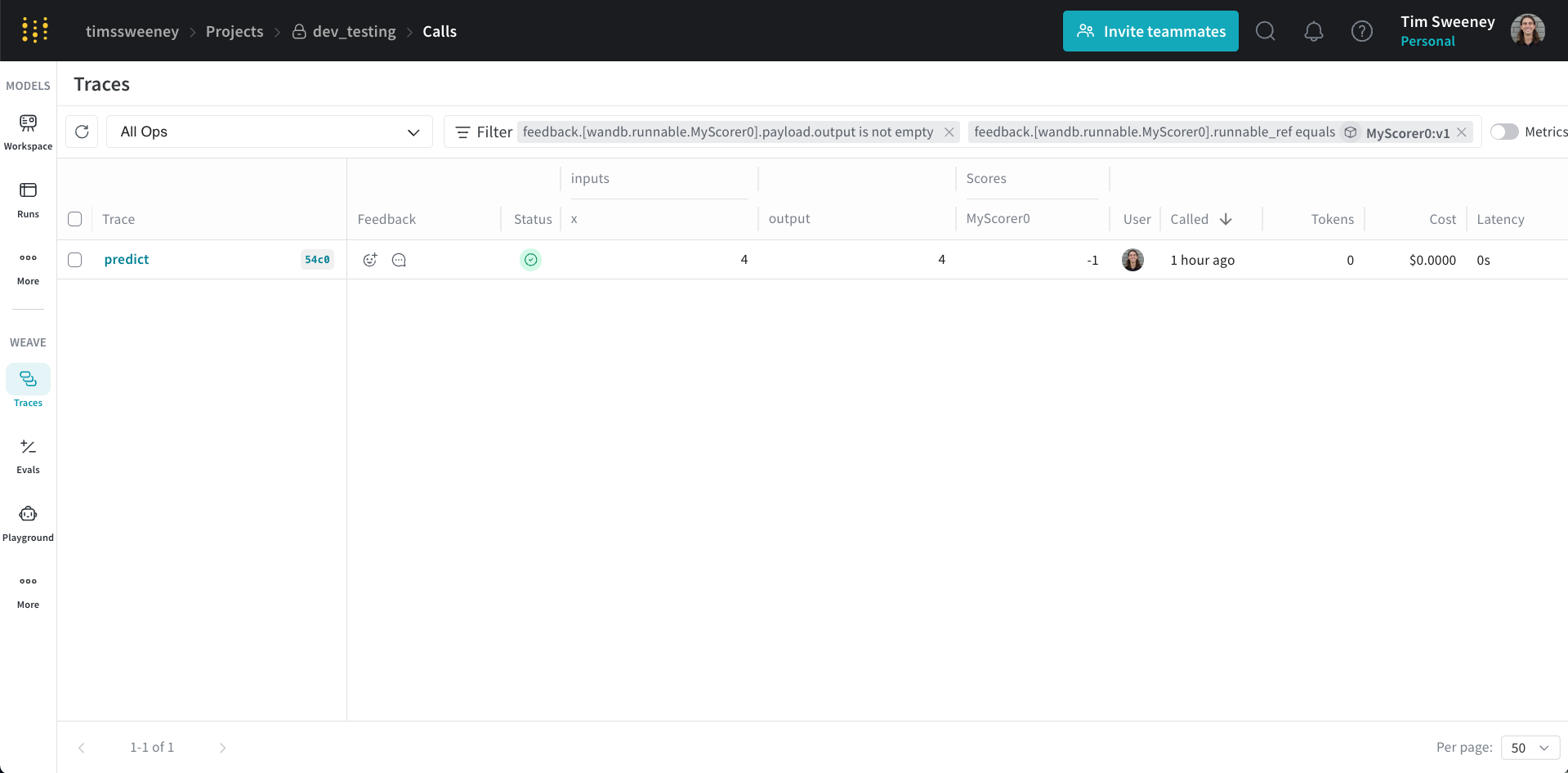
スコア分析
このセクションでは、単一の call、複数の call、および特定の Scorer によってスコアリングされたすべての call のスコアを分析する方法を説明します。単一の Call のスコアを分析する
単一 Call API
単一の call に対する呼び出しを取得するには、get_call メソッドを使用できます。
単一 Call UI
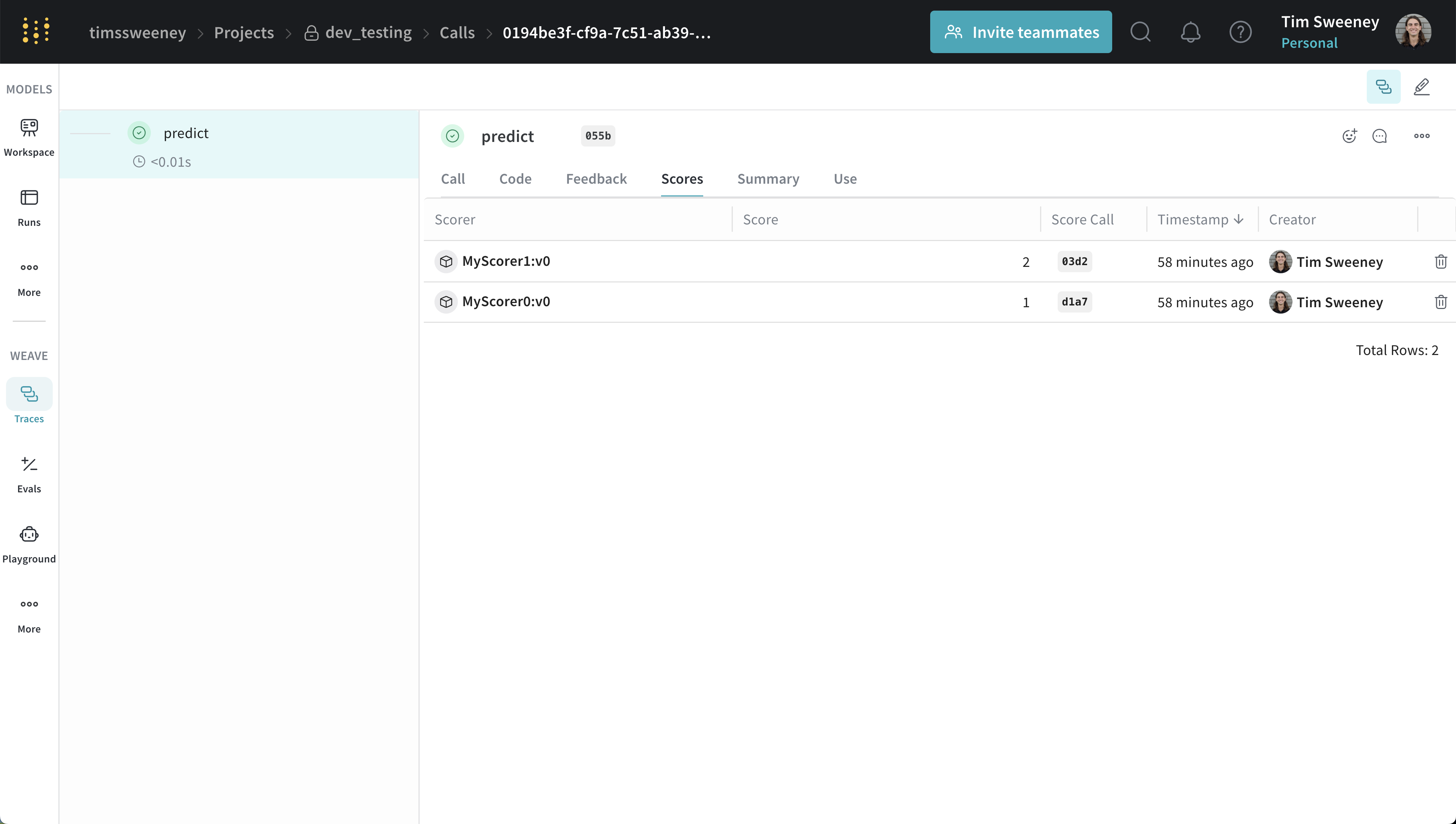
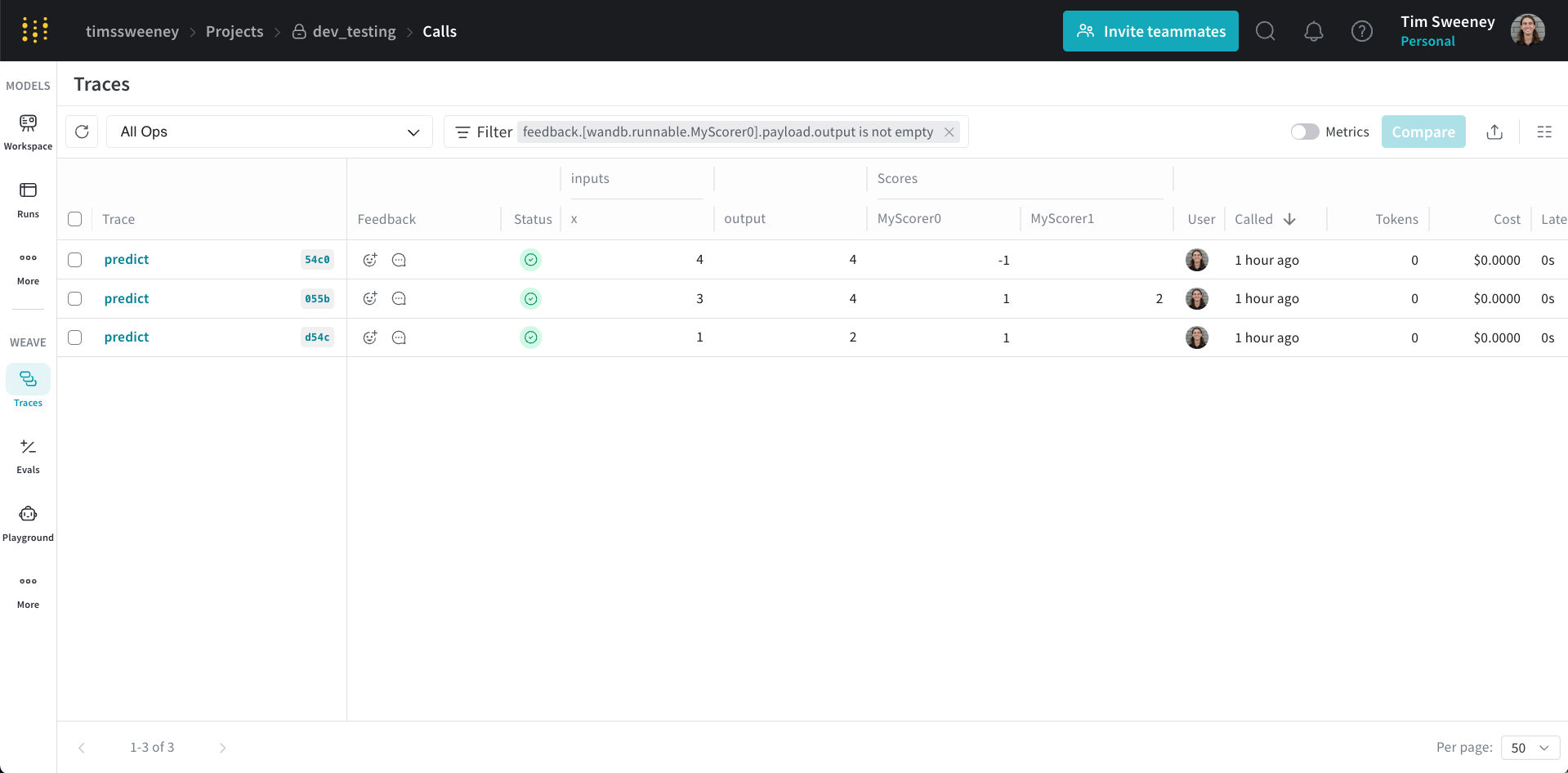
複数の Call のスコアを分析する
複数 Call API
複数の call に対する呼び出しを取得するには、get_calls メソッドを使用できます。
複数 Call UI
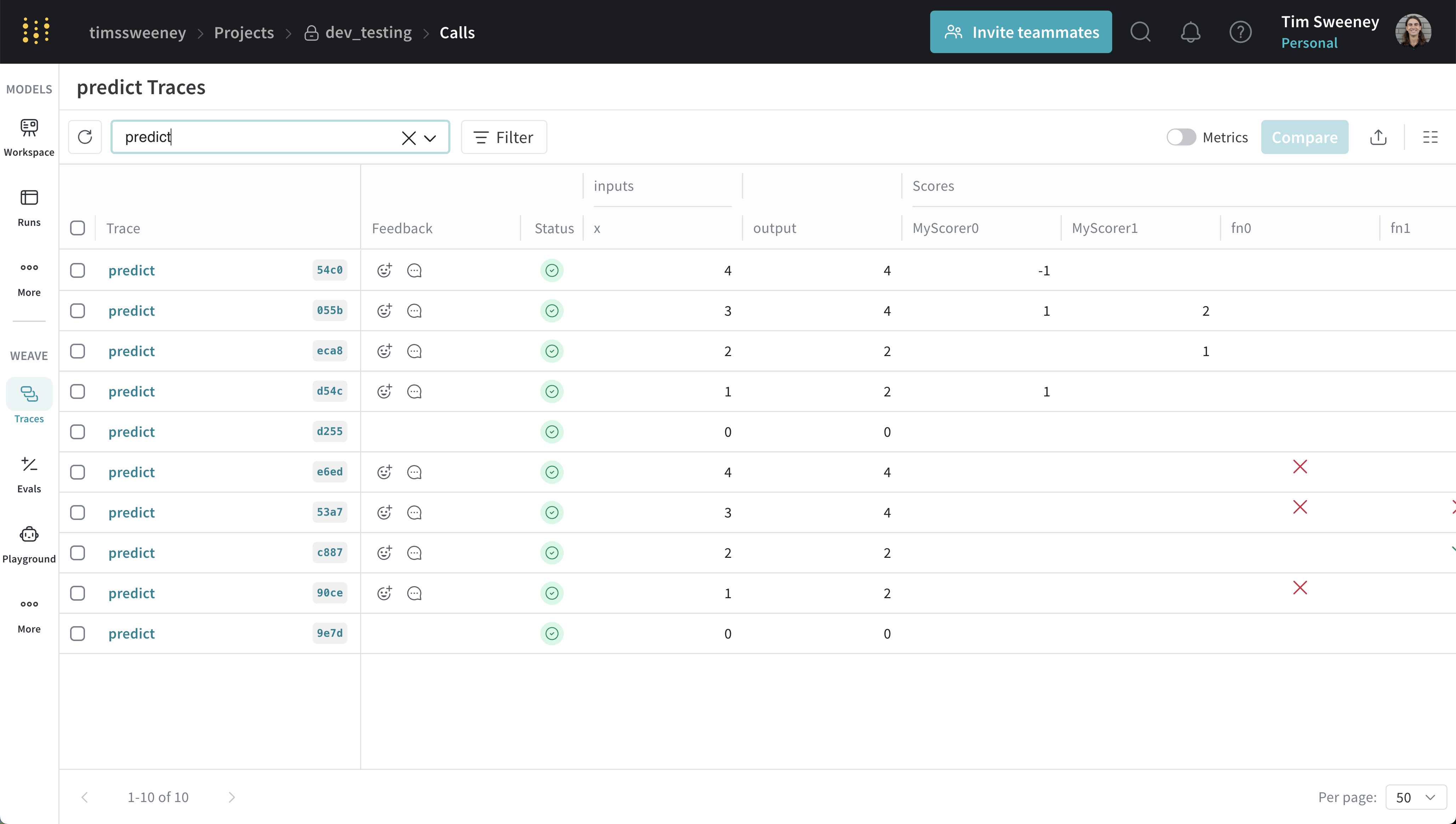
特定の Scorer によってスコアリングされたすべての Call を分析する
Scorer ごとの全 Call API
特定の Scorer によってスコアリングされたすべての call を取得するには、get_calls メソッドを使用できます。
Scorer ごとの全 Call UI
最後に、Scorer によってスコアリングされたすべての call を確認したい場合は、UI の Scorers タブに移動し、 “Programmatic Scorer” タブを選択します。対象の Scorer をクリックして Scorer 詳細ページを開きます。
Scores の下にある View Traces ボタンをクリックして、その Scorer によってスコアリングされたすべての call を表示します。