事前準備
autotrain-advanced と wandb をインストールします。
- Command Line
- Notebook
pass@1 で SoTA(State-of-the-Art)の結果を出す手順を説明します。
データセットの準備
Hugging Face AutoTrain でカスタムの CSV データセット を適切に動作させるには、特定のフォーマットにする必要があります。-
トレーニングファイルには、トレーニングに使用する
textカラムが含まれている必要があります。最良の結果を得るには、textカラムのデータが### Human: Question?### Assistant: Answer.という形式に従っている必要があります。 優れた例としてtimdettmers/openassistant-guanacoを参考にしてください。 一方、 MetaMathQA dataset にはquery、response、typeというカラムが含まれています。まず、この データセット を前処理します。typeカラムを削除し、queryとresponseカラムの内容を組み合わせて、### Human: Query?### Assistant: Response.形式の新しいtextカラムを作成します。トレーニングには、この結果として得られた データセットrishiraj/guanaco-style-metamathを使用します。
autotrain を使用したトレーニング
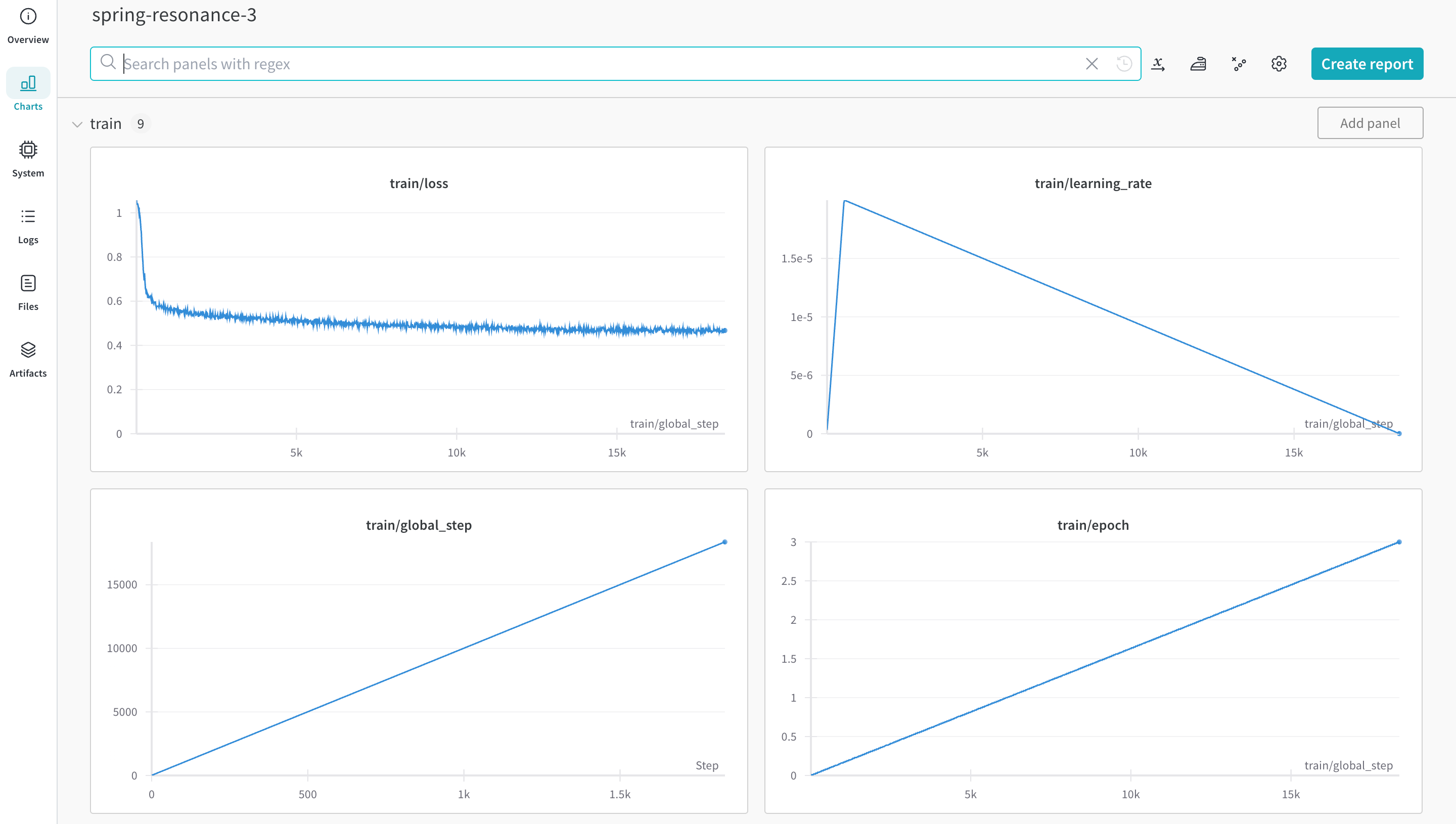
コマンドラインまたは ノートブック から autotrain advanced を使用してトレーニングを開始できます。 --log 引数 を使用するか、 --log wandb を使用して、結果を W&B Run に ログ 記録します。
- Command Line
- Notebook
その他のリソース
- AutoTrain Advanced now supports Experiment Tracking : Rishiraj Acharya 氏によるブログ。
- Hugging Face AutoTrain Docs : 公式ドキュメント。