weave.init() を呼び出した後、ChatNVIDIA ライブラリを介して行われた LLM 呼び出しを自動的に追跡し、ログを記録します。
Tracing
開発中および Production (プロダクション) の両方において、LLM アプリケーションの Traces を中央データベースに保存することは重要です。これらの Traces はデバッグに使用したり、アプリケーションを改善しながら評価するための、トリッキーな例を含んだ Datasets を構築するのに役立ちます。- Python
- TypeScript
Weave は ChatNVIDIA python library の Traces を自動的にキャプチャできます。任意のプロジェクト名を指定して
weave.init(<project-name>) を呼び出すことで、キャプチャを開始します。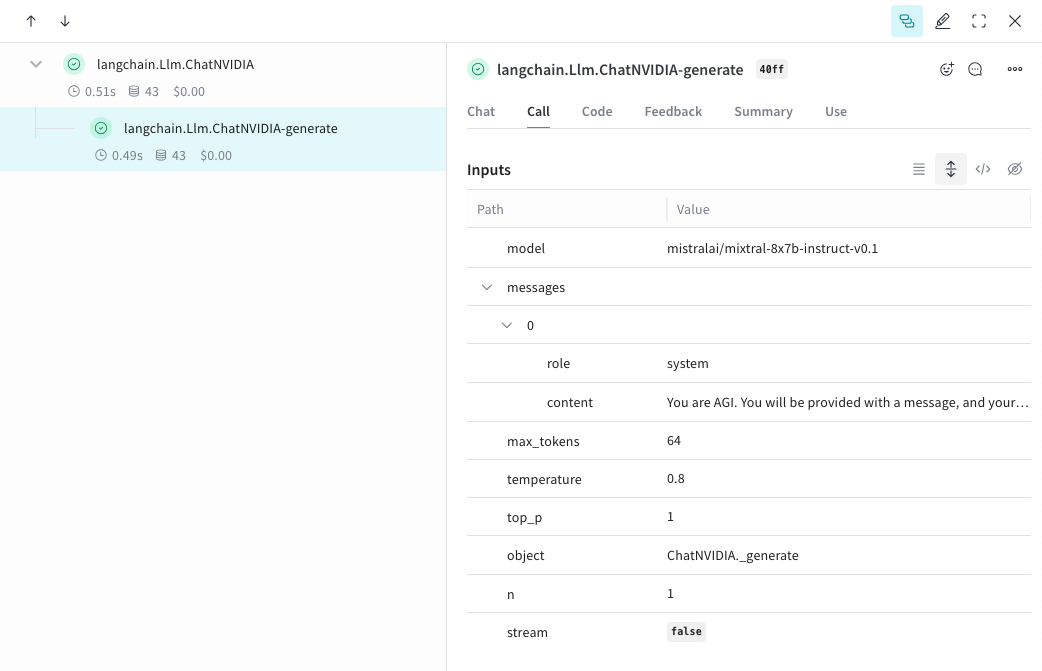
独自の ops を追跡する
- Python
- TypeScript
関数を Weave に移動し、UI で
@weave.op でラップすると、入力、出力、およびアプリケーションロジックのキャプチャが開始され、データがアプリ内をどのように流れるかをデバッグできるようになります。ops は深くネストさせることができ、追跡したい関数の ツリー を構築できます。これにより、実験中に git にコミットされていないアドホックな詳細をキャプチャするために、コード の バージョン管理 も自動的に開始されます。単に @weave.op デコレータを付けた関数を作成し、その中で ChatNVIDIA python library を呼び出すだけです。以下の例では、2つの関数を op でラップしています。これにより、RAG アプリにおける検索ステップのような中間ステップが、アプリの 振る舞い にどのように影響しているかを確認できます。get_pokemon_data をクリックすると、そのステップの入力と出力を確認できます。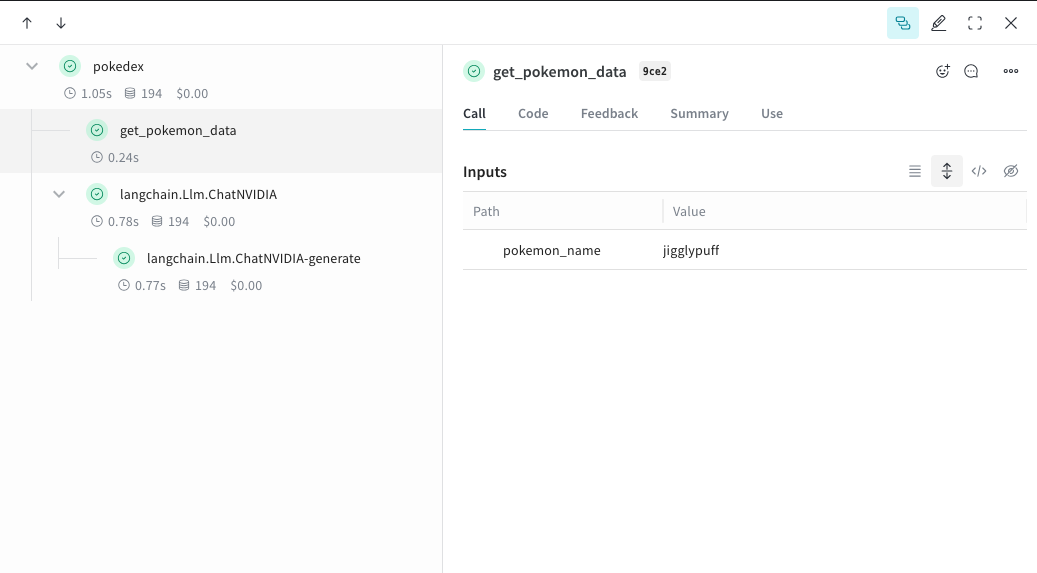
実験を容易にするための Model の作成
- Python
- TypeScript
多くの動的な要素がある場合、実験の整理は困難になります。
Model クラスを使用することで、システムプロンプトや使用している モデル など、アプリの実験的な詳細をキャプチャして整理できます。これにより、アプリの異なるイテレーションの整理や比較が容易になります。コード の バージョン管理 や入力/出力のキャプチャに加えて、Model はアプリケーションの 振る舞い を制御する構造化された パラメータ をキャプチャするため、どの パラメータ が最適だったかを簡単に見つけることができます。また、Weave Models は serve や Evaluations と併用することも可能です。以下の例では、model と system_message を使って実験できます。これらいずれかを変更するたびに、GrammarCorrectorModel の新しい バージョン が作成されます。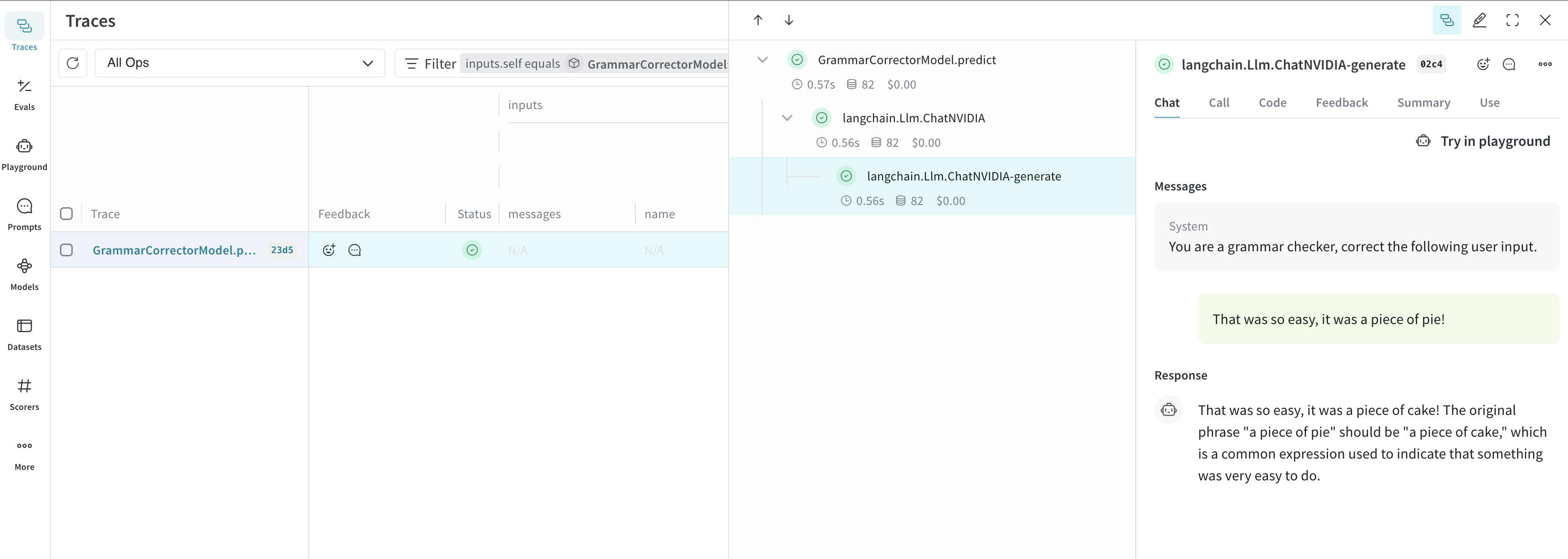
使用上の情報
ChatNVIDIA インテグレーションは、invoke、stream、およびそれらの非同期バリアントをサポートしています。また、ツールの使用もサポートしています。
ChatNVIDIA は多種多様な モデル で使用されることを想定しているため、関数呼び出し(function calling)のサポートは含まれていません。