Evaluation Playground
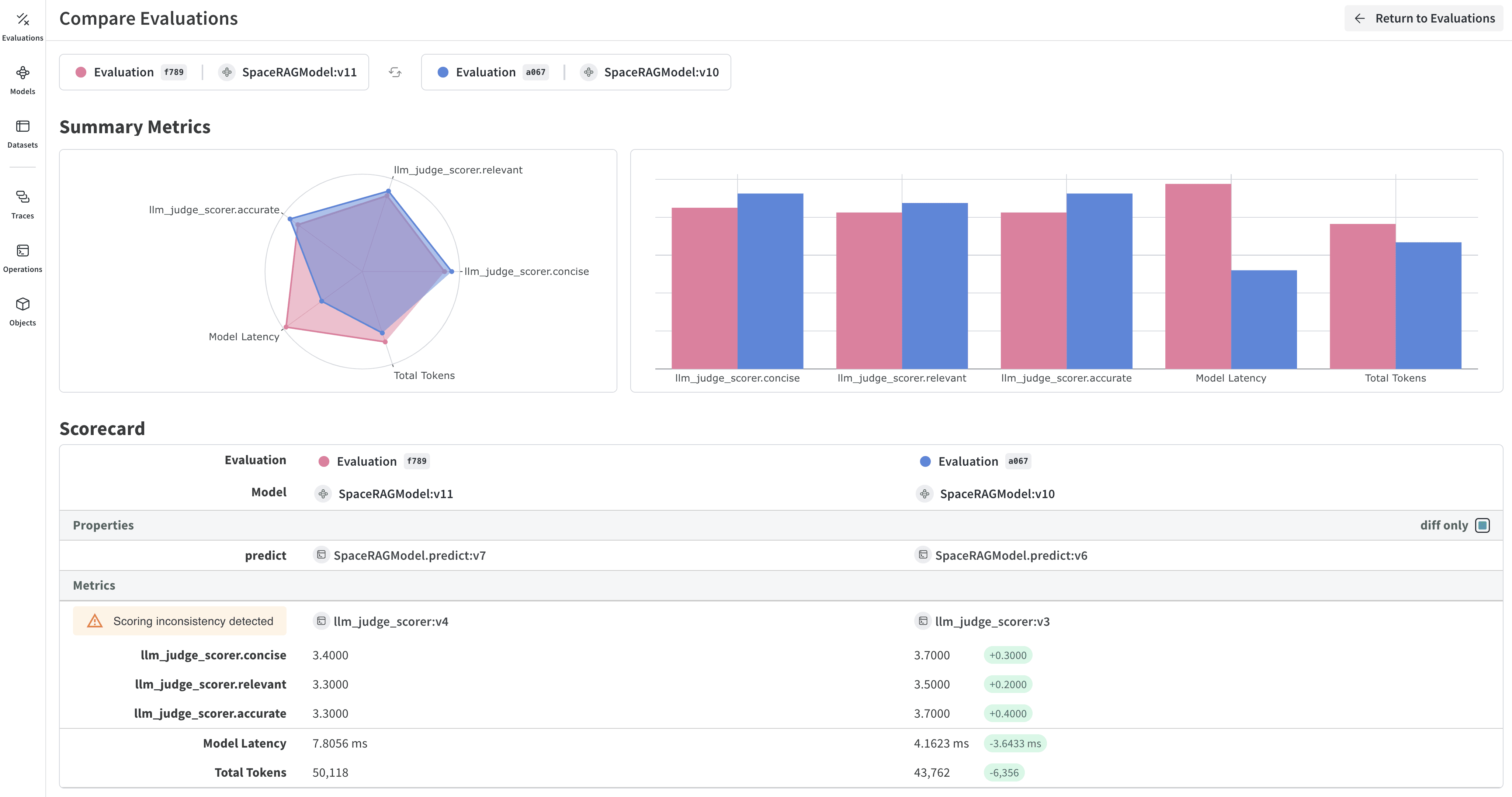
Evaluation Playground を使用すると、既存の Models にアクセスし、Evaluation Datasets や LLM スコアリングジャッジを使用してそのパフォーマンスを比較できます。これにより、コードを記述することなく、モデルの実験や比較を開始できます。また、プレイグラウンドで開発した Models、スコアラー、Datasets を保存して、後の開発やデプロイメントに活用することも可能です。 例えば、Evaluation Playground を開き、以前に保存した 2 つの Models を追加して、新規または保存済みの質疑応答形式の Evaluation Dataset に基づいてパフォーマンスを評価できます。次に、インターフェース上で新しいモデルを追加し、システムプロンプトを設定して、3 つのモデルすべてに対して新しい評価を実行し、それぞれのパフォーマンスを比較することができます。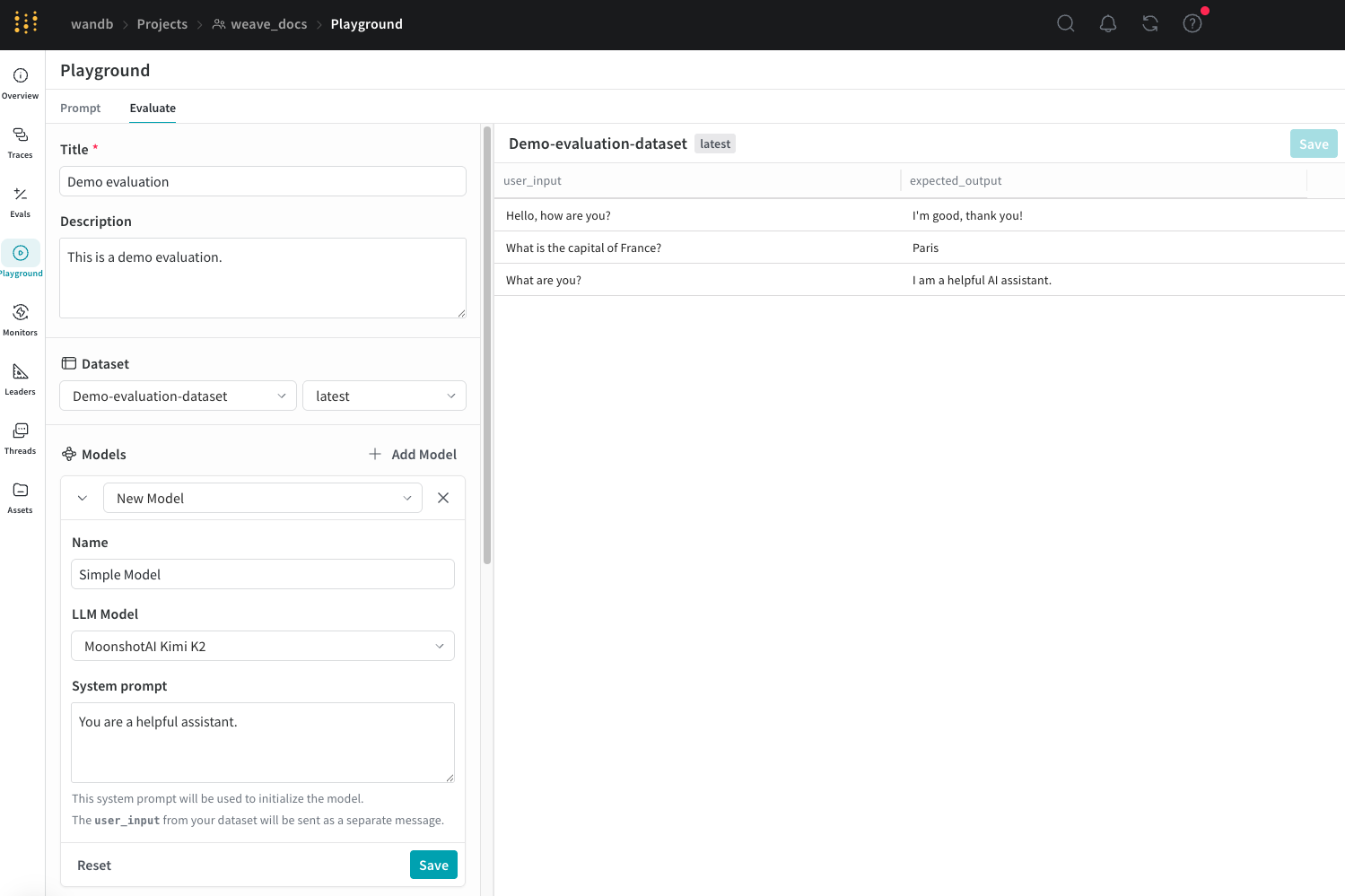
プレイグラウンドで評価を設定する
Evaluation Playground で評価を設定するには、以下の手順に従います。- Weave UI を開き、評価を実行したい Project を開きます。これにより Traces ページが開きます。
- Traces ページで、左メニューの Playground アイコンをクリックし、Playground ページの Evaluate タブを選択します。Evaluate ページでは、以下のいずれかを選択できます。
- Load a demo example: 定義済みの設定を読み込みます。これは MoonshotAI Kimi K2 モデルを期待される出力に対して評価し、LLM ジャッジを使用してその正当性を判断するデモです。この設定を使用してインターフェースを試すことができます。
- Start from scratch: 構築のベースとなる空の設定を読み込みます。
- Start from scratch を選択した場合は、Title と Description フィールドに、評価の内容を示すタイトルと説明を追加します。
Dataset を追加する
Datasets は、ユーザー入力の例と、モデルからの期待される応答をまとめたコレクションです。評価中、プレイグラウンドは各テスト入力をモデルに供給し、その出力を収集して、正確性などの選択したメトリクスに基づいて出力をスコアリングします。UI でデータセットを作成するか、プロジェクトに保存済みの既存のデータセットを追加するか、新しいデータセットをアップロードするかを選択できます。 以下の形式のデータセットをアップロードできます。.csv.tsv.json.jsonl
- ドロップダウンメニューをクリックし、以下のいずれかを選択します。
- UI で新しいデータセットを作成するには Start from scratch。
- ローカルマシンからデータセットをアップロードするには Upload a file。
- プロジェクトに保存済みの既存のデータセット。
- 任意: Save をクリックして、後で使用するためにデータセットをプロジェクトに保存します。
UI を使用して編集できるのは、新しいデータセットのみです。また、スコアラーがデータにアクセスできるように、データセットの列に
user_input および expected_output と適切に名前を付けることが重要です。Model を追加する
Weave における Models は、AI モデル(GPT など)と、評価中にモデルがどのように動作するかを定義する環境(この場合はシステムプロンプト)の組み合わせです。プロジェクト内の既存のモデルを選択するか、評価用に新しいモデルを作成できます。また、複数のモデルを一度に追加して、同じデータセットとスコアラーで同時に評価することも可能です。プレイグラウンド機能を使用して作成されたモデルのみを使用できます。 Evaluation Playground の Models セクションでモデルを追加するには:- Add Model をクリックし、ドロップダウンメニューから New Model または既存のモデルを選択します。
-
New Model を選択した場合は、以下のフィールドを設定します。
- Name: 新しいモデルに分かりやすい名前を付けます。
- LLM Model: 新しいモデルのベースとなる基盤モデル(OpenAI の GPT-4 など)を選択します。すでにアクセス設定済みの基盤モデルのリストから選択するか、Add AI provider を選択してモデルを選択し、基盤モデルへのアクセスを追加できます。プロバイダーを追加すると、そのプロバイダーへのアクセス資格情報の入力を求められます。APIキー、エンドポイント、および Weave を使用してモデルにアクセスするために必要な追加の設定情報の確認方法については、プロバイダーのドキュメントを参照してください。
- System Prompt: モデルの動作に関する指示を提供します。例えば、
You are a helpful assistant specializing in Python programming.などです。データセットからのuser_inputは後続のメッセージで送信されるため、システムプロンプトに含める必要はありません。
- 任意: Save をクリックして、後で使用するためにモデルをプロジェクトに保存します。
- 任意: Add Model を再度クリックして他のモデルを追加することで、複数のモデルを同時に評価できます。
スコアラーを追加する
Scorers は、LLM ジャッジを使用して AI モデルの出力の品質を測定および評価します。プロジェクト内の既存のスコアラーを選択するか、モデルを評価するための新しいスコアラーを作成できます。 Evaluation Playground でスコアラーを追加するには:-
Add Scorer をクリックし、以下のフィールドを設定します。
- Name: スコアラーに分かりやすい名前を付けます。
-
Type: スコアの出力方法を、Boolean(真偽値)または Number(数値)から選択します。Boolean スコアラーは、モデルの出力が設定した判定パラメータを満たしているかどうかに応じて、バイナリの
TrueまたはFalseを返します。Number スコアラーは0から1の間のスコアを出力し、モデルの出力が判定パラメータをどの程度満たしているかの一般的なグレードを提供します。 - LLM-as-a-judge-model: スコアラーのジャッジとして使用する基盤モデルを選択します。Models セクションの LLM Model フィールドと同様に、設定済みの基盤モデルから選択するか、新しくアクセスを設定できます。
-
Scoring Prompt: LLM ジャッジに、何を基準に出力をスコアリングすべきかのパラメータを提供します。例えば、ハルシネーションをチェックしたい場合は、次のようなスコアリングプロンプトを入力できます。
データセットのフィールドや応答を、
{user_input}、{expected_output}、{output}などの変数としてスコアリングプロンプトで使用できます。利用可能な変数のリストを表示するには、UI で Insert variable をクリックします。
- 任意: Save をクリックして、後で使用するためにスコアラーをプロジェクトに保存します。
評価を実行する
Datasets、Models、およびスコアラーの設定が完了したら、評価を実行できます。- Evaluation Playground で評価を実行するには、Run eval をクリックします。
評価結果を確認する
評価が完了すると、プレイグラウンドは、モデルへの各リクエストで収集されたさまざまなメトリクスを表示するレポートを開きます。