数行のコードで高度なロギングを実現
すぐに実行可能なコードを確認したい場合は、こちらの Google Colab をご覧ください。
はじめに:実験を追跡する
サインアップと API キーの作成
APIキー は、お使いのマシンを W&B に対して認証するために使用されます。ユーザープロファイルから APIキー を生成できます。For a more streamlined approach, create an API key by going directly to User Settings. Copy the newly created API key immediately and save it in a secure location such as a password manager.
- 右上隅にあるユーザープロファイルアイコンをクリックします。
- User Settings を選択し、API Keys セクションまでスクロールします。
wandb ライブラリのインストールとログイン
ローカルに wandb ライブラリをインストールしてログインするには:
- Command Line
- Python
- Python notebook
-
WANDB_API_KEY環境変数 を APIキー に設定します。 -
wandbライブラリをインストールしてログインします。
プロジェクトに名前を付ける
W&B の Projects は、関連する Runs からログ記録されたすべてのチャート、データ、モデルが保存される場所です。プロジェクトに名前を付けることで、作業を整理し、1つのプロジェクトに関するすべての情報を1か所にまとめて管理できます。 Run をプロジェクトに追加するには、環境変数WANDB_PROJECT にプロジェクト名を設定するだけです。WandbCallback がこのプロジェクト名の環境変数を読み取り、Run のセットアップ時に使用します。
- Command Line
- Python
- Python notebook
プロジェクト名は必ず
Trainer を初期化する 前 に設定してください。huggingface になります。
トレーニング Run を W&B にログ記録する
Trainer のトレーニング引数を定義する際、コード内またはコマンドラインから 最も重要なステップ は、W&B でのロギングを有効にするために report_to を "wandb" に設定することです。
TrainingArguments 内の logging_steps 引数により、トレーニング中にメトリクスを W&B にプッシュする頻度を制御できます。また、run_name 引数を使用して、W&B 上のトレーニング Run に名前を付けることも可能です。
設定はこれだけです。これで、トレーニング中の損失、評価メトリクス、モデルのトポロジー、勾配が W&B にログ記録されるようになります。
- Command Line
- Python
TensorFlow をお使いですか? PyTorch の
Trainer を TensorFlow 用の TFTrainer に置き換えるだけで同様に動作します。モデルのチェックポイント保存を有効にする
Artifacts を使用すると、最大 100GB までのモデルやデータセットを無料で保存でき、W&B の Registry を利用できるようになります。Registry を使えば、モデルの登録、探索、評価、ステージングへの準備、プロダクション環境へのデプロイが可能になります。 Hugging Face のモデルチェックポイントを Artifacts にログ記録するには、環境変数WANDB_LOG_MODEL を以下のいずれかに設定します:
checkpoint:TrainingArgumentsのargs.save_stepsごとにチェックポイントをアップロードします。end:load_best_model_at_endも設定されている場合、トレーニング終了時にモデルをアップロードします。false: モデルをアップロードしません。
- Command Line
- Python
- Python notebook
Trainer は、モデルを W&B プロジェクトにアップロードします。ログ記録されたモデルチェックポイントは Artifacts UI から確認でき、完全な モデルリネージ も含まれます(UI でのモデルチェックポイントの例は こちら で確認できます)。
デフォルトでは、
WANDB_LOG_MODEL が end に設定されている場合は model-{run_id}、checkpoint に設定されている場合は checkpoint-{run_id} という名前で W&B Artifacts に保存されます。
ただし、TrainingArguments で run_name を渡した場合、モデルは model-{run_name} または checkpoint-{run_name} として保存されます。W&B Registry
チェックポイントを Artifacts にログ記録した後は、最良のモデルチェックポイントを登録し、Registry を通じてチーム全体で一元管理できます。Registry を使用すると、タスクごとに最適なモデルを整理し、モデルのライフサイクルを管理し、ML ライフサイクル全体を追跡・監査し、ダウンストリームのアクションを オートメーション 化できます。 モデル Artifact のリンク方法については、Registry を参照してください。トレーニング中の評価出力の可視化
トレーニング中や評価中のモデル出力を可視化することは、モデルがどのように学習しているかを真に理解するために不可欠です。 Transformers Trainer のコールバックシステムを使用すると、モデルのテキスト生成出力やその他の予測結果などの追加データを W&B Tables にログ記録できます。 トレーニング中の評価出力を W&B テーブルにログ記録する方法の完全なガイドについては、以下の カスタムロギングセクション を参照してください。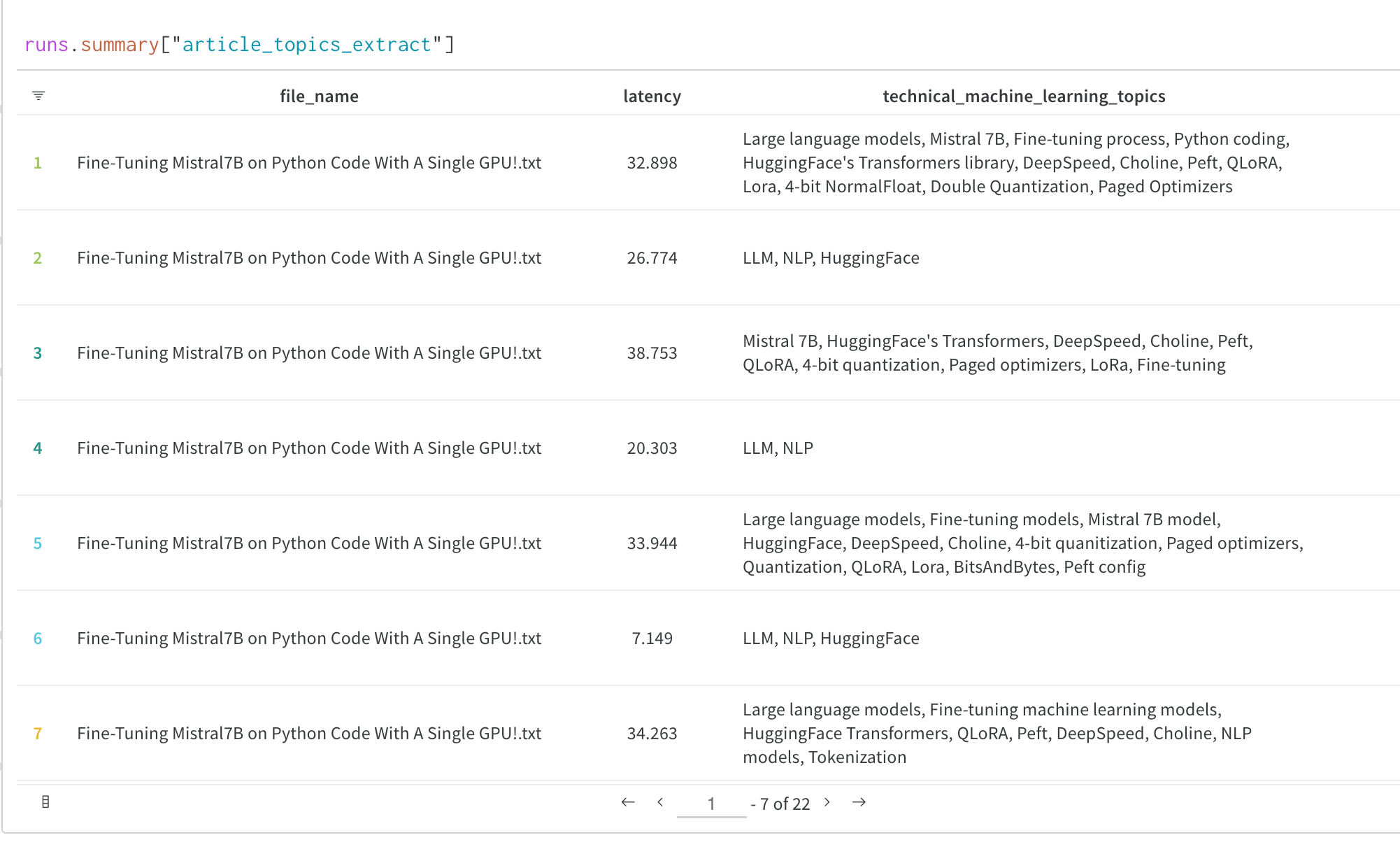
W&B Run の終了(ノートブックのみ)
トレーニングが Python スクリプトにカプセル化されている場合、W&B Run はスクリプトの終了とともに完了します。 Jupyter や Google Colab ノートブックを使用している場合は、run.finish() を呼び出してトレーニングの終了を明示的に伝える必要があります。
結果の可視化
トレーニング結果をログ記録した後は、W&B Dashboard で動的に結果を探索できます。数十の Run を一度に比較したり、興味深い発見をズームアップしたり、柔軟でインタラクティブな可視化機能を使って複雑なデータから洞察を引き出したりすることが簡単にできます。高度な機能と FAQ
最良のモデルを保存するには?
load_best_model_at_end=True を含む TrainingArguments を Trainer に渡すと、W&B は最もパフォーマンスの高いモデルチェックポイントを Artifacts に保存します。
モデルチェックポイントを Artifacts として保存すると、それらを Registry にプロモートできます。Registry では以下が可能です:
- ML タスクごとに最適なモデルバージョンを整理。
- モデルを一元管理し、チームで共有。
- プロダクション用のモデルをステージング、またはさらなる評価のためにブックマーク。
- ダウンストリームの CI/CD プロセスをトリガー。
保存したモデルをロードするには?
WANDB_LOG_MODEL を使用してモデルを W&B Artifacts に保存した場合、追加のトレーニングや推論実行のためにモデルの重みをダウンロードできます。以前使用したものと同じ Hugging Face アーキテクチャーにそれらをロードし直すだけです。
チェックポイントからトレーニングを再開するには?
WANDB_LOG_MODEL='checkpoint' を設定していた場合、model_dir を TrainingArguments の model_name_or_path 引数として使用し、Trainer に resume_from_checkpoint=True を渡すことでトレーニングを再開できます。
トレーニング中に評価サンプルをログ記録・表示するには
TransformersTrainer を介した W&B へのロギングは、Transformers ライブラリ内の WandbCallback によって処理されます。Hugging Face のロギングをカスタマイズする必要がある場合は、WandbCallback をサブクラス化し、Trainer クラスのメソッドを活用する機能を追加することで、このコールバックを変更できます。
以下は、この新しいコールバックを HF Trainer に追加する一般的なパターンです。さらにその下には、評価出力を W&B テーブルにログ記録するための完全なコード例があります。
トレーニング中に評価サンプルを表示する
以下のセクションでは、WandbCallback をカスタマイズして、トレーニング中にモデルの予測を実行し、評価サンプルを W&B テーブルにログ記録する方法を示します。Trainer コールバックの on_evaluate メソッドを使用して、eval_steps ごとに実行します。
ここでは、トークナイザーを使用してモデル出力から予測とラベルをデコードする decode_predictions 関数を作成しました。
次に、予測とラベルから pandas DataFrame を作成し、DataFrame に epoch 列を追加します。
最後に、DataFrame から wandb.Table を作成し、それを W&B にログ記録します。
さらに、freq エポックごとに予測をログ記録することで、ログの頻度を制御できます。
注意: 通常の WandbCallback とは異なり、このカスタムコールバックは Trainer の初期化中ではなく、Trainer がインスタンス化された 後 に追加する必要があります。
これは、初期化時に Trainer インスタンスがコールバックに渡されるためです。
利用可能な追加の W&B 設定は?
環境変数を設定することで、Trainer でログ記録される内容をさらに詳細に設定できます。W&B 環境変数の全リストは こちらで見ることができます。
| 環境変数 | 用途 |
|---|---|
WANDB_PROJECT | プロジェクトに名前を付けます(デフォルトは huggingface) |
WANDB_LOG_MODEL | モデルチェックポイントを W&B Artifact としてログ記録します(デフォルトは
|
WANDB_WATCH | モデルの勾配、パラメータ、またはその両方をログ記録するか設定します
|
WANDB_DISABLED | ロギングを完全に無効にするには true に設定します(デフォルトは false) |
WANDB_QUIET. | 標準出力に記録されるステートメントを重要なものだけに制限するには true に設定します(デフォルトは false) |
WANDB_SILENT | wandb によって出力されるテキストを非表示にするには true に設定します(デフォルトは false) |
- Command Line
- Notebook
wandb.init をカスタマイズするには?
Trainer が使用する WandbCallback は、Trainer の初期化時にバックグラウンドで wandb.init を呼び出します。あるいは、Trainer を初期化する前に wandb.init を呼び出して手動で Run を設定することもできます。これにより、W&B Run の設定を完全に制御できるようになります。
init に渡す設定の例を以下に示します。wandb.init() の詳細については、wandb.init() リファレンス を参照してください。