Try in Colab
torchtune は、大規模言語モデル(LLM)の作成、ファインチューニング、および実験プロセスを効率化するために設計された PyTorch ベースのライブラリです。さらに、torchtune は W&B によるロギング を標準でサポートしており、トレーニングプロセスの追跡と可視化を強化できます。
torchtune を使用した Mistral 7B のファインチューニング に関する W&B ブログポストもあわせてご覧ください。
W&B ロギングをすぐに利用する
ローンンチ時にコマンドライン引数をオーバーライドします:# コマンドラインから W&B ロガーを指定して実行
tune run lora_finetune_single_device --config llama3/8B_lora_single_device \
metric_logger._component_=torchtune.utils.metric_logging.WandBLogger \
metric_logger.project="llama3_lora" \
log_every_n_steps=5
レシピの設定(config)で W&B ロギングを有効にします:# llama3/8B_lora_single_device.yaml 内
metric_logger:
_component_: torchtune.utils.metric_logging.WandBLogger
project: llama3_lora
log_every_n_steps: 5
W&B メトリクスロガーの使用
レシピの設定ファイルの metric_logger セクションを修正することで、W&B ロギングを有効にできます。 _component_ を torchtune.utils.metric_logging.WandBLogger クラスに変更します。また、 project 名や log_every_n_steps を渡して、ロギングの振る舞いをカスタマイズすることも可能です。
また、 wandb.init() メソッドと同様に、他の任意の kwargs を渡すことができます。例えば、チームで作業している場合は、 WandBLogger クラスに entity 引数を渡してチーム名を指定できます。
# llama3/8B_lora_single_device.yaml 内
metric_logger:
_component_: torchtune.utils.metric_logging.WandBLogger
project: llama3_lora
entity: my_project
job_type: lora_finetune_single_device
group: my_awesome_experiments
log_every_n_steps: 5
tune run lora_finetune_single_device --config llama3/8B_lora_single_device \
metric_logger._component_=torchtune.utils.metric_logging.WandBLogger \
metric_logger.project="llama3_lora" \
metric_logger.entity="my_project" \
metric_logger.job_type="lora_finetune_single_device" \
metric_logger.group="my_awesome_experiments" \
log_every_n_steps=5
何がログ記録されますか?
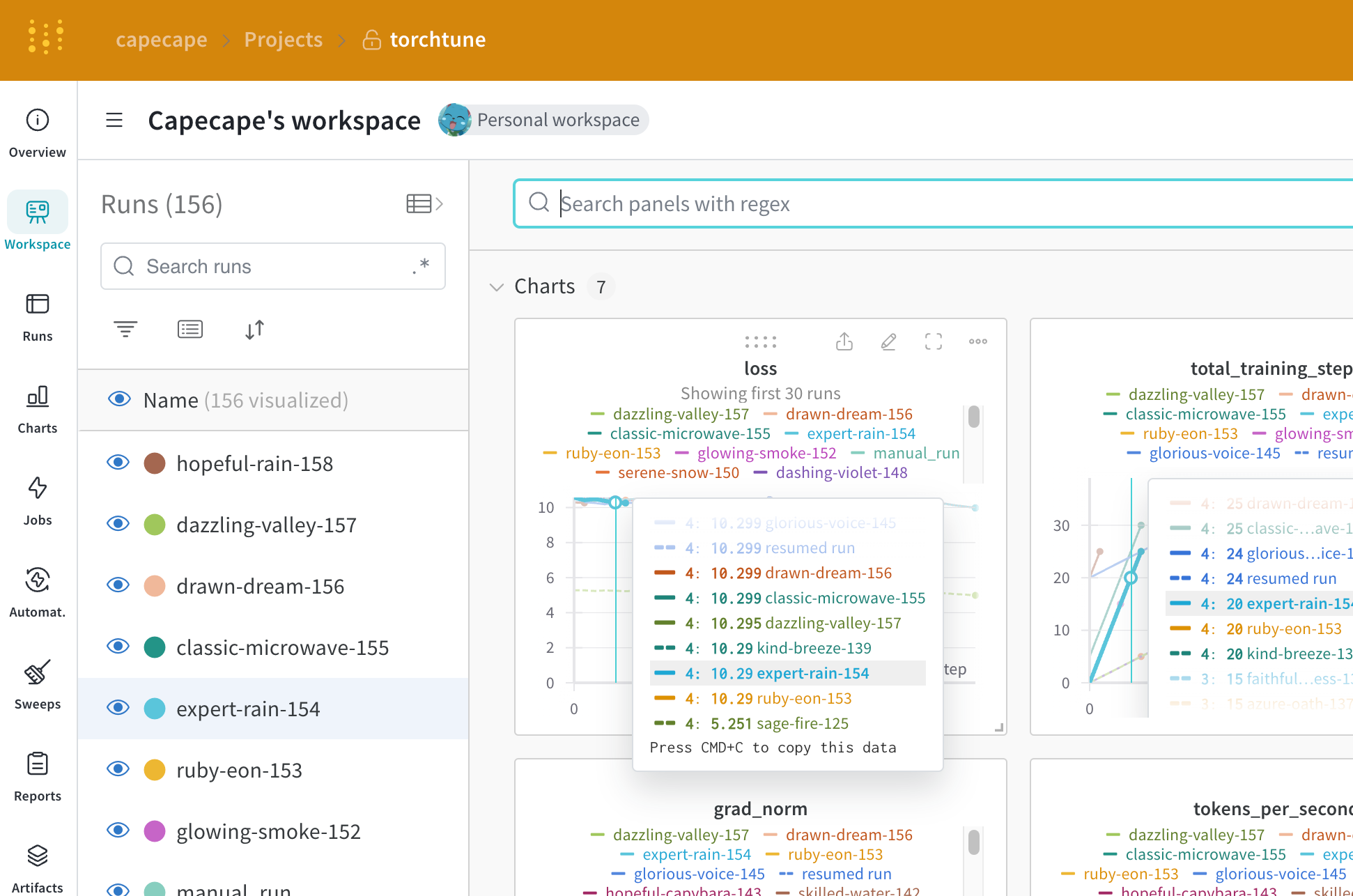
W&B ダッシュボードでログ記録されたメトリクスを確認できます。デフォルトでは、W&B は設定ファイルおよびローンンチ時のオーバーライドからのすべての ハイパーパラメーター をログ記録します。
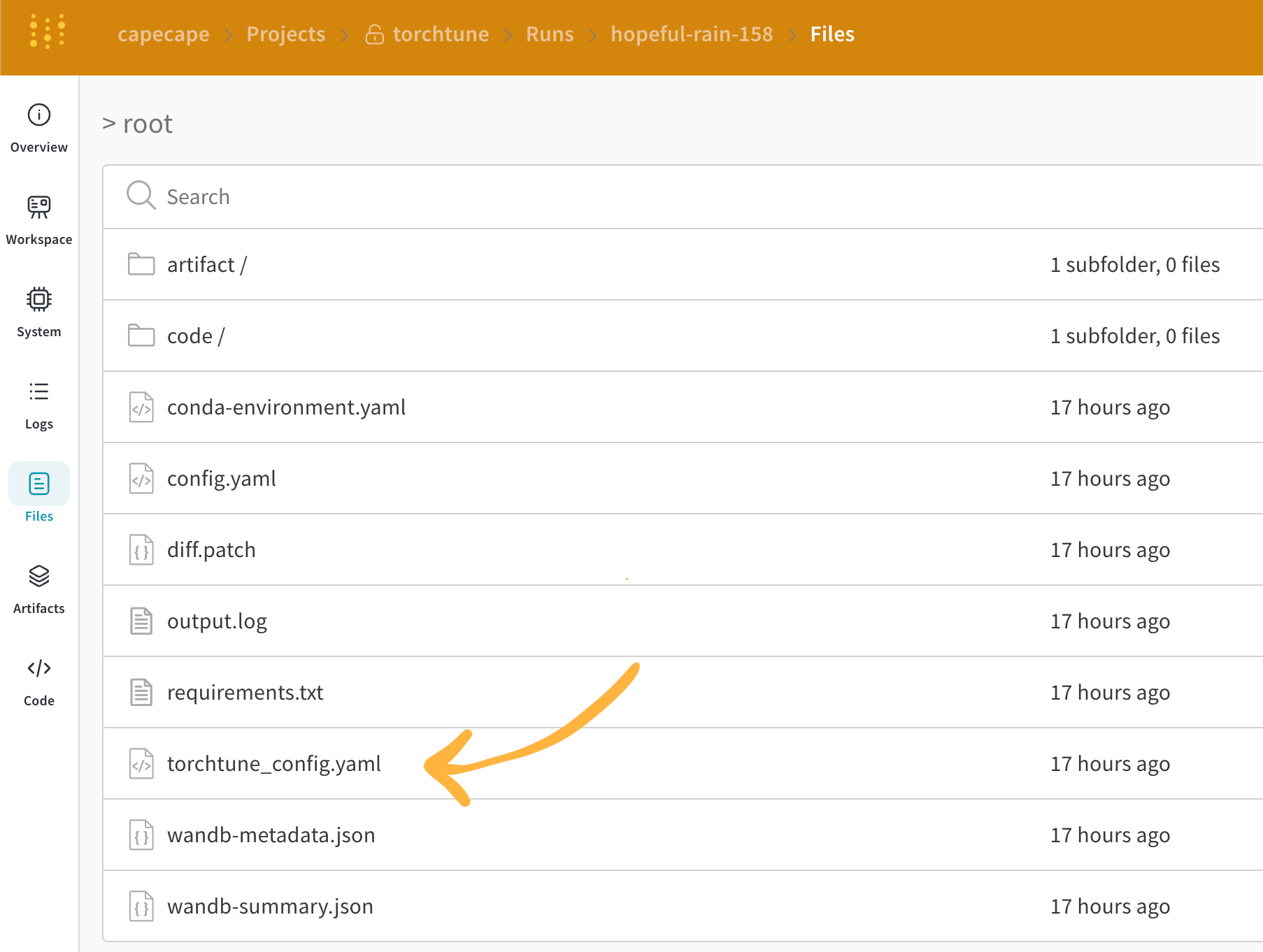
W&B は確定した設定を Overview タブにキャプチャします。また、W&B は Files タブ に YAML 形式で設定を保存します。
ログ記録されるメトリクス
各レシピには独自のトレーニングループがあります。ログ記録されるメトリクスについては各レシピを確認してください。デフォルトでは以下の項目が含まれます:
| メトリクス | 説明 |
|---|
loss | モデルの損失(loss) |
lr | 学習率(learning rate) |
tokens_per_second | モデルの秒間トークン数 |
grad_norm | モデルの勾配ノルム |
global_step | トレーニングループ内の現在のステップに対応。勾配蓄積(gradient accumulation)を考慮します。基本的には、オプティマイザーステップが実行されるたびにモデルが更新され、 gradient_accumulation_steps ごとに勾配が蓄積されてモデルが更新されます。 |
global_step はトレーニングステップ数と同じではありません。これはトレーニングループ内の現在のステップに対応します。勾配蓄積を考慮し、基本的にはオプティマイザーステップが実行されるたびに global_step が 1 増加します。例えば、データローダーに 10 バッチあり、勾配蓄積ステップが 2 で 3 エポック実行する場合、オプティマイザーは 15 回ステップを実行するため、この場合 global_step は 1 から 15 の範囲になります。
current_epoch を全エポック数に対するパーセンテージとしてログ記録するように計算できます:
# レシピファイル内の `train.py` 関数内
self._metric_logger.log_dict(
{"current_epoch": self.epochs * self.global_step / self._steps_per_epoch},
step=self.global_step,
)
このライブラリは急速に進化しているため、現在のメトリクスは変更される可能性があります。カスタムメトリクスを追加したい場合は、レシピを修正して対応する self._metric_logger.* 関数を呼び出してください。
チェックポイントの保存とロード
torchtune ライブラリは、さまざまな チェックポイント形式 をサポートしています。使用しているモデルのオリジンに応じて、適切な checkpointer クラス に切り替える必要があります。
モデルのチェックポイントを W&B Artifacts に保存したい場合、最も簡単な解決策は、対応するレシピ内の save_checkpoint 関数をオーバーライドすることです。
以下は、モデルのチェックポイントを W&B Artifacts に保存するために save_checkpoint 関数をオーバーライドする方法の例です。
def save_checkpoint(self, epoch: int) -> None:
...
## チェックポイントを W&B に保存します
## Checkpointer クラスによってファイル名が異なります
## ここでは full_finetune の場合の例を示します
checkpoint_file = Path.joinpath(
self._checkpointer._output_dir, f"torchtune_model_{epoch}"
).with_suffix(".pt")
# Artifact を作成
wandb_artifact = wandb.Artifact(
name=f"torchtune_model_{epoch}",
type="model",
# モデルチェックポイントの説明
description="Model checkpoint",
# 任意のメタデータを辞書形式で追加できます
metadata={
utils.SEED_KEY: self.seed,
utils.EPOCHS_KEY: self.epochs_run,
utils.TOTAL_EPOCHS_KEY: self.total_epochs,
utils.MAX_STEPS_KEY: self.max_steps_per_epoch,
},
)
# ファイルを追加してログ記録
wandb_artifact.add_file(checkpoint_file)
wandb.log_artifact(wandb_artifact)