Dataset は、プログラムまたは UI を通じて作成および操作できます。
このページでは以下について説明します:
- Python および TypeScript における基本的な
Dataset操作と開始方法 - Weave calls などのオブジェクトから Python および TypeScript で
Datasetを作成する方法 - UI で利用可能な
Dataset操作
Dataset クイックスタート
以下のコードサンプルは、Python と TypeScript を使用して基本的な Dataset 操作を行う方法を示しています。SDK を使用して以下のことが可能です。
Datasetの作成Datasetのパブリッシュ(公開)Datasetの取得Dataset内の特定のサンプルへのアクセス
- Python
- TypeScript
他のオブジェクトから Dataset を作成する
- Python
- TypeScript
Python では、次に、
Dataset は calls のような一般的な Weave オブジェクトや、pandas.DataFrame のような Python オブジェクトからも構築できます。この機能は、特定のサンプルからサンプルの Dataset を作成したい場合に便利です。Weave call
1つ以上の Weave call からDataset を作成するには、call オブジェクトを取得し、それらを from_calls メソッドのリストに追加します。Pandas DataFrame
Pandas のDataFrame オブジェクトから Dataset を作成するには、from_pandas メソッドを使用します。Dataset を元に戻すには、to_pandas を使用します。Hugging Face Datasets
Hugging Face のdatasets.Dataset または datasets.DatasetDict オブジェクトから Dataset を作成するには、まず必要な依存関係がインストールされていることを確認してください。from_hf メソッドを使用します。複数の split(‘train’、‘test’、‘validation’ など)を持つ DatasetDict を指定した場合、Weave は自動的に ‘train’ split を使用し、警告を表示します。‘train’ split が存在しない場合は、エラーが発生します。特定の split を直接指定することもできます(例:hf_dataset_dict['test'])。weave.Dataset を Hugging Face の Dataset に戻すには、to_hf メソッドを使用します。UI での Dataset の作成、編集、削除
UI 上で Dataset の作成、編集、削除を行うことができます。
新しい Dataset を作成する
- 編集したい Weave プロジェクトに移動します。
- サイドバーで Traces を選択します。
-
新しい
Datasetを作成したい 1つまたは複数の call を選択します。 - 右上のメニューで、Add selected rows to a dataset アイコン(ゴミ箱アイコンの隣)をクリックします。
- Choose a dataset ドロップダウンから Create new を選択します。Dataset name フィールドが表示されます。
-
Dataset name フィールドに、データセットの名前を入力します。Configure dataset fields のオプションが表示されます。
データセット名は英数字で始まる必要があり、英数字、ハイフン、アンダースコアのみを使用できます。
-
(オプション) Configure dataset fields で、データセットに含める call のフィールドを選択します。
- 選択した各フィールドの列名をカスタマイズできます。
- フィールドのサブセットを選択して新しい
Datasetに含めるか、すべてのフィールドの選択を解除できます。
-
データセットのフィールドを設定したら、Next をクリックします。新しい
Datasetのプレビューが表示されます。 - (オプション) Dataset 内の編集可能なフィールドをクリックして、エントリを編集します。
- Create dataset をクリックします。新しいデータセットが作成されます。
-
確認ポップアップで、View the dataset をクリックして新しい
Datasetを表示します。または、Datasets タブに移動します。
Dataset を編集する
-
編集したい
Datasetが含まれる Weave プロジェクトに移動します。 -
サイドバーから Datasets を選択します。利用可能な
Datasetが表示されます。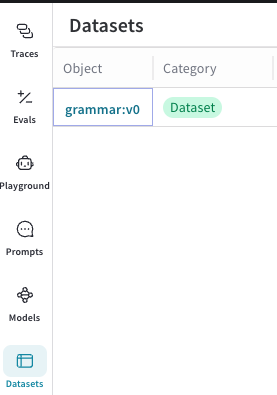
-
Object 列で、編集したい
Datasetの名前とバージョンをクリックします。名前、バージョン、作成者、およびDatasetの行などのDataset情報を表示するポップアウトモーダルが表示されます。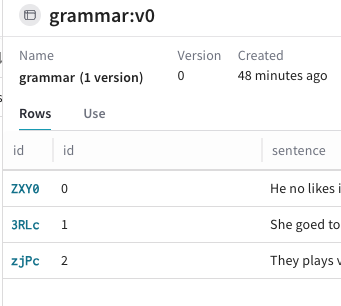
-
モダルの右上隅にある Edit dataset ボタン(鉛筆アイコン)をクリックします。モダンの下部に + Add row ボタンが表示されます。

-
+ Add row をクリックします。既存の
Dataset行の上部に緑色の行が表示され、Datasetに新しい行を追加できることを示します。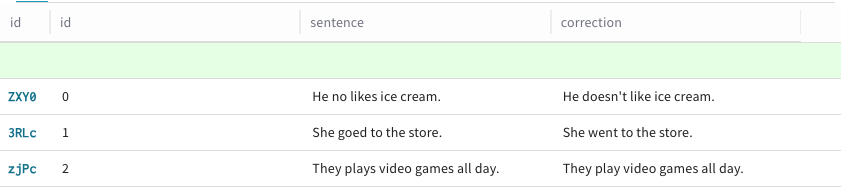
-
新しい行にデータを追加するには、その行の中の目的の列をクリックします。
Dataset行のデフォルトの id 列は、作成時に Weave が自動的に割り当てるため、編集できません。書式設定用の Text、Code、Diff オプションを備えた編集モーダルが表示されます。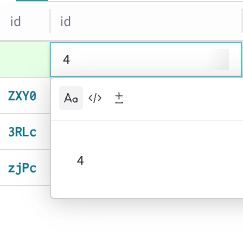
-
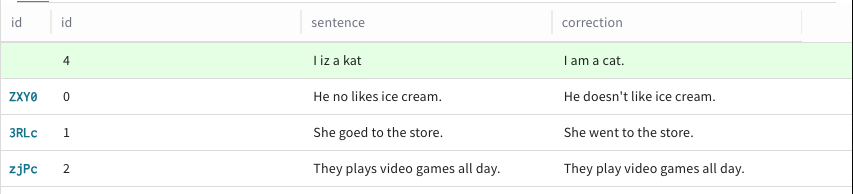
新しい行に追加したい各列について、ステップ 6 を繰り返します。
-
Datasetに追加したい各行について、ステップ 5 を繰り返します。 -
編集が完了したら、モダールの右上隅にある Publish をクリックして
Datasetをパブリッシュします。変更をパブリッシュしたくない場合は、Cancel をクリックします。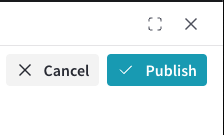
Datasetが UI で利用可能になります。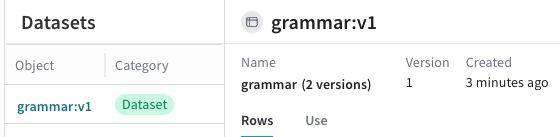

Dataset を削除する
-
編集したい
Datasetが含まれる Weave プロジェクトに移動します。 -
サイドバーから Datasets を選択します。利用可能な
Datasetが表示されます。 -
Object 列で、削除したい
Datasetの名前とバージョンをクリックします。名前、バージョン、作成者、およびDatasetの行などのDataset情報を表示するポップアウトモーダルが表示されます。 -
モダルの右上隅にあるゴミ箱アイコンをクリックします。
Datasetの削除を確認するポップアップモーダルが表示されます。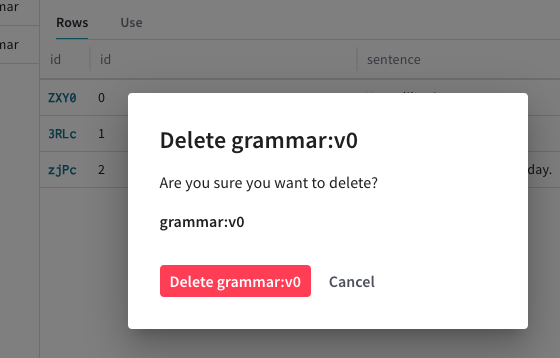
-
ポップアップモーダルで、赤色の Delete ボタンをクリックして
Datasetを削除します。削除したくない場合は、Cancel をクリックします。 これでDatasetが削除され、Weave ダッシュボードの Datasets タブに表示されなくなります。
Dataset に新しいサンプルを追加する
- 編集したい Weave プロジェクトに移動します。
- サイドバーで Traces を選択します。
-
新しいサンプルを作成したい
Datasetsを持つ 1つまたは複数の call を選択します。 - 右上のメニューで、Add selected rows to a dataset アイコン(ゴミ箱アイコンの隣)をクリックします。オプションで、Show latest versions をオフに切り替えると、利用可能なすべてのデータセットのすべてのバージョンが表示されます。
-
Choose a dataset ドロップダウンから、サンプルを追加したい
Datasetを選択します。Configure field mapping のオプションが表示されます。 - (オプション) Configure field mapping で、call のフィールドから対応するデータセット列へのマッピングを調整できます。
-
フィールドマッピングを設定したら、Next をクリックします。新しい
Datasetのプレビューが表示されます。 - 空の行(緑色)に、新しいサンプルの値を追加します。id フィールドは編集できず、Weave によって自動的に作成されることに注意してください。
- Add to dataset をクリックします。または、Configure field mapping 画面に戻るには、Back をクリックします。
-
確認ポップアップで、View the dataset をクリックして変更を確認します。または、Datasets タブに移動して
Datasetの更新を確認します。
その他のデータセット操作
- Python
- TypeScript