はじめに
サインアップして APIキー を作成する
APIキー は、使用しているマシンを W&B に対して認証します。ユーザープロファイルから APIキー を生成できます。For a more streamlined approach, create an API key by going directly to User Settings. Copy the newly created API key immediately and save it in a secure location such as a password manager.
- 右上隅にあるユーザープロファイルアイコンをクリックします。
- User Settings を選択し、API Keys セクションまでスクロールします。
wandb ライブラリのインストールとログイン
ローカルに wandb ライブラリをインストールしてログインするには:
- Command Line
- Python
- Python notebook
-
WANDB_API_KEY環境変数 に APIキー を設定します。 -
wandbライブラリをインストールしてログインします。
メトリクス の ログ 記録
プロットの作成
ステップ 1: wandb のインポートと新しい Run の初期化
ステップ 2: プロットの可視化
個別のプロット
モデル の トレーニング と 予測 の完了後、wandb でプロットを生成して 予測 を分析できます。サポートされているチャートの全リストについては、以下の サポートされているプロット セクションを参照してください。すべてのプロット
W&B には、関連する複数のプロットを一度に描画するplot_classifier などの関数があります。
既存の Matplotlib プロット
Matplotlib で作成されたプロットも W&B ダッシュボード に ログ 記録できます。そのためには、まずplotly をインストールする必要があります。
サポートされているプロット
学習曲線 (Learning curve)
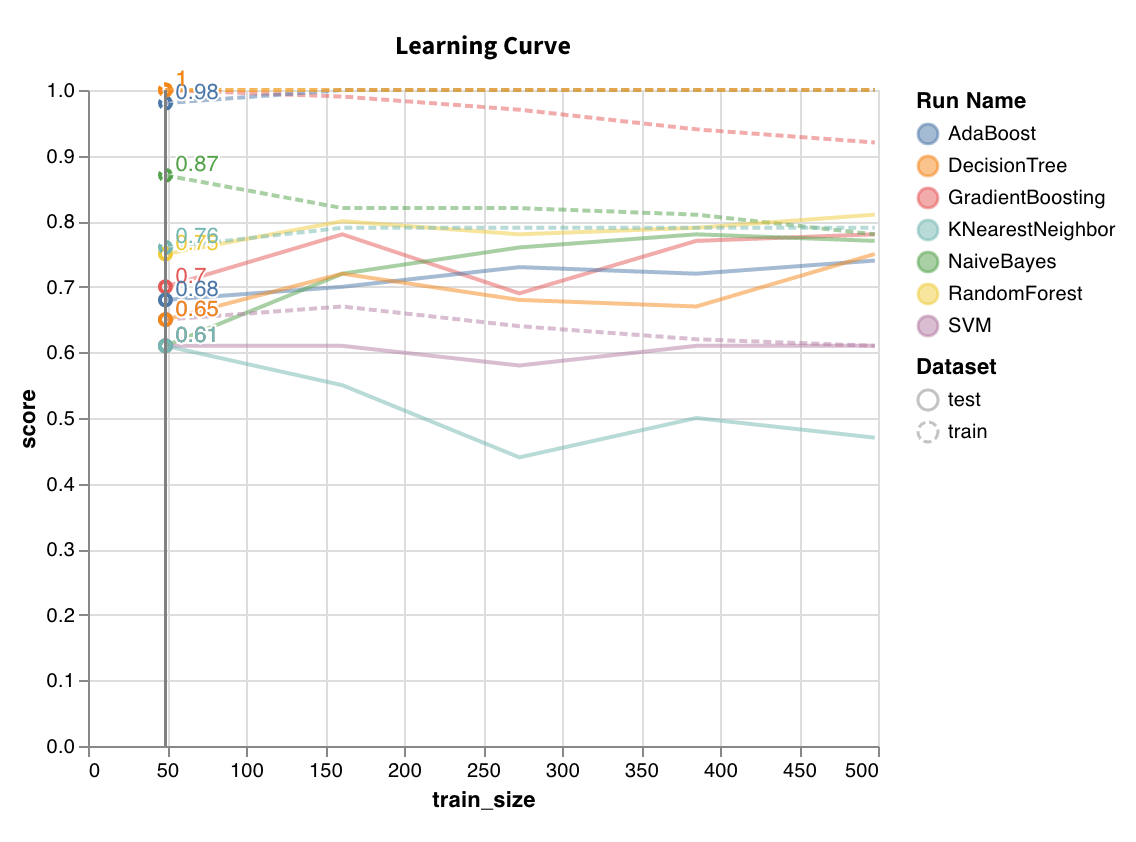
wandb.sklearn.plot_learning_curve(model, X, y)
- model (clf または reg): フィット済みの回帰器または分類器を指定します。
- X (arr): データセット の特徴量。
- y (arr): データセット のラベル。
ROC
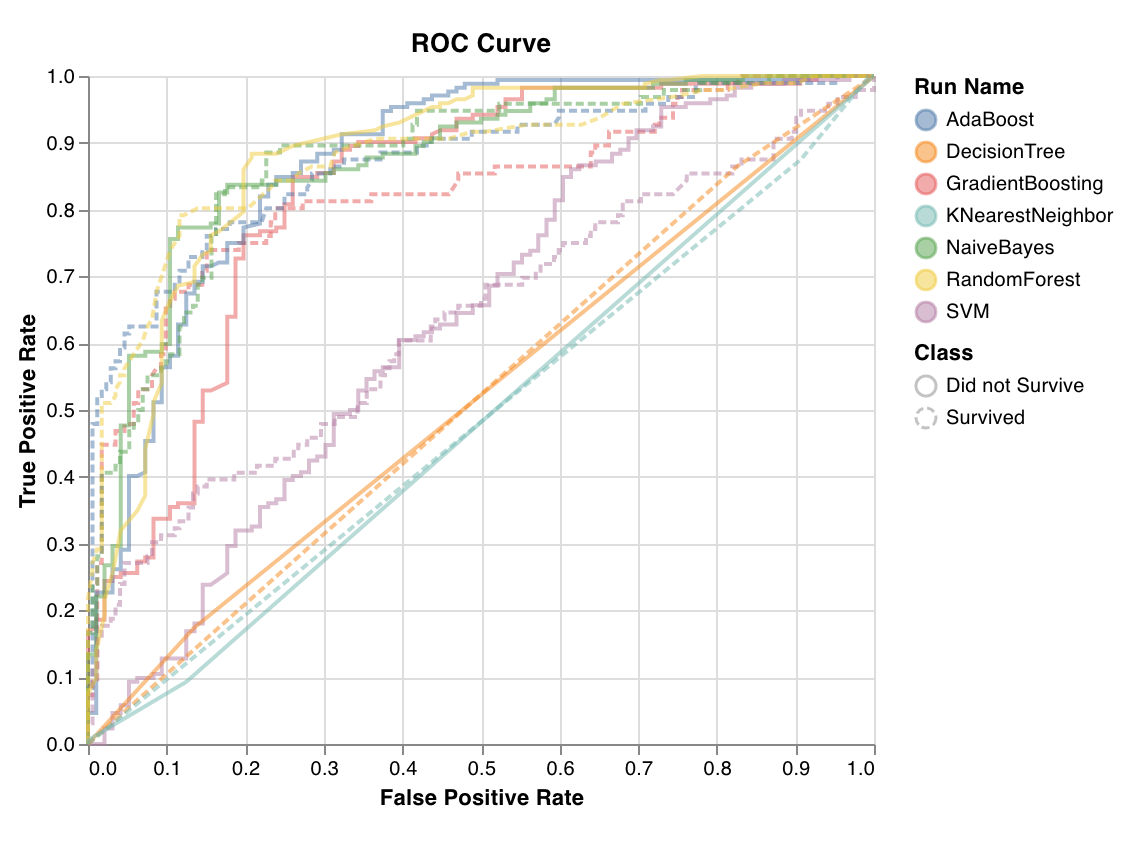
wandb.sklearn.plot_roc(y_true, y_probas, labels)
- y_true (arr): テストセット のラベル。
- y_probas (arr): テストセット の 予測 確率。
- labels (list): ターゲット変数 (y) の名前付きラベル。
クラス比率 (Class proportions)
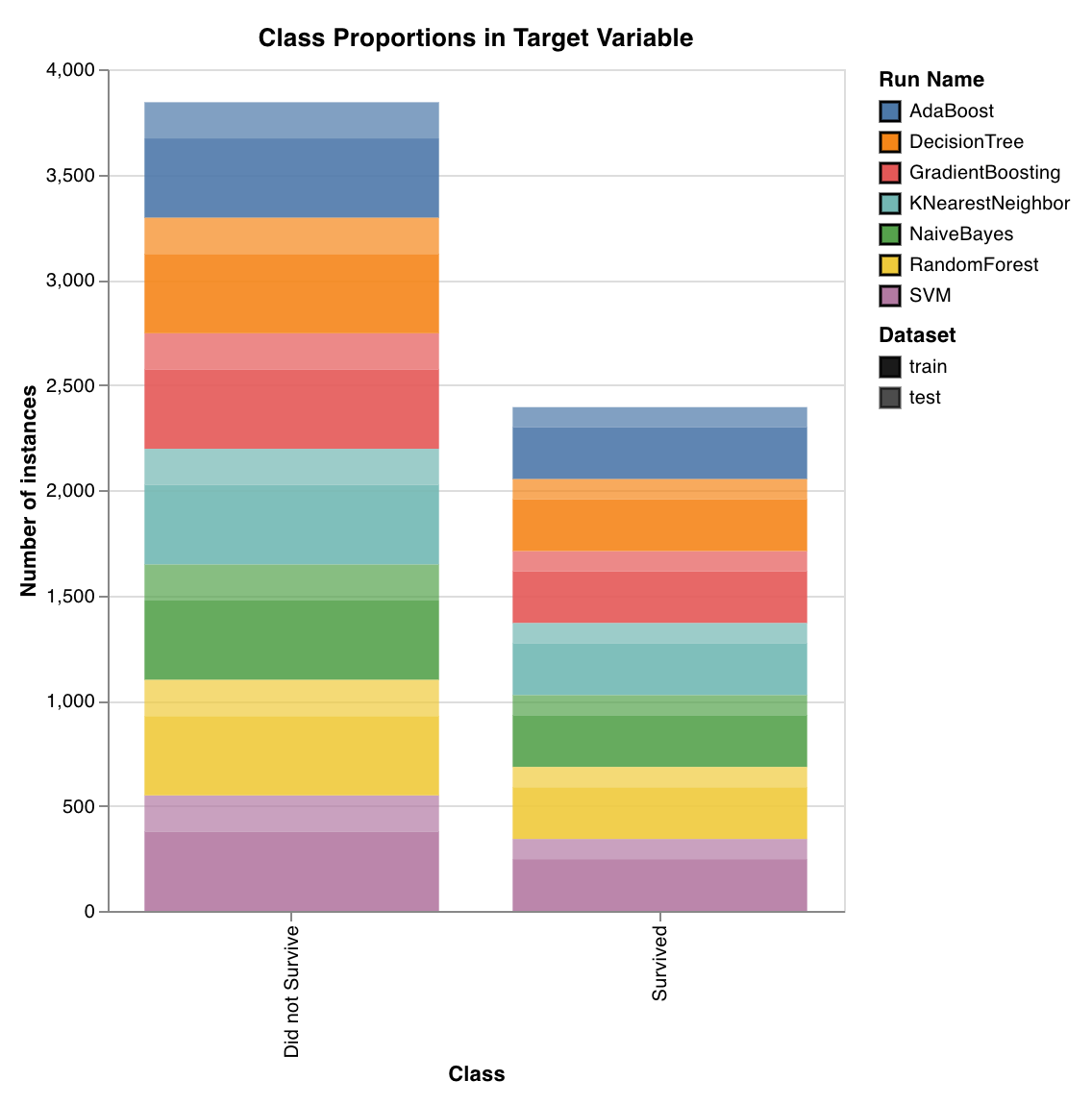
wandb.sklearn.plot_class_proportions(y_train, y_test, ['dog', 'cat', 'owl'])
- y_train (arr): トレーニングセット のラベル。
- y_test (arr): テストセット のラベル。
- labels (list): ターゲット変数 (y) の名前付きラベル。
PR曲線 (Precision recall curve)
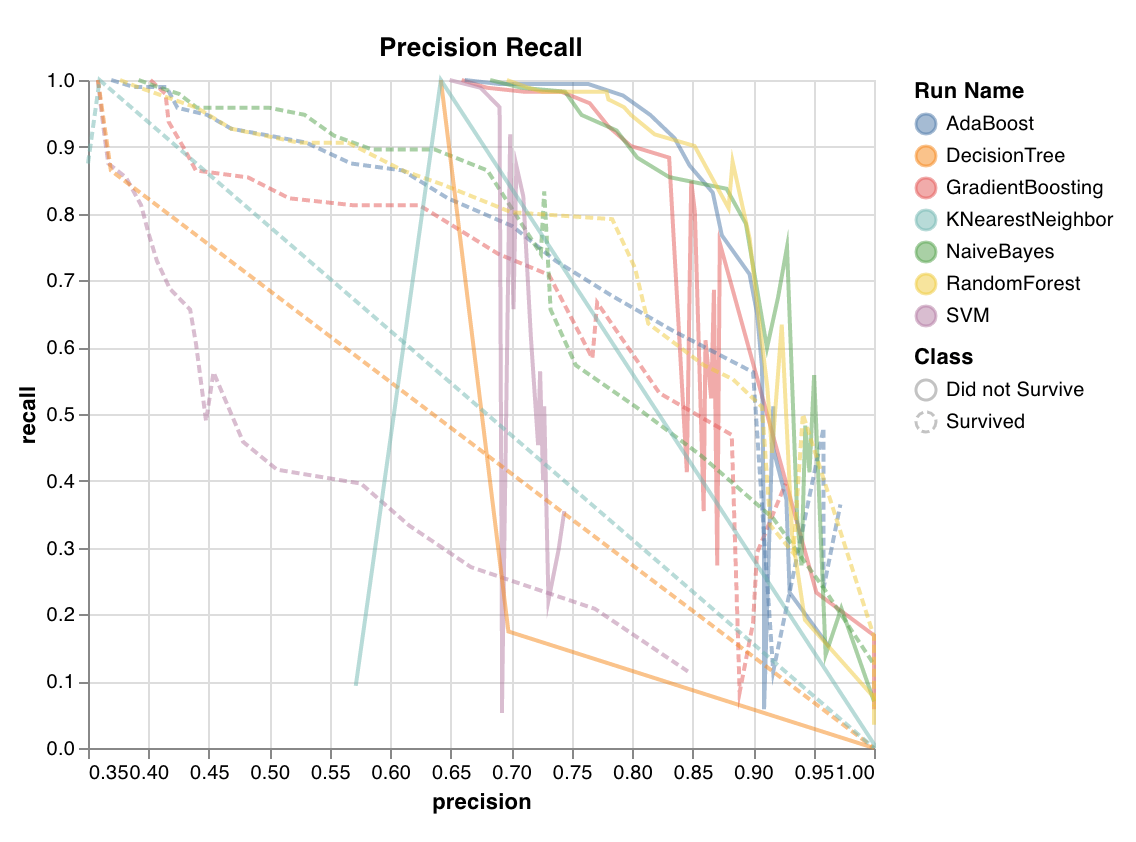
wandb.sklearn.plot_precision_recall(y_true, y_probas, labels)
- y_true (arr): テストセット のラベル。
- y_probas (arr): テストセット の 予測 確率。
- labels (list): ターゲット変数 (y) の名前付きラベル。
特徴量重要度 (Feature importances)
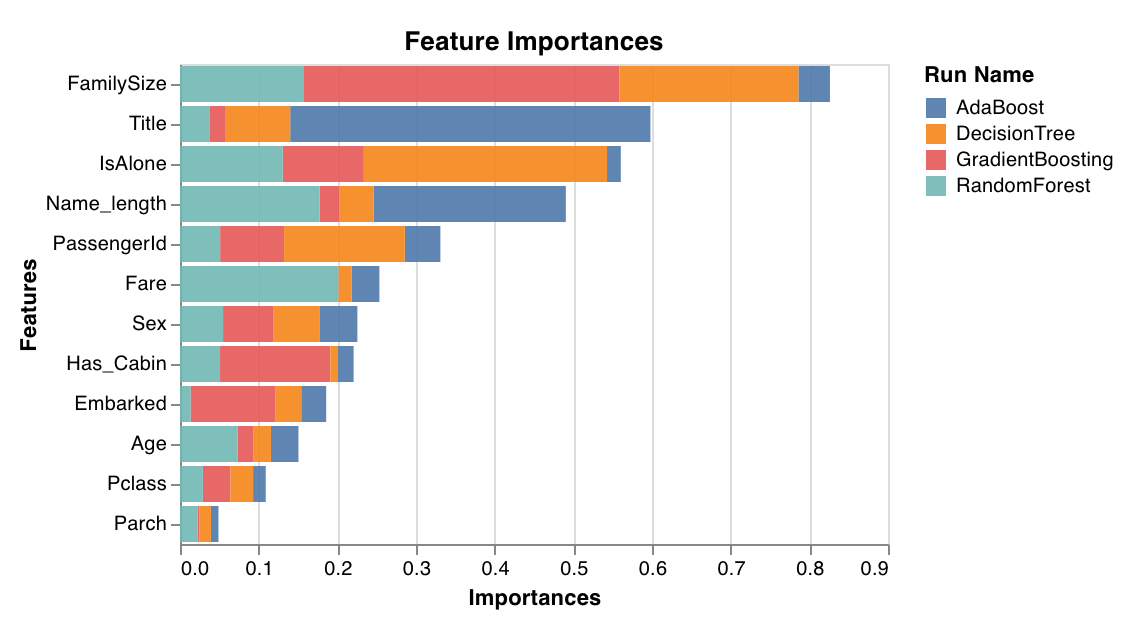
feature_importances_ 属性を持つ分類器でのみ機能します。
wandb.sklearn.plot_feature_importances(model, ['width', 'height, 'length'])
- model (clf): フィット済みの分類器を指定します。
- feature_names (list): 特徴量の名前。特徴量のインデックスを対応する名前に置き換えることで、プロットを読みやすくします。
検証曲線 (Calibration curve)
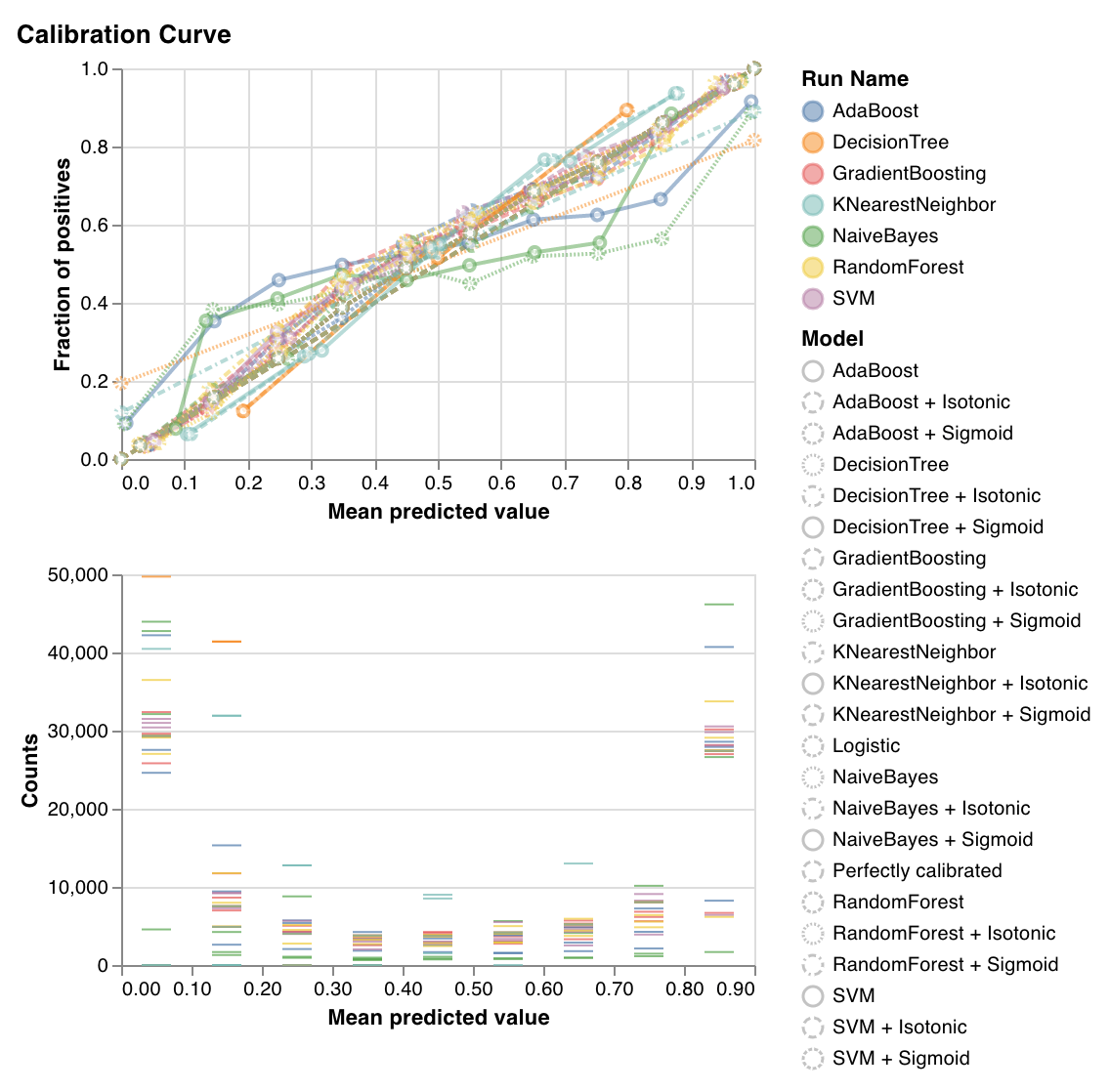
wandb.sklearn.plot_calibration_curve(clf, X, y, 'RandomForestClassifier')
- model (clf): フィット済みの分類器を指定します。
- X (arr): トレーニングセット の特徴量。
- y (arr): トレーニングセット のラベル。
- model_name (str): モデル 名。デフォルトは ‘Classifier’ です。
混同行列 (Confusion matrix)
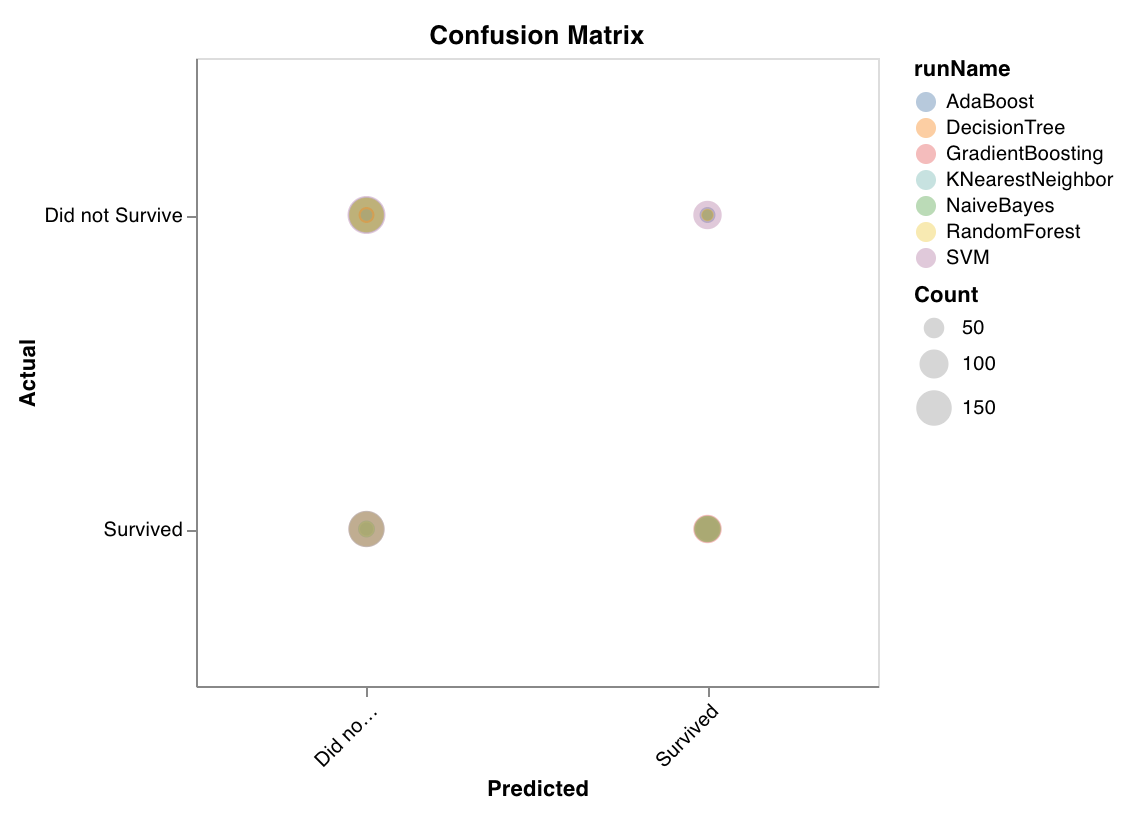
wandb.sklearn.plot_confusion_matrix(y_true, y_pred, labels)
- y_true (arr): テストセット のラベル。
- y_pred (arr): テストセット の 予測 ラベル。
- labels (list): ターゲット変数 (y) の名前付きラベル。
サマリーメトリクス (Summary metrics)
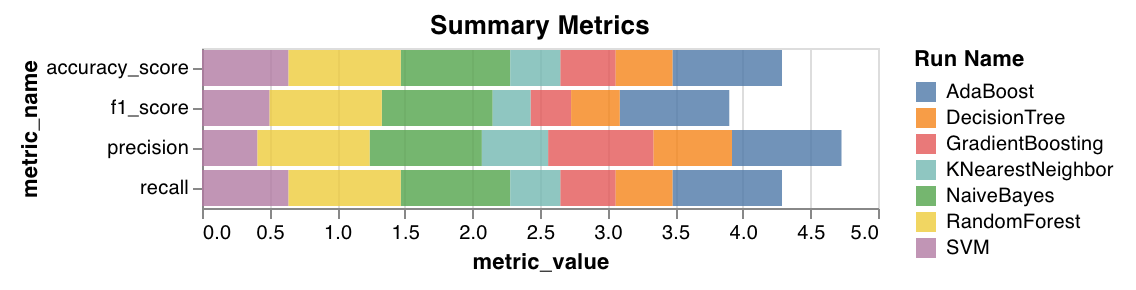
- 分類については、
mse、mae、r2スコアなどのサマリー メトリクス を計算します。 - 回帰については、
f1、正確度 (accuracy)、精度 (precision)、再現率 (recall) などのサマリー メトリクス を計算します。
wandb.sklearn.plot_summary_metrics(model, X_train, y_train, X_test, y_test)
- model (clf または reg): フィット済みの回帰器または分類器を指定します。
- X (arr): トレーニングセット の特徴量。
- y (arr): トレーニングセット のラベル。
- X_test (arr): テストセット の特徴量。
- y_test (arr): テストセット のラベル。
エルボー図 (Elbow plot)
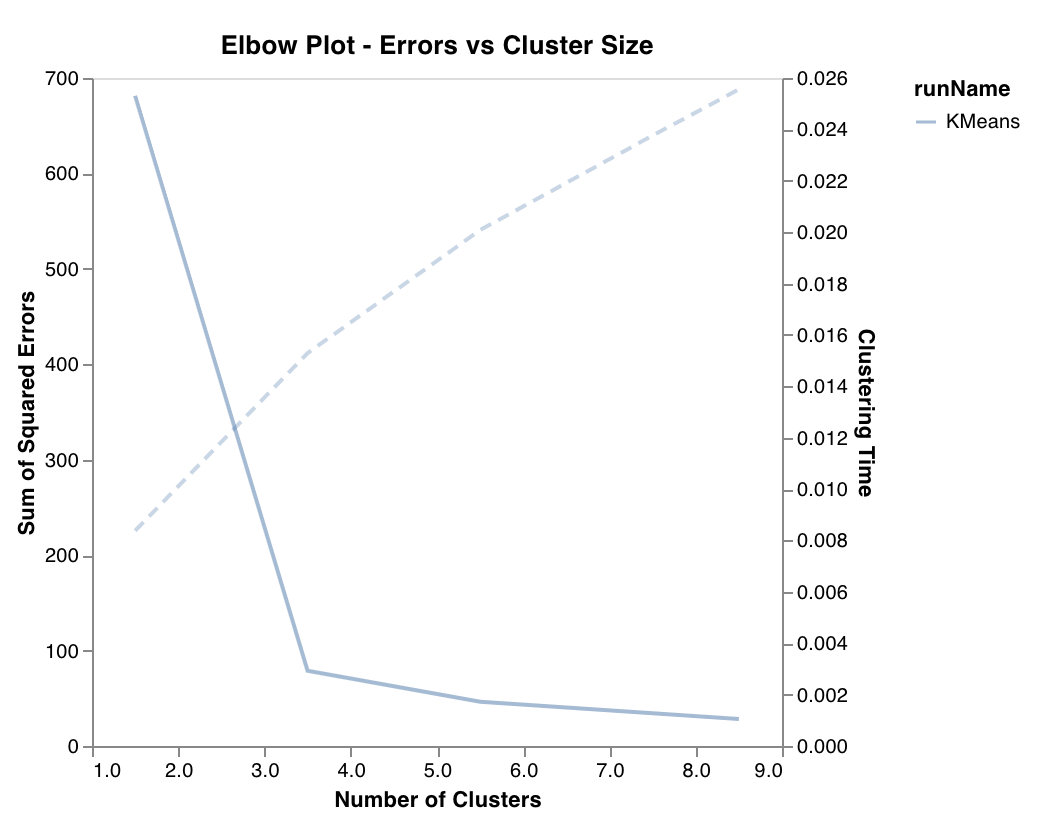
wandb.sklearn.plot_elbow_curve(model, X_train)
- model (clusterer): フィット済みの クラスター 器を指定します。
- X (arr): トレーニングセット の特徴量。
シルエット図 (Silhouette plot)

wandb.sklearn.plot_silhouette(model, X_train, ['spam', 'not spam'])
- model (clusterer): フィット済みの クラスター 器を指定します。
- X (arr): トレーニングセット の特徴量。
- cluster_labels (list): クラスター ラベルの名前。 クラスター インデックスを対応する名前に置き換えることで、プロットを読みやすくします。
外れ値候補プロット (Outlier candidates plot)
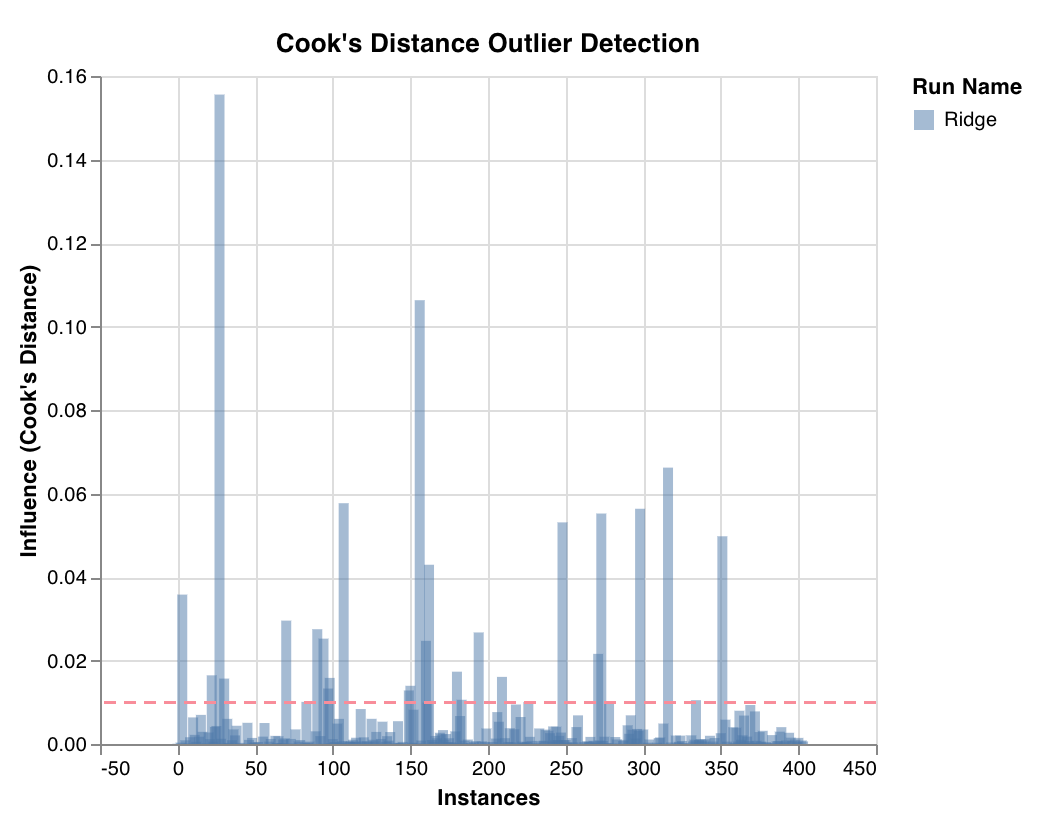
wandb.sklearn.plot_outlier_candidates(model, X, y)
- model (regressor): フィット済みの分類器を指定します。
- X (arr): トレーニングセット の特徴量。
- y (arr): トレーニングセット のラベル。
残差プロット (Residuals plot)
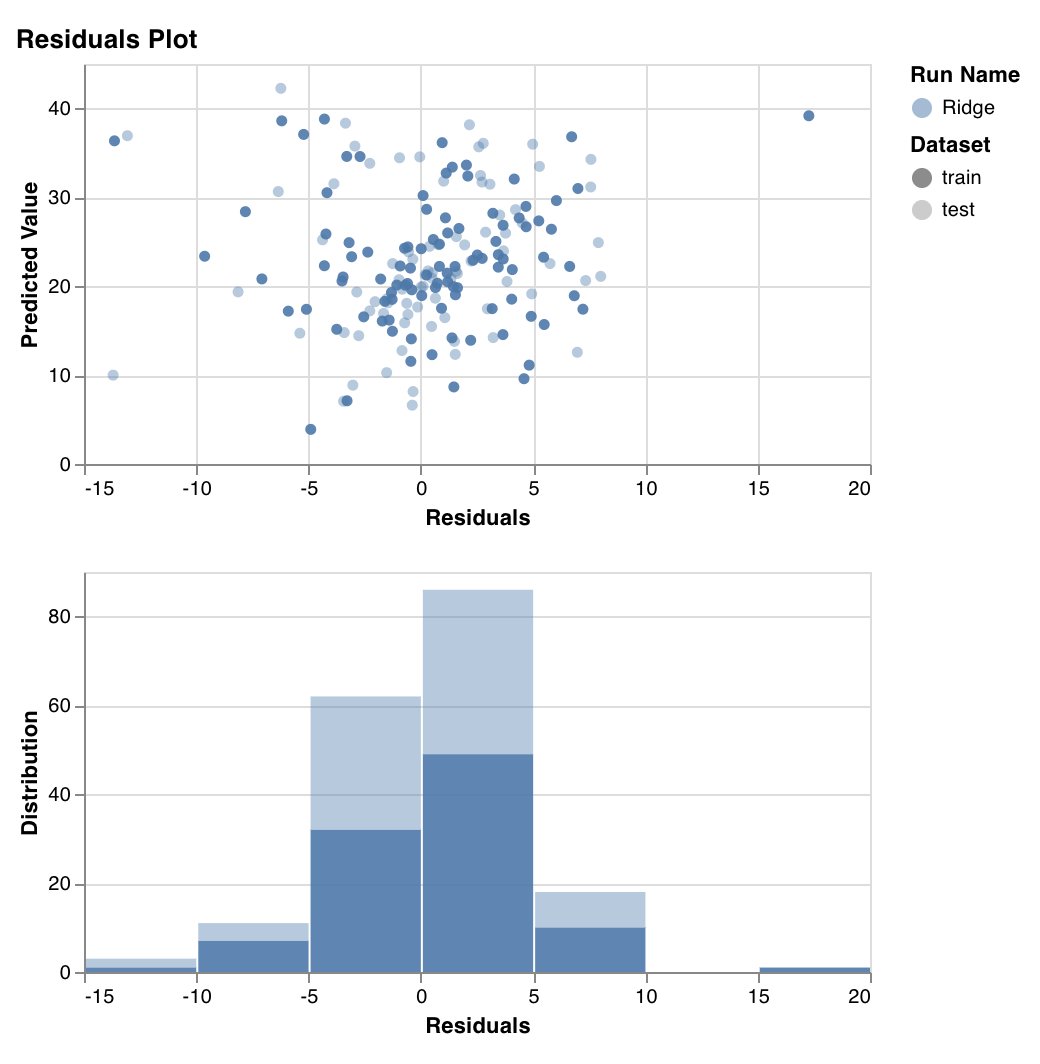
wandb.sklearn.plot_residuals(model, X, y)
- model (regressor): フィット済みの分類器を指定します。
- X (arr): トレーニングセット の特徴量。
- y (arr): トレーニングセット のラベル。
例
- Colab で実行: すぐに始められるシンプルな ノートブック です。