- モデルパフォーマンスの回帰(デグレード)の追跡
- 共有された評価ワークフローの調整
Leaderboard の作成は、Weave UI および Weave Python SDK でのみ利用可能です。TypeScript ユーザーは Weave UI を使用して Leaderboard を作成および管理できます。
Leaderboard の作成
Leaderboard は Weave UI または プログラム から作成できます。UI を使用する場合
Weave UI で直接 Leaderboard を作成・カスタマイズするには:- Weave UI で Leaders セクションに移動します。表示されていない場合は、More → Leaders をクリックします。
- + New Leaderboard をクリックします。
- Leaderboard Title フィールドに、分かりやすい名前(例:
summarization-benchmark-v1)を入力します。 - 任意で、この Leaderboard が何を比較するものか説明を追加します。
- 列を追加 して、表示する評価とメトリクスを定義します。
- レイアウトが完成したら、Leaderboard を保存して公開し、他のユーザーと共有します。
列を追加する
Leaderboard の各列は、特定の評価からのメトリクスを表します。列を設定するには、以下を指定します:- Evaluation: ドロップダウンから評価 run を選択します(事前に作成されている必要があります)。
- Scorer: その評価で使用されたスコアリング関数(例:
jaccard_similarity,simple_accuracy)を選択します。 - Metric: 表示する集計メトリクスを選択します(例:
mean,true_fractionなど)。
⋯) をクリックします。以下の操作が可能です:
- Move before / after – 列の順序を入れ替える
- Duplicate – 列の定義をコピーする
- Delete – 列を削除する
- Sort ascending – Leaderboard のデフォルトのソート順を設定する(再度クリックすると降順に切り替わります)
Python
Leaderboard を作成して公開するには:-
テスト用の Datasets を定義します。組み込みの
Datasetを使用するか、入力とターゲットのリストを手動で定義できます。 -
1 つ以上の scorers を定義します。
-
Evaluationを作成します。 -
評価対象の Models を定義します。
-
評価を実行します。
-
Leaderboard を作成します。
-
Leaderboard を公開します。
-
結果を取得します。
エンドツーエンドの Python 例
次の例では、Weave Evaluations を使用し、共通のデータセット上で 3 つの要約モデルをカスタムメトリクスを用いて比較する Leaderboard を作成します。小さなベンチマークを作成し、各モデルを評価し、Jaccard 類似度 で各モデルをスコアリングし、その結果を Weave Leaderboard に公開します。Leaderboard の表示と解釈
スクリプトの実行が完了したら、Leaderboard を確認します:- Weave UI で Leaders タブに移動します。表示されていない場合は More をクリックし、Leaders を選択します。
- 作成した Leaderboard の名前(例:
Summarization Model Comparison)をクリックします。
model_humanlike, model_vanilla, model_messy)を表します。mean 列は、モデルの出力と参照用要約との間の平均 Jaccard 類似度を示しています。
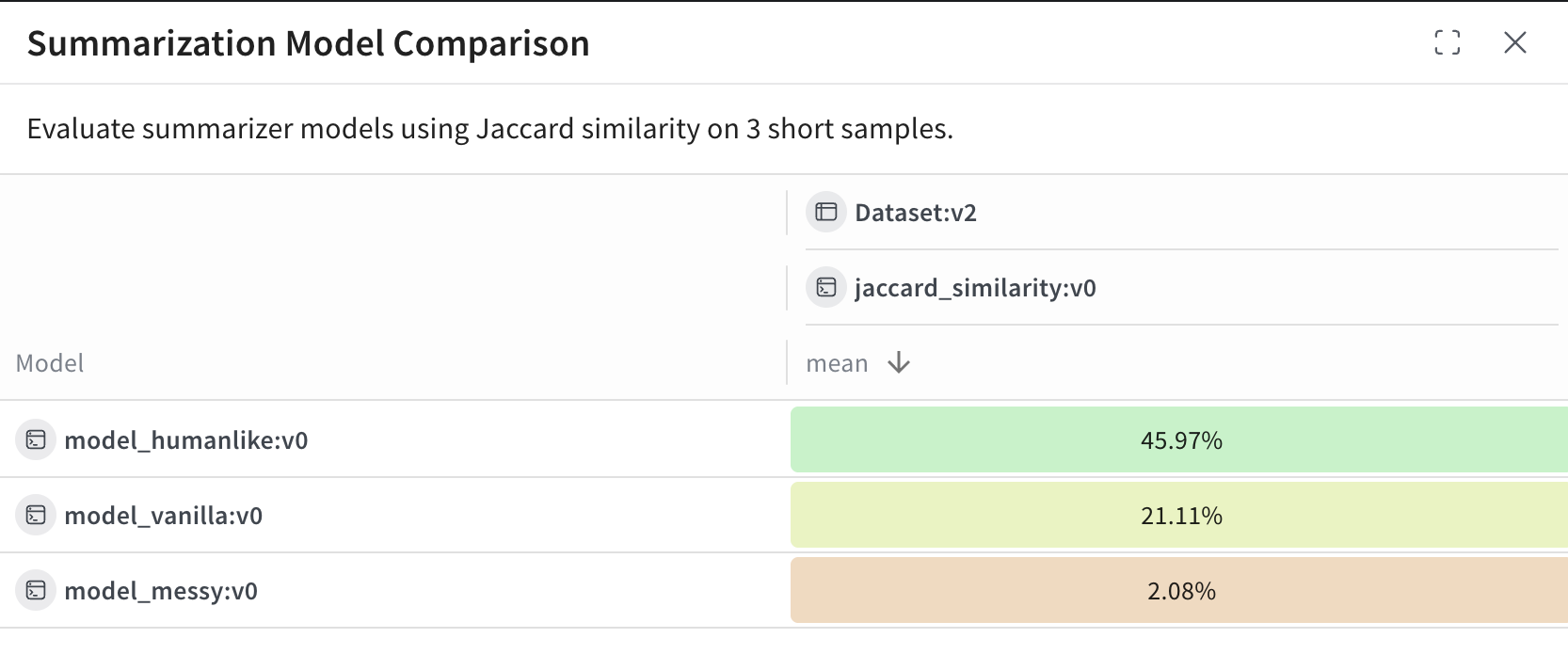
model_humanlikeが最も優れており、約 46% の重複があります。model_vanilla(単純な切り捨て)は約 21% です。- 意図的に質の低くした
model_messyは、約 2% のスコアとなります。