- クイックアクセス: W&B サイドバーから新しいセッションとして、または Call ページから既存のプロジェクトをテストするために Playground を開くことができます。
- メッセージコントロール: チャット内で直接メッセージの編集、再試行、削除が可能です。
- 柔軟なメッセージング: ユーザー入力またはシステム入力として新しいメッセージを追加し、LLM に送信できます。
- カスタマイズ可能な設定: お好みの LLM プロバイダーを選択し、モデル設定を調整できます。
- マルチ LLM サポート: チームレベルの API キー管理により、モデルを簡単に切り替えられます。
- モデル比較: プロンプトに対して異なるモデルがどのように応答するかを比較できます。
- カスタムプロバイダー: カスタムモデル用の OpenAI 互換 API エンドポイントをテストできます。
- 保存済みモデル: ワークフローに合わせて再利用可能なモデルプリセットを作成および設定できます。
事前準備
Playground を使用する前に、プロバイダーの認証情報の追加 と Playground UI の表示 を行う必要があります。プロバイダーの認証情報と情報の追加
Playground は現在、OpenAI、Anthropic、Google、Groq、Amazon Bedrock、Microsoft Azure のモデルをサポートしています。利用可能なモデルを使用するには、W&B 設定のチームシークレットに適切な情報を追加してください。- OpenAI:
OPENAI_API_KEY - Anthropic:
ANTHROPIC_API_KEY - Google:
GEMINI_API_KEY - Groq:
GROQ_API_KEY - Amazon Bedrock:
AWS_ACCESS_KEY_IDAWS_SECRET_ACCESS_KEYAWS_REGION_NAME
- Azure:
AZURE_API_KEYAZURE_API_BASEAZURE_API_VERSION
- X.AI:
XAI_API_KEY
- Deepseek
DEEPSEEK_API_KEY
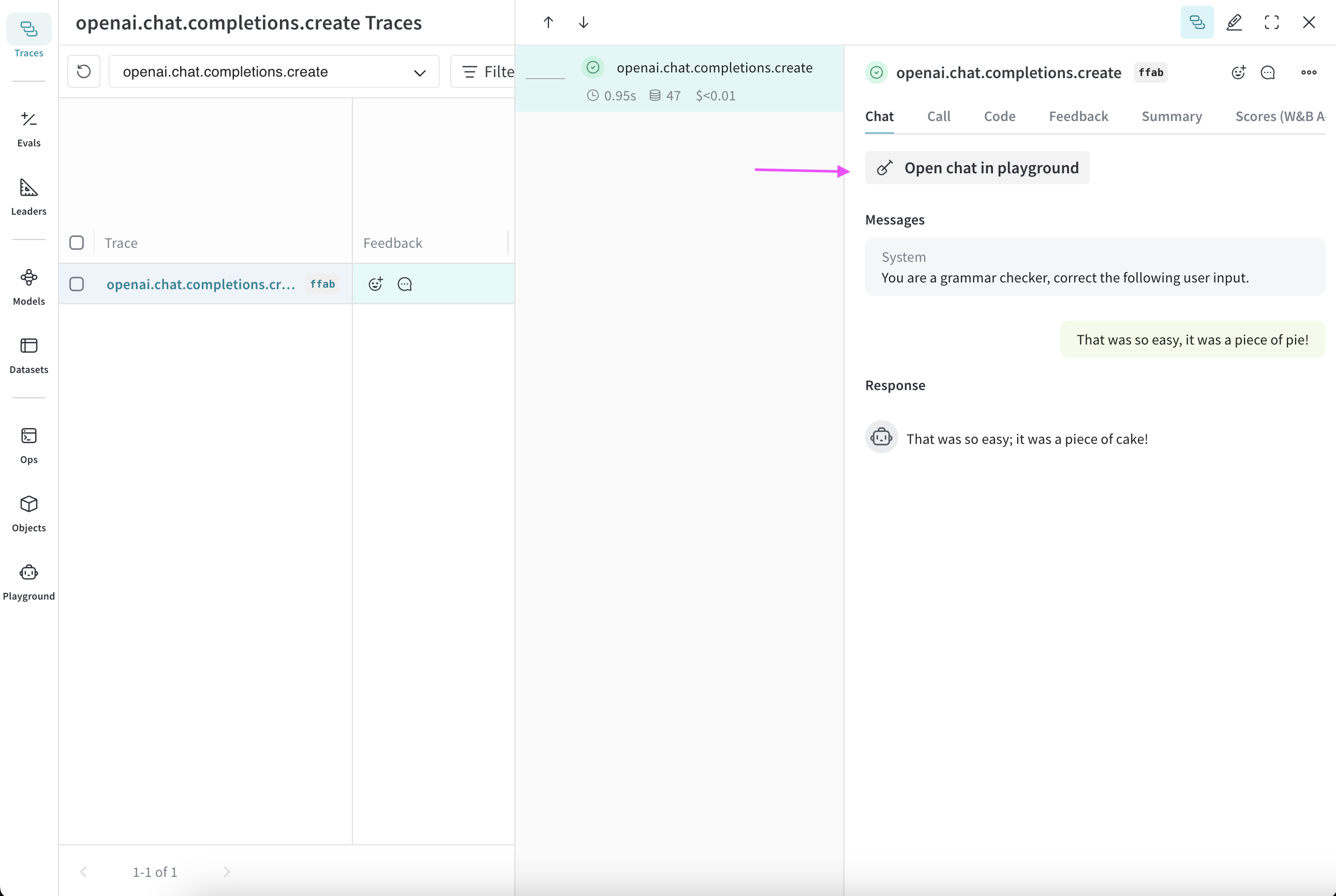
Playground へのアクセス
Playground にアクセスするには 2 つの方法があります。- シンプルなシステムプロンプトで新しい Playground ページを開く: サイドバーで Playground を選択します。Playground が同じタブで開きます。
- 特定の Call に対して Playground を開く:
- サイドバーで Traces タブを選択します。トレースのリストが表示されます。
- トレースリストで、表示したい Call の名前をクリックします。Call の詳細ページが開きます。
- Open chat in playground をクリックします。Playground が新しいタブで開きます。
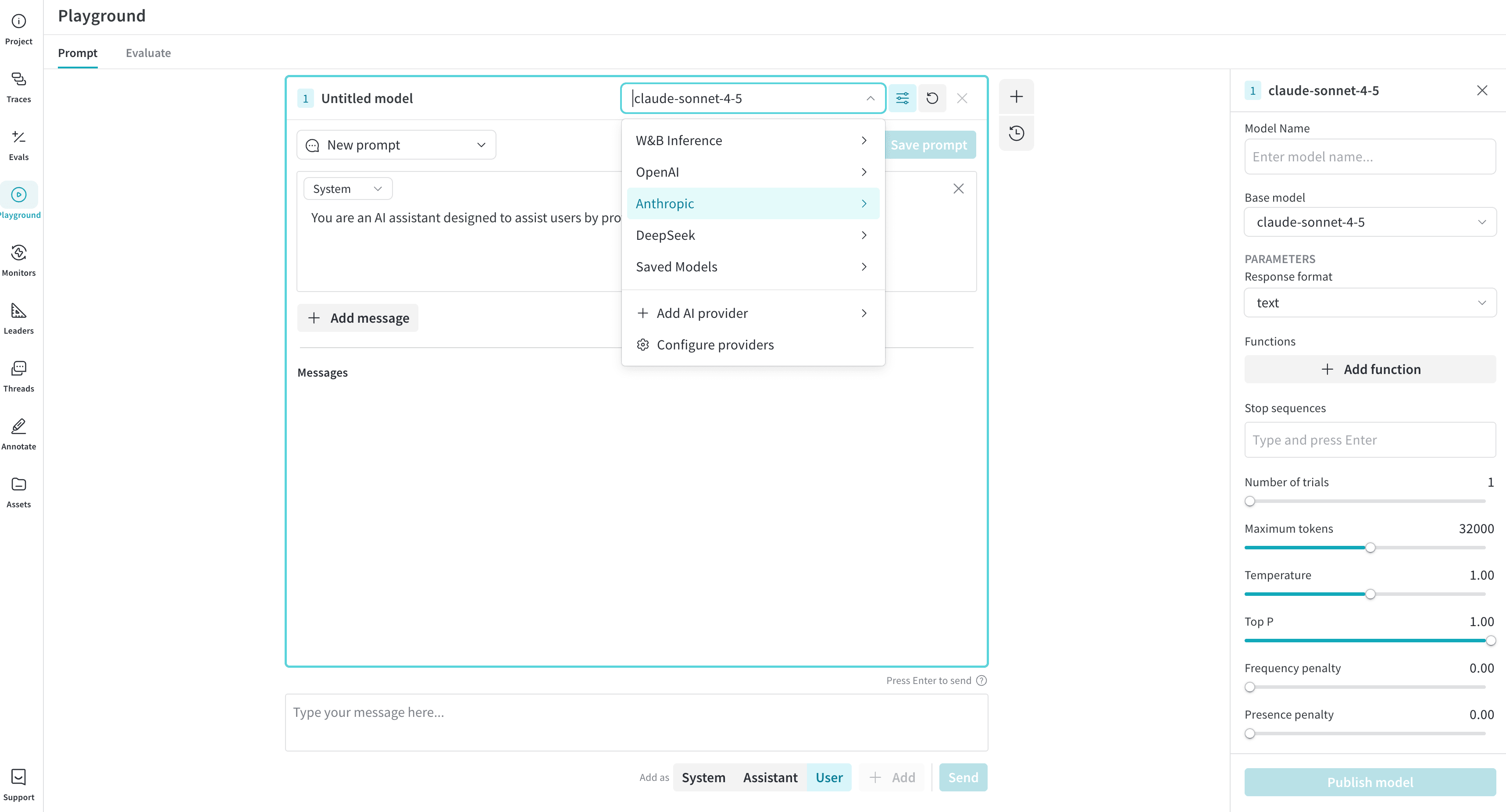
LLM の選択
左上のドロップダウンメニューを使用して LLM を切り替えることができます。各プロバイダーから利用可能なモデルは以下の通りです。Amazon Bedrock
- ai21.j2-mid-v1
- ai21.j2-ultra-v1
- amazon.nova-micro-v1:0
- amazon.nova-lite-v1:0
- amazon.nova-pro-v1:0
- amazon.titan-text-lite-v1
- amazon.titan-text-express-v1
- mistral.mistral-7b-instruct-v0:2
- mistral.mixtral-8x7b-instruct-v0:1
- mistral.mistral-large-2402-v1:0
- mistral.mistral-large-2407-v1:0
- anthropic.claude-3-sonnet-20240229-v1:0
- anthropic.claude-3-5-sonnet-20240620-v1:0
- anthropic.claude-3-haiku-20240307-v1:0
- anthropic.claude-3-opus-20240229-v1:0
- anthropic.claude-v2
- anthropic.claude-v2:1
- anthropic.claude-instant-v1
- cohere.command-text-v14
- cohere.command-light-text-v14
- cohere.command-r-plus-v1:0
- cohere.command-r-v1:0
- meta.llama2-13b-chat-v1
- meta.llama2-70b-chat-v1
- meta.llama3-8b-instruct-v1:0
- meta.llama3-70b-instruct-v1:0
- meta.llama3-1-8b-instruct-v1:0
- meta.llama3-1-70b-instruct-v1:0
- meta.llama3-1-405b-instruct-v1:0
Anthropic
- claude-3-7-sonnet-20250219
- claude-3-5-sonnet-20240620
- claude-3-5-sonnet-20241022
- claude-3-haiku-20240307
- claude-3-opus-20240229
- claude-3-sonnet-20240229
Azure
- azure/o1-mini
- azure/o1-mini-2024-09-12
- azure/o1
- azure/o1-preview
- azure/o1-preview-2024-09-12
- azure/gpt-4o
- azure/gpt-4o-2024-08-06
- azure/gpt-4o-2024-11-20
- azure/gpt-4o-2024-05-13
- azure/gpt-4o-mini
- azure/gpt-4o-mini-2024-07-18
- gemini/gemini-2.5-pro-preview-03-25
- gemini/gemini-2.0-pro-exp-02-05
- gemini/gemini-2.0-flash-exp
- gemini/gemini-2.0-flash-001
- gemini/gemini-2.0-flash-thinking-exp
- gemini/gemini-2.0-flash-thinking-exp-01-21
- gemini/gemini-2.0-flash
- gemini/gemini-2.0-flash-lite
- gemini/gemini-2.0-flash-lite-preview-02-05
- gemini/gemini-1.5-flash-001
- gemini/gemini-1.5-flash-002
- gemini/gemini-1.5-flash-8b-exp-0827
- gemini/gemini-1.5-flash-8b-exp-0924
- gemini/gemini-1.5-flash-latest
- gemini/gemini-1.5-flash
- gemini/gemini-1.5-pro-001
- gemini/gemini-1.5-pro-002
- gemini/gemini-1.5-pro-latest
- gemini/gemini-1.5-pro
Groq
- groq/deepseek-r1-distill-llama-70b
- groq/llama-3.3-70b-versatile
- groq/llama-3.3-70b-specdec
- groq/llama-3.2-1b-preview
- groq/llama-3.2-3b-preview
- groq/llama-3.2-11b-vision-preview
- groq/llama-3.2-90b-vision-preview
- groq/llama-3.1-8b-instant
- groq/llama3-70b-8192
- groq/llama3-8b-8192
- groq/gemma2-9b-it
OpenAI
- gpt-4.1-mini-2025-04-14
- gpt-4.1-mini
- gpt-4.1-2025-04-14
- gpt-4.1
- gpt-4.1-nano-2025-04-14
- gpt-4.1-nano
- o4-mini-2025-04-16
- o4-mini
- gpt-4.5-preview-2025-02-27
- gpt-4.5-preview
- o3-2025-04-16
- o3
- o3-mini-2025-01-31
- o3-mini
- gpt-4o-mini
- gpt-4o-2024-05-13
- gpt-4o-2024-08-06
- gpt-4o-mini-2024-07-18
- gpt-4o
- gpt-4o-2024-11-20
- o1-mini-2024-09-12
- o1-mini
- o1-preview-2024-09-12
- o1-preview
- o1-2024-12-17
- gpt-4-1106-preview
- gpt-4-32k-0314
- gpt-4-turbo-2024-04-09
- gpt-4-turbo-preview
- gpt-4-turbo
- gpt-4
- gpt-3.5-turbo-0125
- gpt-3.5-turbo-1106
X.AI
- xai/grok-3-beta
- xai/grok-3-fast-beta
- xai/grok-3-fast-latest
- xai/grok-3-mini-beta
- xai/grok-3-mini-fast-beta
- xai/grok-3-mini-fast-latest
- xai/grok-beta
- xai/grok-2-1212
- xai/grok-2
- xai/grok-2-latest
Deepseek
- deepseek/deepseek-reasoner
- deepseek/deepseek-chat
設定のカスタマイズ
LLM パラメータの調整
選択したモデルに対して、異なるパラメータ値で実験することができます。パラメータを調整するには、以下の手順に従ってください。- Playground UI の右上にある Chat settings をクリックして、パラメータ設定ドロップダウンを開きます。
- ドロップダウンで、必要に応じてパラメータを調整します。Weave の Call 追跡のオン/オフを切り替えたり、関数の追加 を行うこともできます。
- Chat settings を再度クリックしてドロップダウンを閉じ、変更を保存します。
関数の追加
ユーザーからの入力に基づいて、異なるモデルがどのように関数を使用するかをテストできます。Playground でテスト用に関数を追加するには、以下の手順に従ってください。- Playground UI の右上にある Chat settings をクリックして、パラメータ設定ドロップダウンを開きます。
- ドロップダウン内の + Add function をクリックします。
- ポップアップで、関数の情報を追加します。
- 変更を保存して関数のポップアップを閉じるには、右上の x をクリックします。
- Chat settings をクリックして設定ドロップダウンを閉じ、変更を保存します。
試行回数の調整
Playground では、試行回数(Number of trials)を設定することで、同じ入力に対して複数の出力を生成できます。デフォルト設定は1 です。試行回数を調整するには、以下の手順に従ってください。
- Playground UI で、設定サイドバーが開いていない場合は開きます。
- Number of trials を調整します。
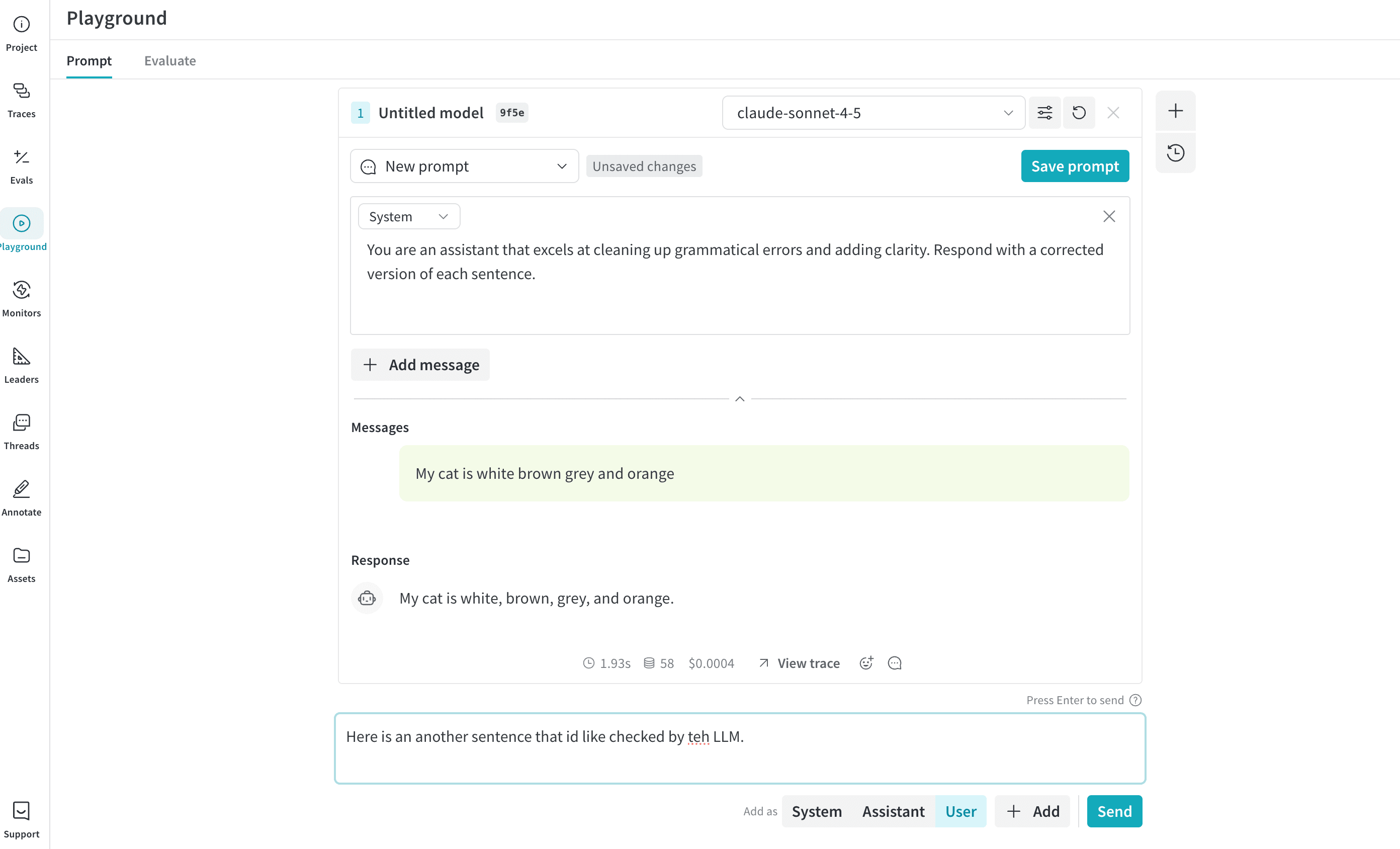
メッセージコントロール
メッセージの再試行、編集、削除
Playground では、メッセージの再試行、編集、削除が可能です。この機能を使用するには、編集、再試行、または削除したいメッセージの上にカーソルを置きます。Delete、Edit、Retry の 3 つのボタンが表示されます。- Delete: チャットからメッセージを削除します。
- Edit: メッセージの内容を修正します。
- Retry: それ以降のすべてのメッセージを削除し、選択したメッセージからチャットを再試行します。
新しいメッセージの追加
チャットに新しいメッセージを追加するには、以下の手順に従ってください。- チャットボックスで、利用可能なロール(Assistant または User)のいずれかを選択します。
- + Add をクリックします。
- LLM に新しいメッセージを送信するには、Send ボタンをクリックします。または、Command と Enter キーを同時に押します。
LLM の比較
Playground では LLM を比較できます。比較を行うには、以下の手順に従ってください。- Playground UI で Compare をクリックします。元のチャットの隣に 2 つ目のチャットが開きます。
- 2 つ目のチャットでは、以下が可能です。
- メッセージボックスに、両方のモデルでテストしたいメッセージを入力し、Send を押します。
カスタムプロバイダー
カスタムプロバイダーの追加
サポートされているプロバイダー に加えて、Playground を使用してカスタムモデル用の OpenAI 互換 API エンドポイントをテストできます。例としては以下があります。- サポートされているモデルプロバイダーの旧バージョン
- ローカルモデル
- Playground UI の左上にある Select a model ドロップダウンをクリックします。
- + Add AI provider を選択します。
-
ポップアップモーダルで、プロバイダー情報を入力します。
- Provider name: 例:
openaiやollama。 - API key: 例: OpenAI の APIキー。
- Base URL: 例:
https://api.openai.com/v1/や ngrok の URLhttps://e452-2600-1700-45f0-3e10-2d3f-796b-d6f2-8ba7.ngrok-free.app。 - Headers (任意): 複数のヘッダーのキーと値を追加できます。
- Models: 1 つのプロバイダーに対して複数のモデルを追加できます。例:
deepseek-r1やqwq。 - Max tokens (任意): 各モデルについて、応答で生成できる最大トークン数を指定できます。
- Provider name: 例:
- プロバイダー情報を入力したら、Add provider をクリックします。
- Playground UI の左上にある Select a model ドロップダウンから、新しいプロバイダーと利用可能なモデルを選択します。
カスタムプロバイダーの編集
以前に作成したカスタムプロバイダー の情報を編集するには、以下の手順に従ってください。- Weave サイドバーで Overview に移動します。
- 上部ナビゲーションメニューから AI Providers を選択します。
- Custom providers テーブルで、更新したいカスタムプロバイダーを見つけます。
- そのエントリの Last Updated 列にある編集ボタン(鉛筆アイコン)をクリックします。
- ポップアップモーダルで、プロバイダー情報を編集します。
- Save をクリックします。
カスタムプロバイダーの削除
以前に作成したカスタムプロバイダー を削除するには、以下の手順に従ってください。- Weave サイドバーで Overview に移動します。
- 上部ナビゲーションメニューから AI Providers を選択します。
- Custom providers テーブルで、削除したいカスタムプロバイダーを見つけます。
- そのエントリの Last Updated 列にある削除ボタン(ゴミ箱アイコン)をクリックします。
- ポップアップモーダルで、プロバイダーを削除することを確認します。この操作は取り消せません。
- Delete をクリックします。
Ollama で ngrok を使用する
Playground でローカルに実行されている Ollama モデルをテストするには、ngrok を使用して CORS 制限を回避する一時的な公開 URL を作成します。 設定するには、以下の手順に従ってください。- お使いの OS に合わせて ngrok をインストール します。
-
Ollama モデルを起動します。
-
別のターミナルで、必要な CORS ヘッダーを指定して ngrok トンネルを作成します。
https://xxxx-xxxx.ngrok-free.app のような公開 URL が表示されます。Playground で Ollama をカスタムプロバイダーとして追加する際に、この URL を Base URL として使用してください。
次の図は、ローカル環境、ngrok プロキシ、および W&B クラウドサービス間のデータフローを示しています。
保存済みモデル
モデルの保存
ワークフローに合わせて再利用可能なモデルプリセットを作成および設定できます。モデルを保存すると、好みの設定、パラメータ、および関数フックを適用した状態で素早くロードできます。- LLM ドロップダウンから、プロバイダーを選択します。
- プロバイダーリストから、モデルを選択します。
- Playground UI の右上にある Chat settings をクリックして、チャット設定ウィンドウを開きます。
- チャット設定ウィンドウで以下を行います。
- Model Name フィールドに、保存するモデルの名前を入力します。
- 必要に応じてパラメータを調整します。Weave の Call 追跡のオン/オフを切り替えたり、関数の追加 を行うこともできます。
- Publish Model をクリックします。モデルが保存され、LLM ドロップダウンの Saved Models からアクセスできるようになります。これで保存済みモデルを 使用 および 更新 できるようになります。
保存済みモデルの使用
以前に 保存したモデル に素早く切り替えて、実験やセッション間の一貫性を維持します。これにより、中断したところからすぐに再開できます。- LLM ドロップダウンから Saved Models を選択します。
- 保存済みモデルのリストから、ロードしたいモデルをクリックします。モデルがロードされ、Playground で使用できる状態になります。
保存済みモデルの更新
既存の 保存済みモデル を編集して、パラメータを微調整したり設定を更新したりします。これにより、ユースケースの進化に合わせて保存済みモデルを対応させることができます。- LLM ドロップダウンから Saved Models を選択します。
- 保存済みモデルのリストから、更新したいモデルをクリックします。
- Playground UI の右上にある Chat settings をクリックして、チャット設定ウィンドウを開きます。
- チャット設定ウィンドウで、必要に応じてパラメータを調整します。Weave の Call 追跡のオン/オフを切り替えたり、関数の追加 を行うこともできます。
- Update model をクリックします。モデルが更新され、LLM ドロップダウンの Saved Models からアクセスできるようになります。